Downloaded 247 times

![Contents
Introduction to Database Management SystemsSahaj Computer Solutions
2
Introduction
Secondary Storage Devices
Buffering of Blocks
Placing File Records on Disk
Operations on Files
Files of Unordered Records [ Heap Files ]
Files of Ordered Records [ Sorted Files ]
Hashing Techniques
Other Organization Techniques](https://image.slidesharecdn.com/chapter4recordstorageandprimaryfileorganization-130729001442-phpapp02/85/Chapter-4-record-storage-and-primary-file-organization-2-320.jpg)



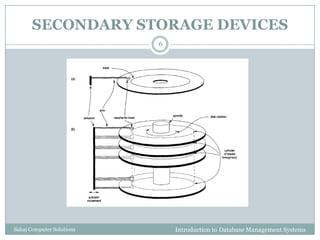
































This document discusses file organization and storage in a database management system. It describes how records are stored on secondary storage devices like disks and tapes. Records can have fixed or variable lengths and are organized into files. The document explains how disks are organized into tracks and sectors and how buffers in memory are used to improve performance when accessing multiple disk blocks.