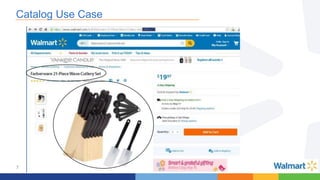
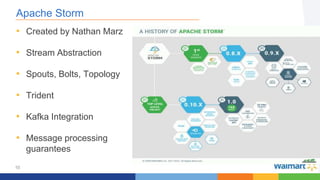
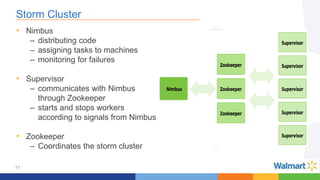
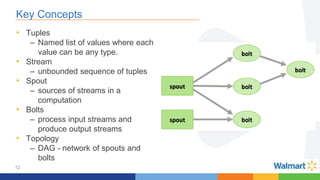
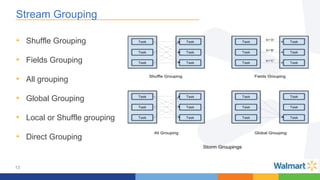
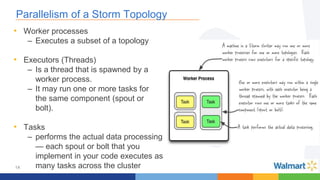
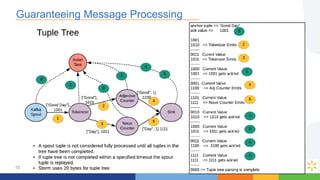
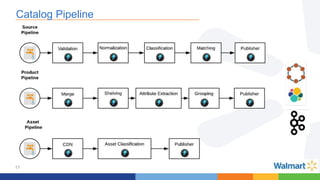
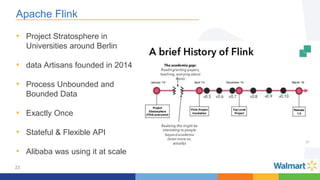
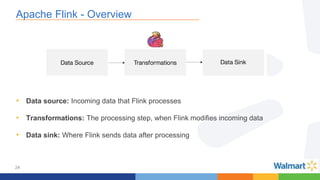
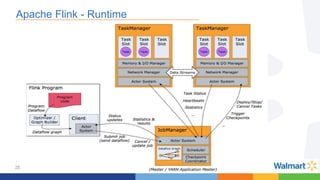
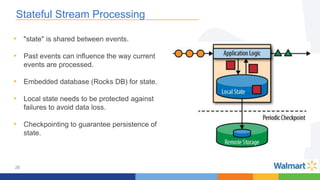
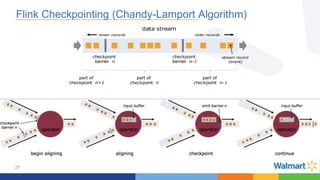
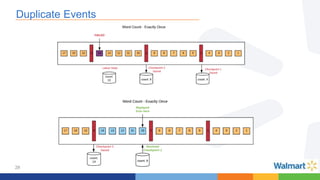
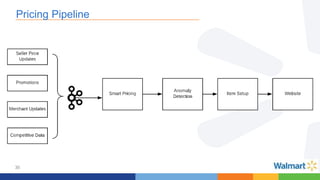
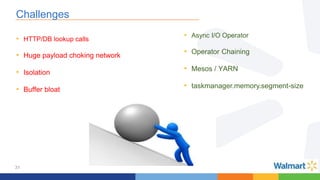
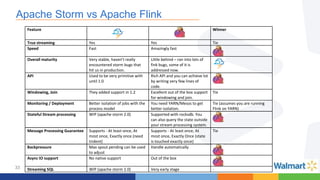
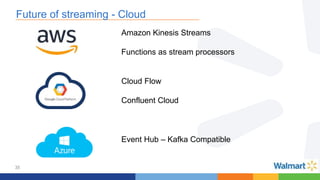
This document compares the Apache Storm and Apache Flink streaming frameworks. Both frameworks can be used to process streaming data in real-time. Storm uses spouts and bolts to define topologies while Flink uses data sources, transformations, and sinks. Flink focuses on exactly-once processing semantics using checkpointing while Storm provides at-least-once guarantees. The document discusses using each framework for catalog and pricing use cases at a large retailer and highlights challenges faced and lessons learned. Overall, both frameworks are mature but Flink is seen as faster with richer APIs and better support for features like windowing, joins, and stateful stream processing.



































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)














