Downloaded 785 times
![Step-By-Step Introduction to
Apache Flink
[Setup, Configure, Run, Tools]
Slim Baltagi @SlimBaltagi
Washington DC Area Apache Flink Meetup
November 19th
, 2015](https://image.slidesharecdn.com/step-by-step-introduction-to-apache-flink-by-slim-baltagi-151120114353-lva1-app6892/85/Step-by-Step-Introduction-to-Apache-Flink-1-320.jpg)









































![49
Run K-Means example
1. Generate Input Data
Flink contains a data generator for K-Means that has the
following arguments (arguments in [] are optional):
-points <num> -k <num clusters> [-output <output-path>] [-
stddev <relative stddev>] [-range <centroid range>] [-seed
<seed>]
Go to the Flink root installation:
$ cd flink-0.10.0
Create a new directory that will contains the data:
$ mkdir kmeans
$ cd kmeans](https://image.slidesharecdn.com/step-by-step-introduction-to-apache-flink-by-slim-baltagi-151120114353-lva1-app6892/85/Step-by-Step-Introduction-to-Apache-Flink-49-320.jpg)
















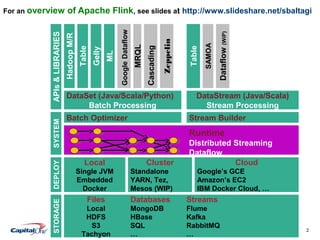
This document provides a comprehensive guide on setting up, configuring, and running Apache Flink, covering environments such as local machines, virtual machines, Docker, standalone clusters, and cloud platforms. It also details the use of Flink tools including the command-line interface, web submission client, and interactive shells. Additionally, resources for further learning and specific configurations for integrating Flink with various data storage systems are included.








![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)










































































![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)