Downloaded 11 times













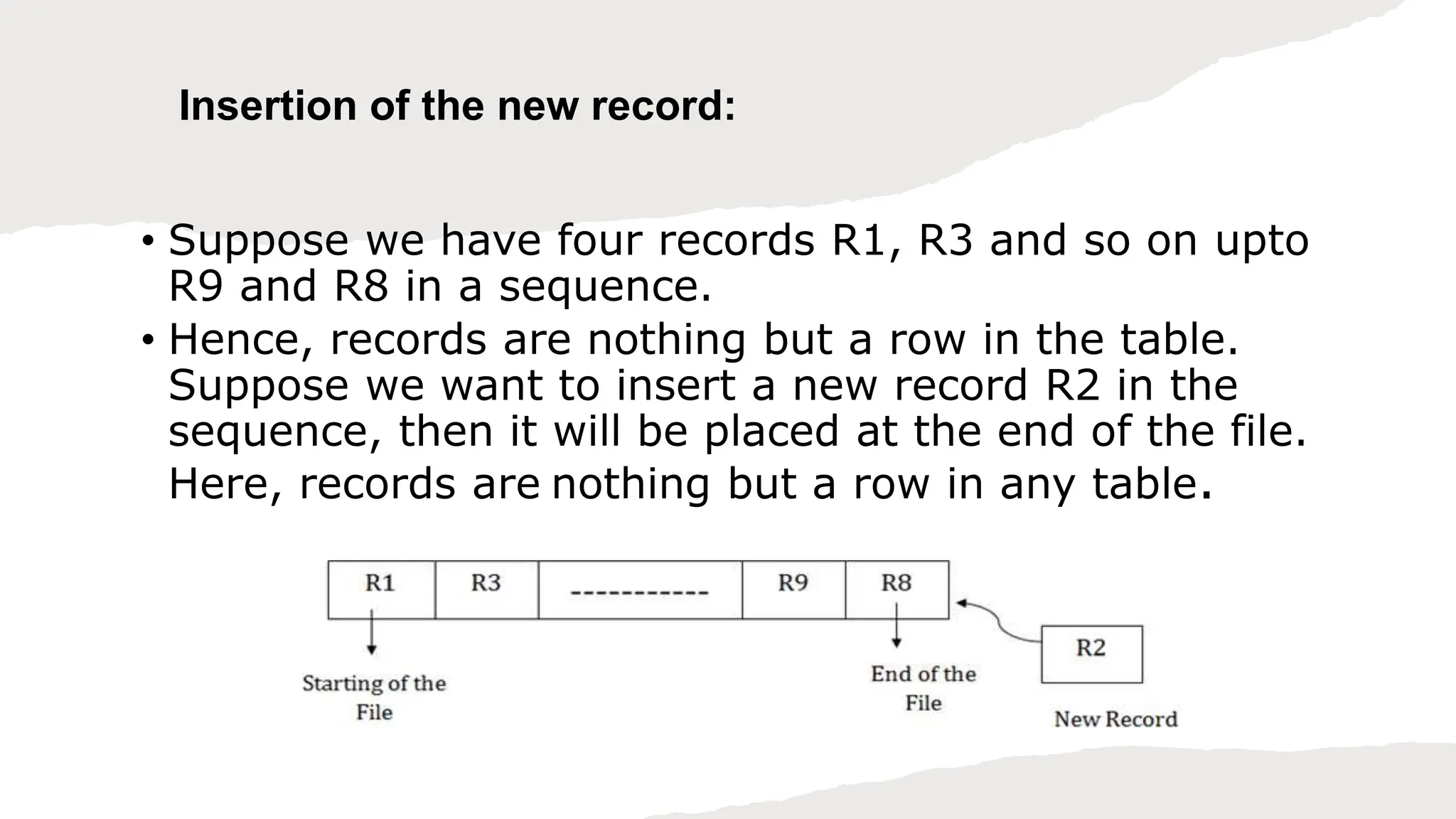



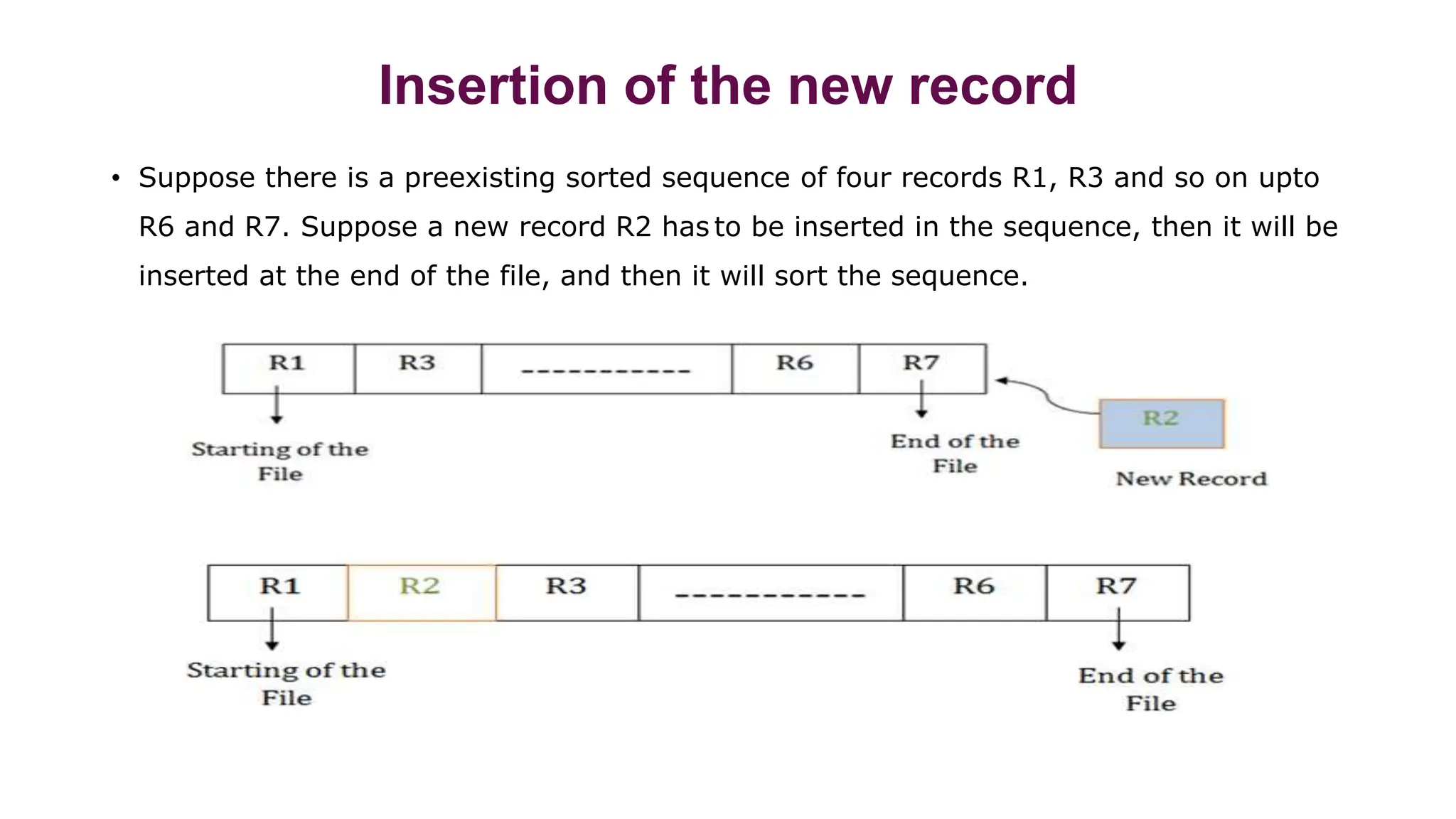





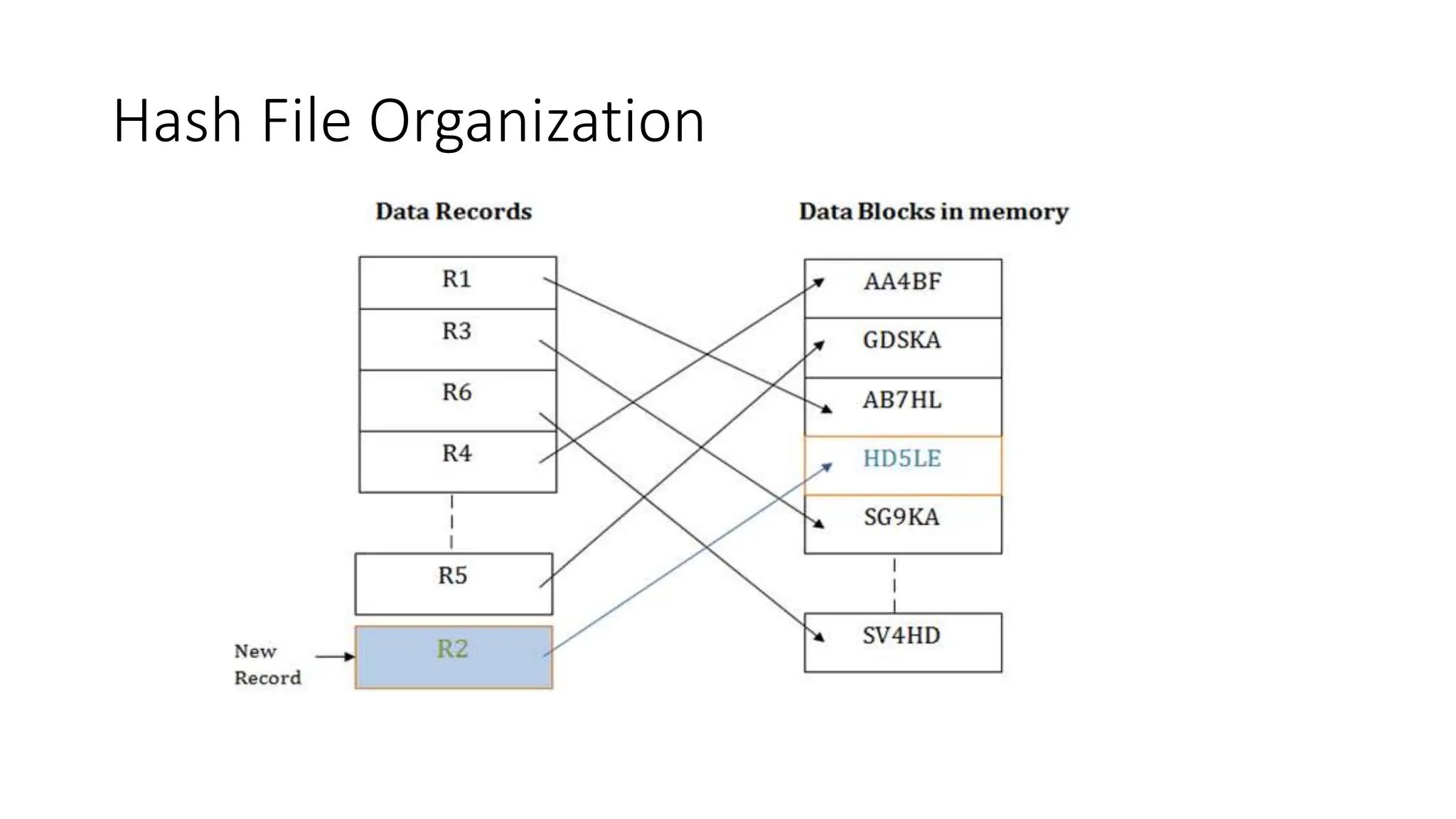

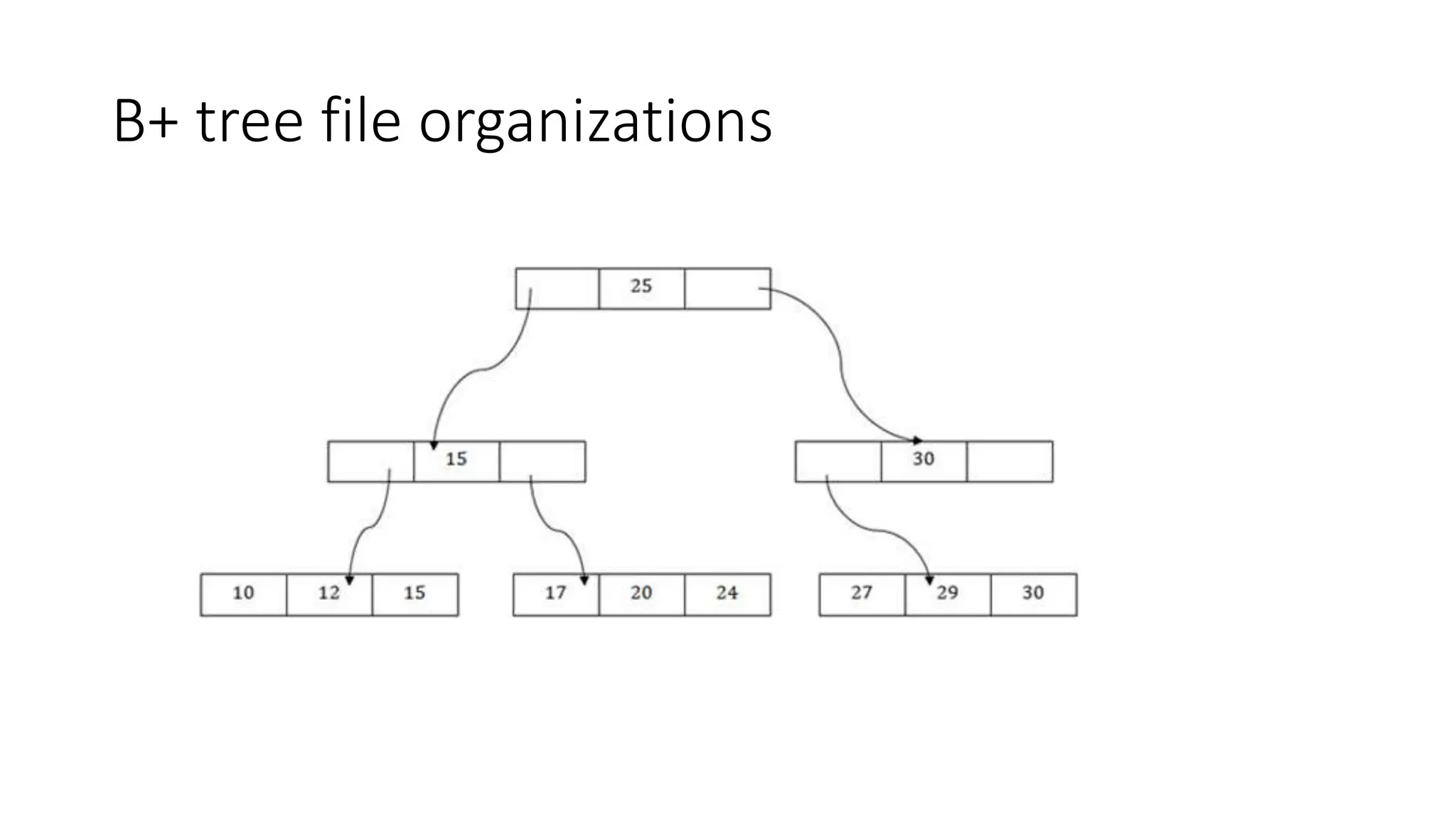





















The document summarizes different file organization techniques used in database management systems. It discusses sequential, direct access, indexed sequential access, and hash file organizations. Sequential access file organization stores records sequentially and allows sequential retrieval but not random access. Direct access organization allows random retrieval by storing records randomly, while indexed sequential access combines both sequential and direct access organizations. Hash file organization uses a hash function to map records to storage locations, allowing direct access via the hash key.



































































