Downloaded 43 times




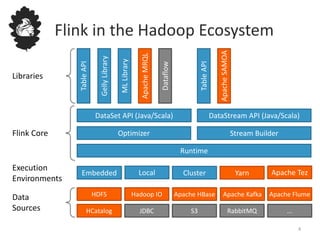





![Counting Words in Batch and Stream
12
case class WordCount (word: String, count: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ")
.map(word => WordCount(word,1))}
.window(Count.of(1000)).every(Count.of(100))
.groupBy("word").sum("count")
.print()
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap {line => line.split(" ")
.map(word => WordCount(word,1))}
.groupBy("word").sum("count")
.print()
DataSet API (batch):
DataStream API (streaming):](https://image.slidesharecdn.com/flink-apachecon-150416143023-conversion-gate01/85/ApacheCon-Apache-Flink-Fast-and-Reliable-Large-Scale-Data-Processing-12-320.jpg)


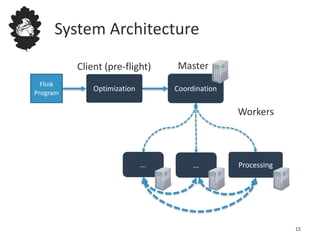



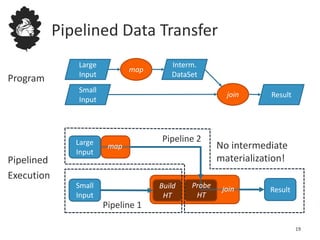




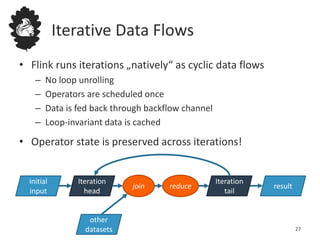









![Data Flow Optimizer
DataSource
orders.tbl
Filter DataSource
lineitem.tbl
Join
Hybrid Hash
buildHT probe
broadcast forward
Combine
Reduce
sort[0,1]
DataSource
orders.tbl
Filter DataSource
lineitem.tbl
Join
Hybrid Hash
buildHT probe
hash-part [0] hash-part [0]
hash-part [0,1]
Reduce
sort[0,1]
Best plan
depends on
relative sizes of
input filespartial sort[0,1]
39](https://image.slidesharecdn.com/flink-apachecon-150416143023-conversion-gate01/85/ApacheCon-Apache-Flink-Fast-and-Reliable-Large-Scale-Data-Processing-39-320.jpg)

This document provides an overview of Apache Flink, a distributed dataflow processing system for large-scale data analytics. Flink supports both stream and batch processing with easy to use APIs in Java and Scala. It focuses on fast and reliable processing at large scales and includes libraries for machine learning, graphs, and SQL-like queries.


















































































