Downloaded 53 times

















,
maxWaitTimeMillis: Long = 0 ): DataStream[R]
35](https://image.slidesharecdn.com/flinkstreamingberlinmeetup-150227082353-conversion-gate02/75/Flink-Streaming-Berlin-Meetup-35-2048.jpg)
![Scala Interoperability
Seamlessly integrate Flink streaming programs
into scala pipelines
Scala streams implicitly converted to
DataStreams
In the future the output streams will be converted
back to Scala streams
fibs.window(Count of 4).reduce((x,y)=>x+y).print
def fibs():Stream[Int] = {0 #::
fibs.getExecutionEnvironment.scanLeft(1)(_ + _)}
41](https://image.slidesharecdn.com/flinkstreamingberlinmeetup-150227082353-conversion-gate02/75/Flink-Streaming-Berlin-Meetup-41-2048.jpg)

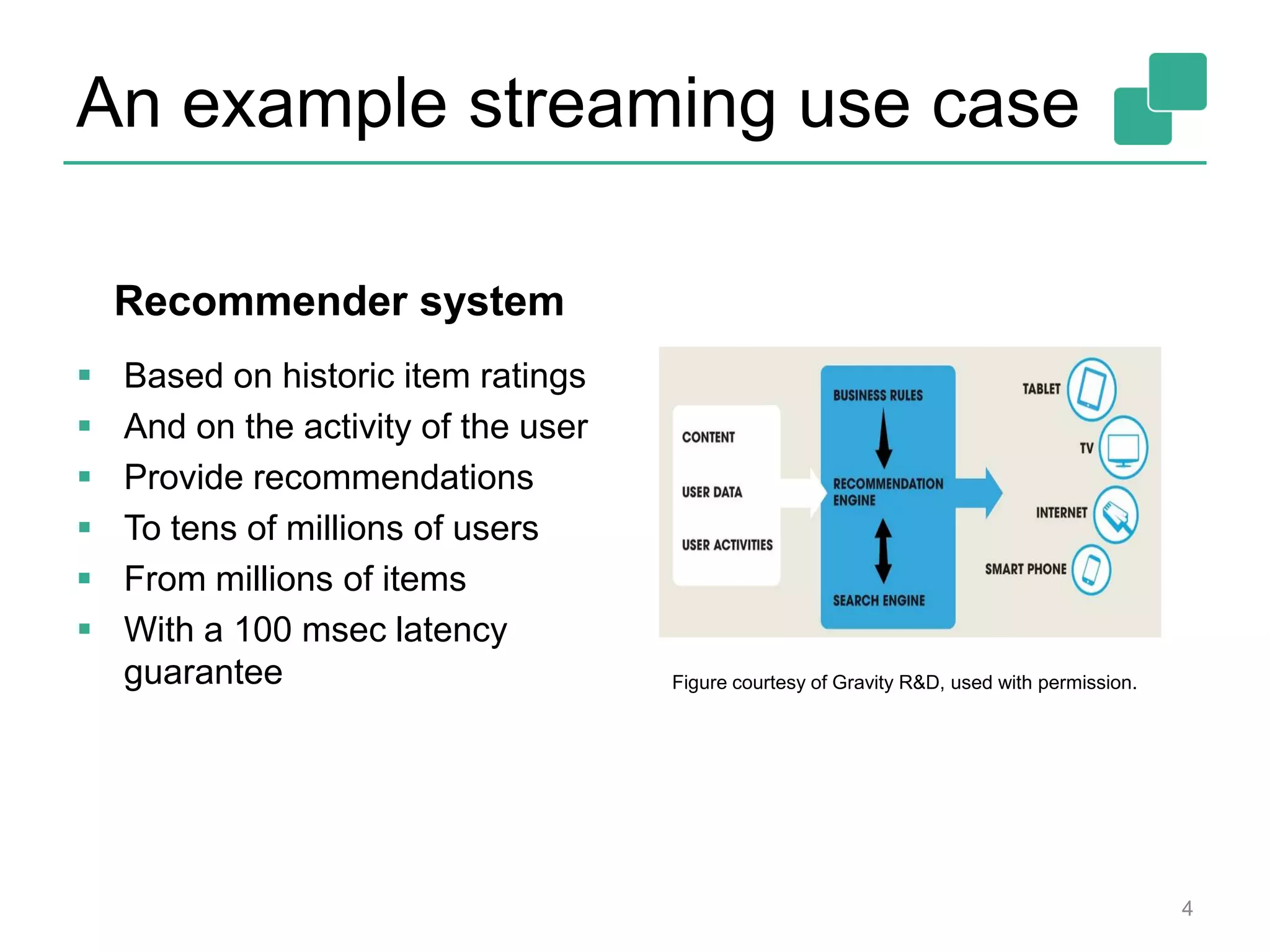
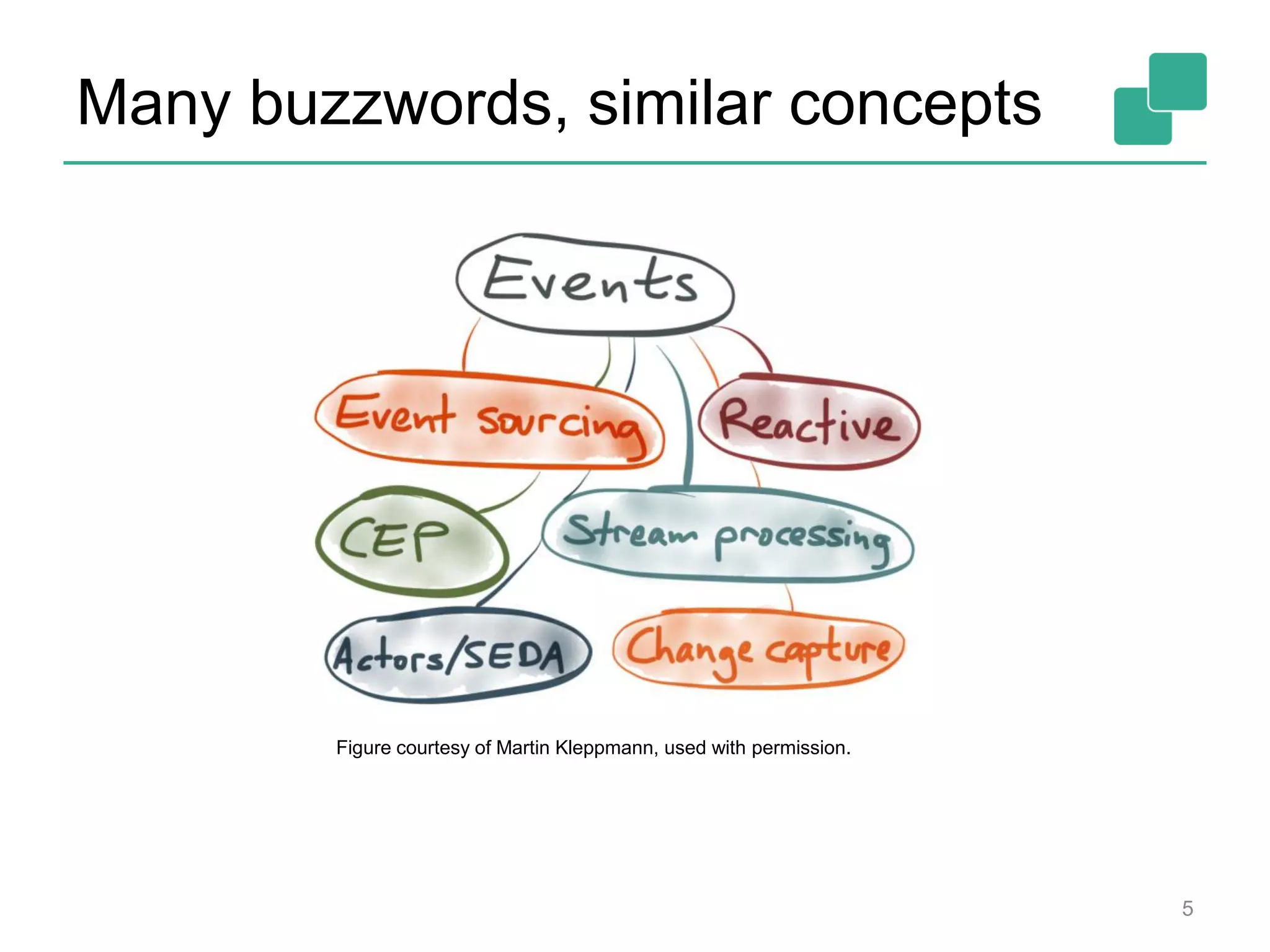
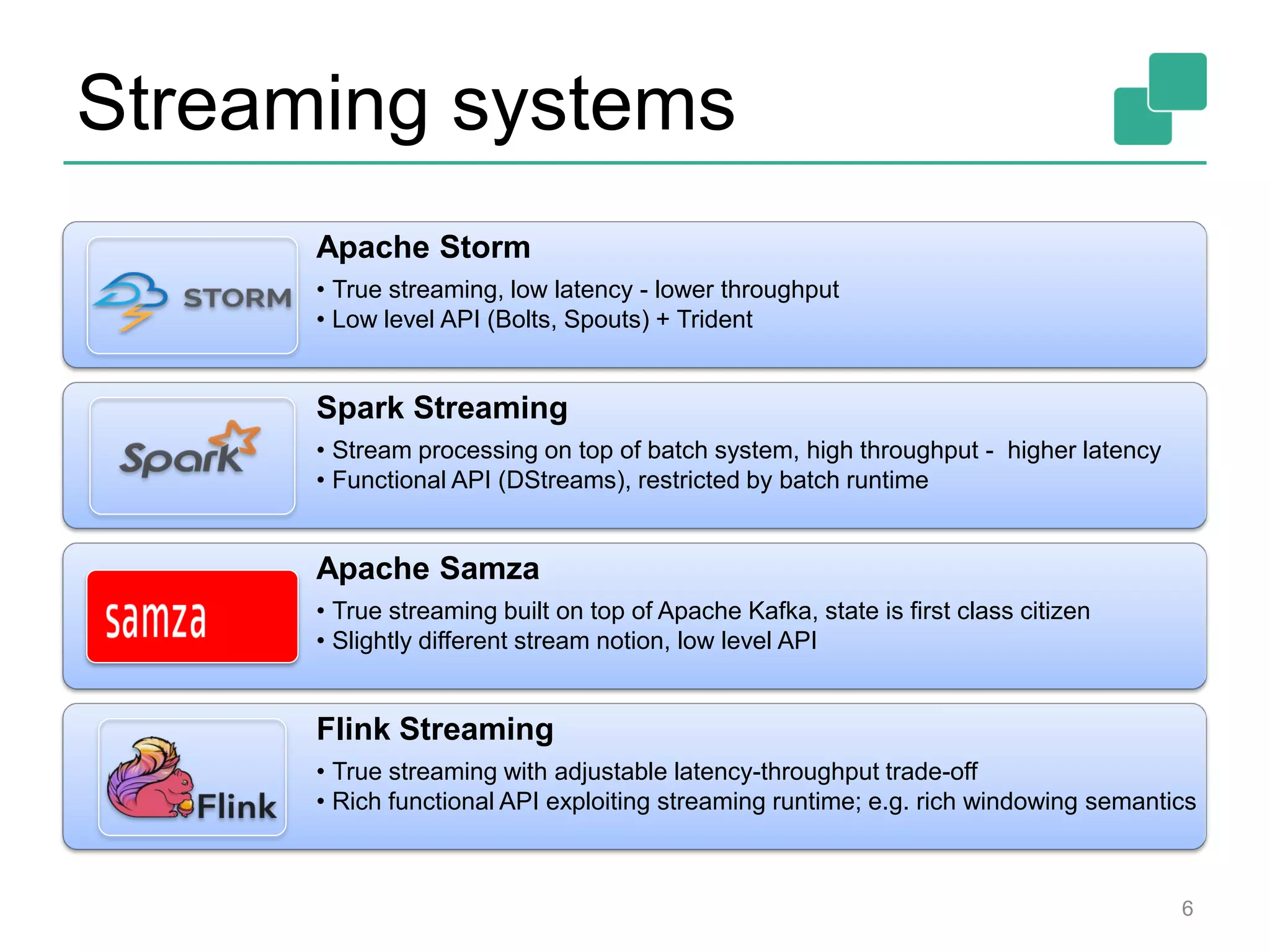
