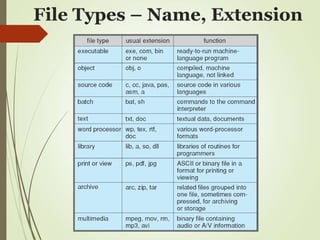
The document discusses file system management and describes key components of file systems including file attributes, operations, access methods, directory structures, and protection. It covers topics like contiguous, linked, and indexed allocation methods; sequential and direct access; path names; and disk scheduling algorithms like FCFS, SSTF, SCAN, C-SCAN, LOOK, and C-LOOK. The objectives are to explain file system functions and interfaces as well as discuss design tradeoffs regarding access methods, sharing, locking, and directory structures.