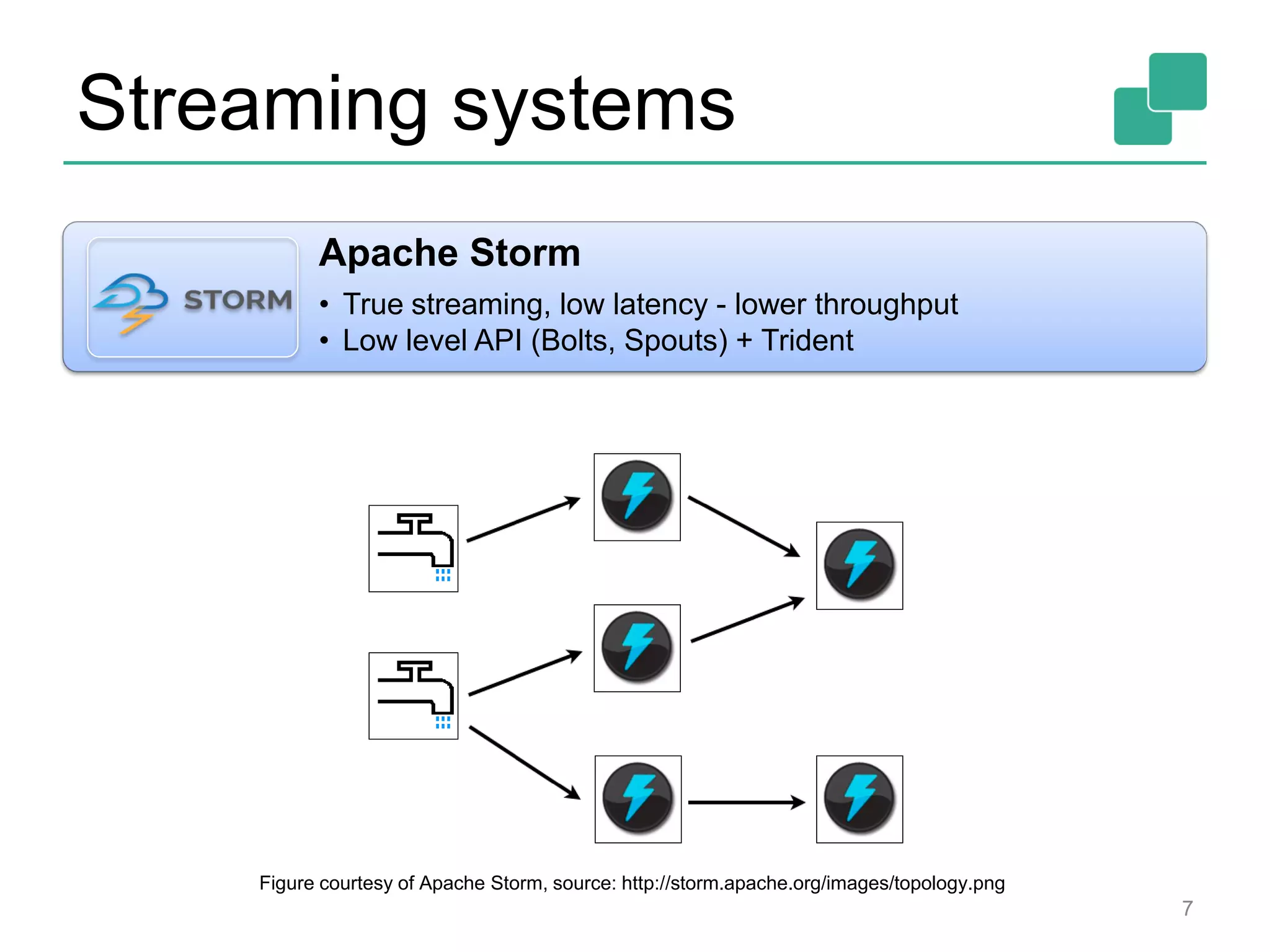
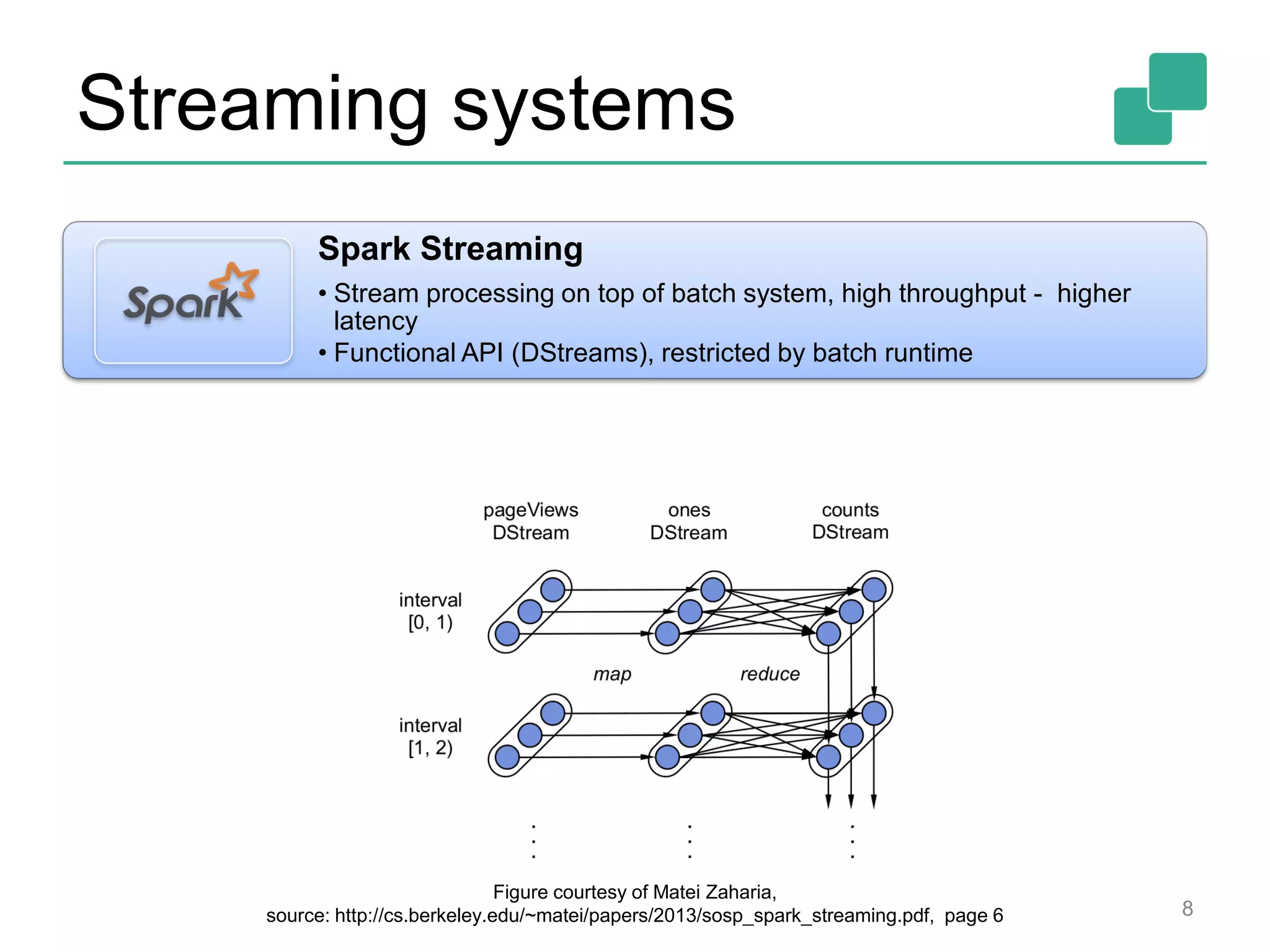
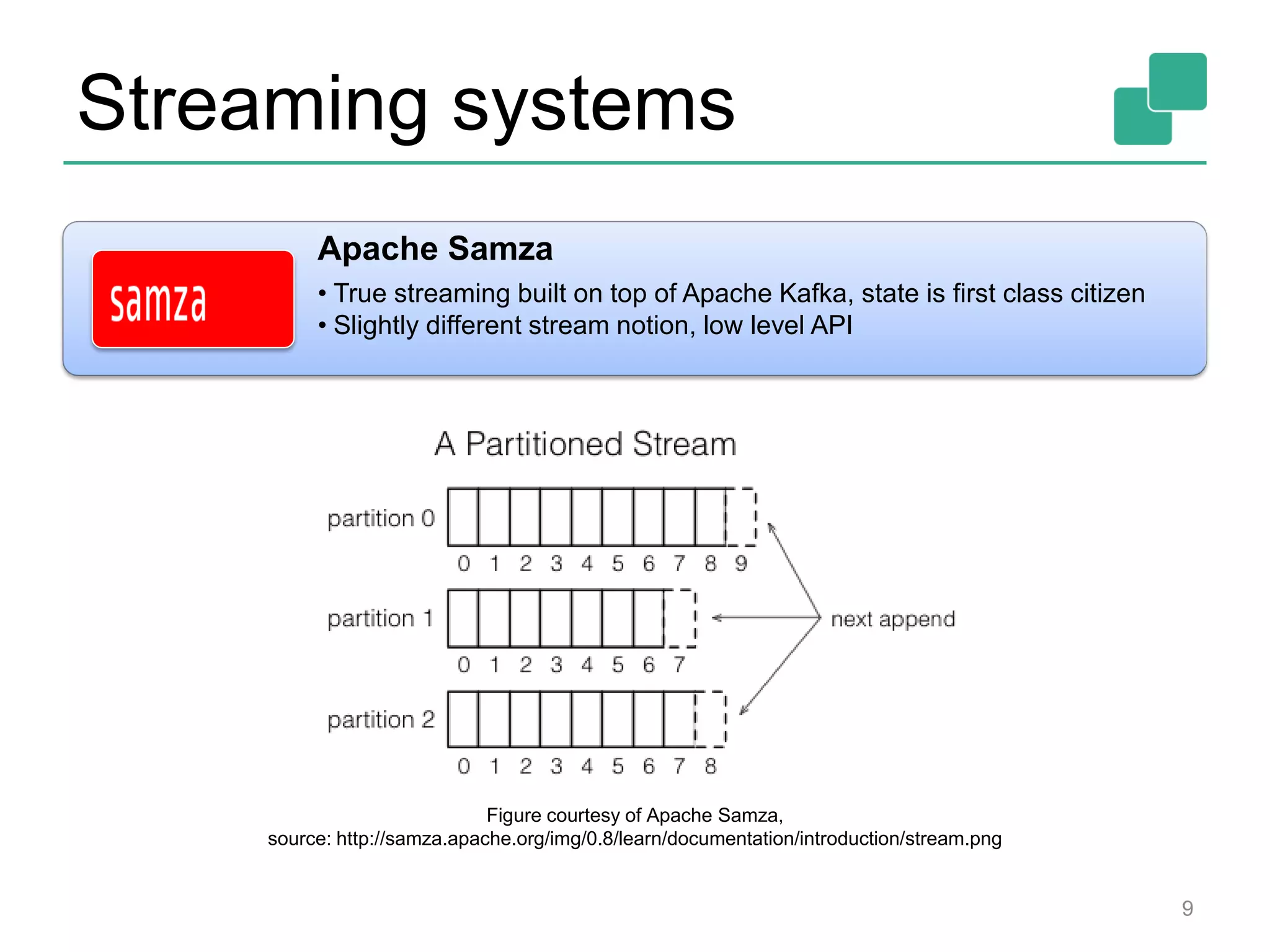
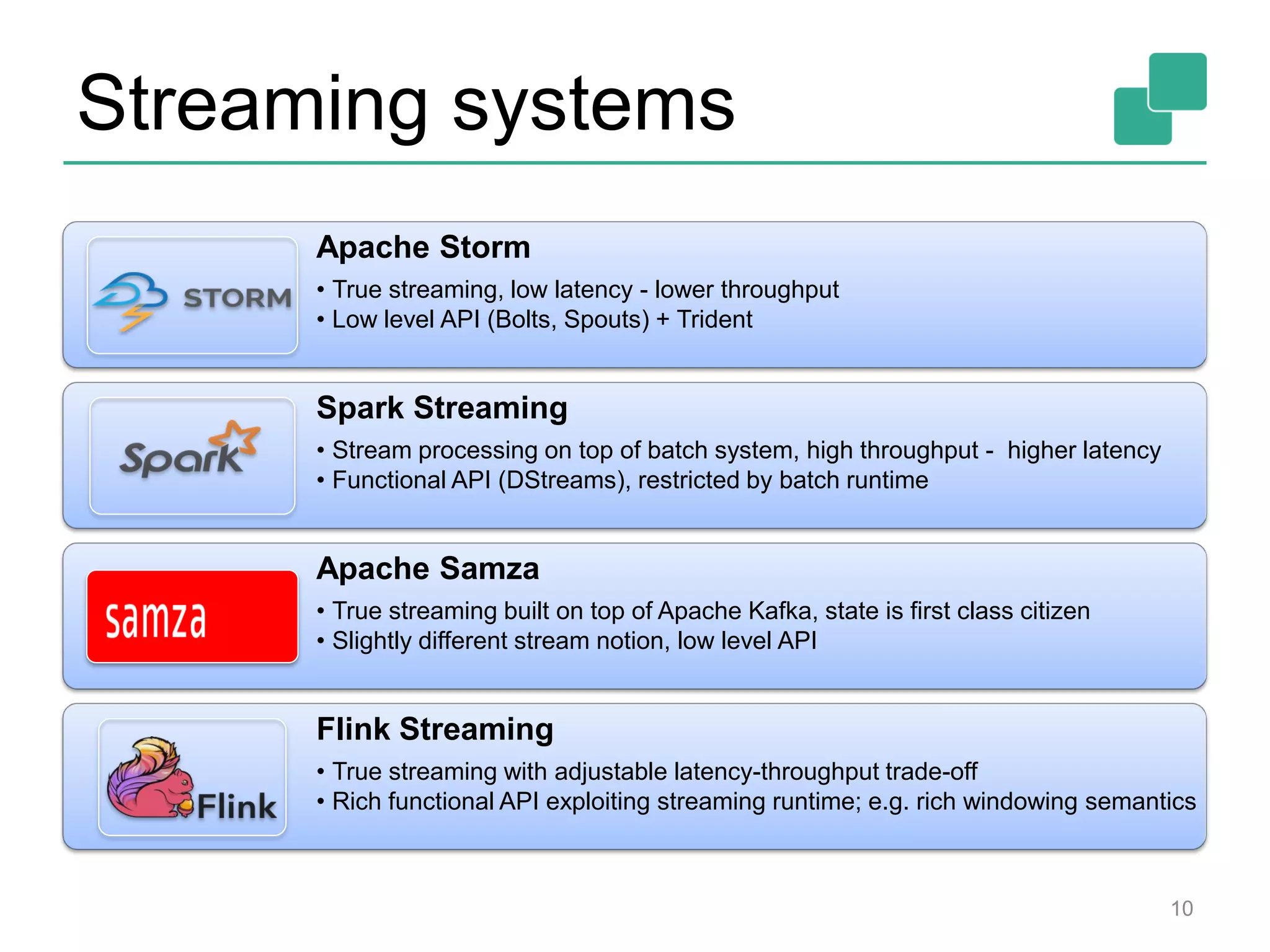
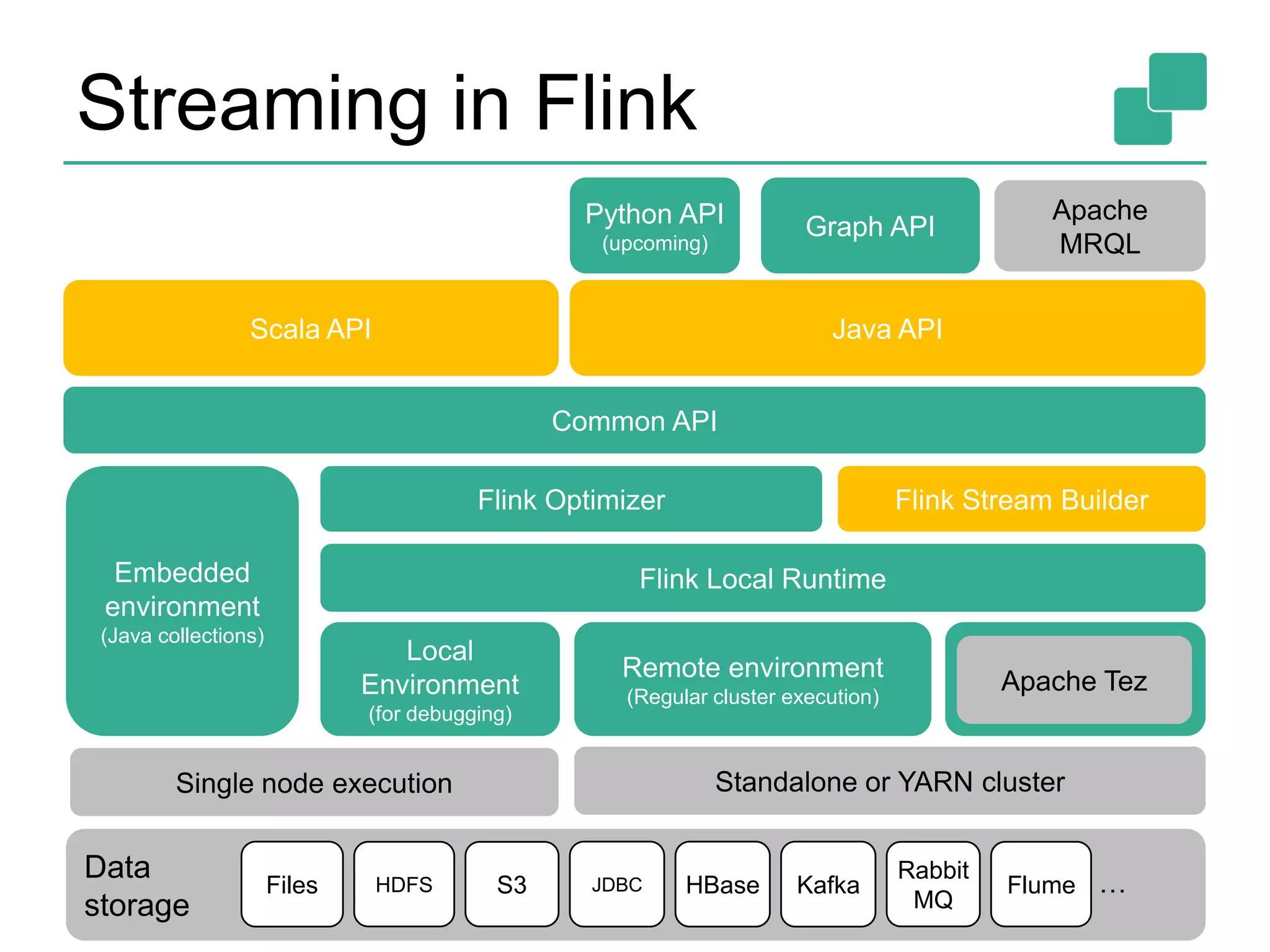
This document provides an overview of streaming systems and Flink streaming. It discusses key concepts in streaming including stream processing, windowing, and fault tolerance. The document also includes examples of using Flink's streaming API, such as reading from multiple inputs, window aggregations, and joining data streams. It summarizes Flink's programming model, roadmap, and performance capabilities. Flink is presented as a next-generation stream processing system that combines a true streaming runtime with expressive APIs and competitive performance.





















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

