Downloaded 116 times
















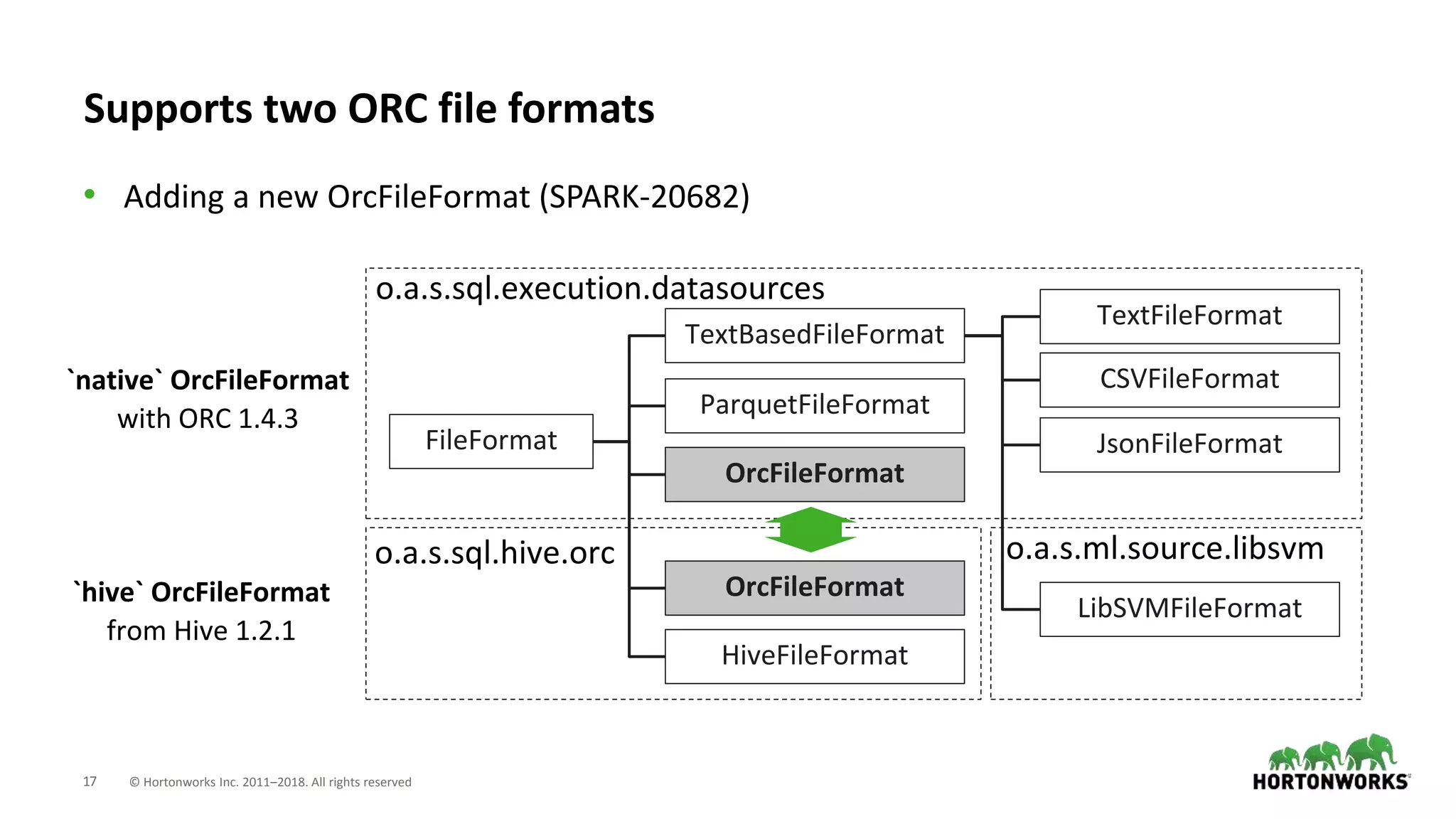

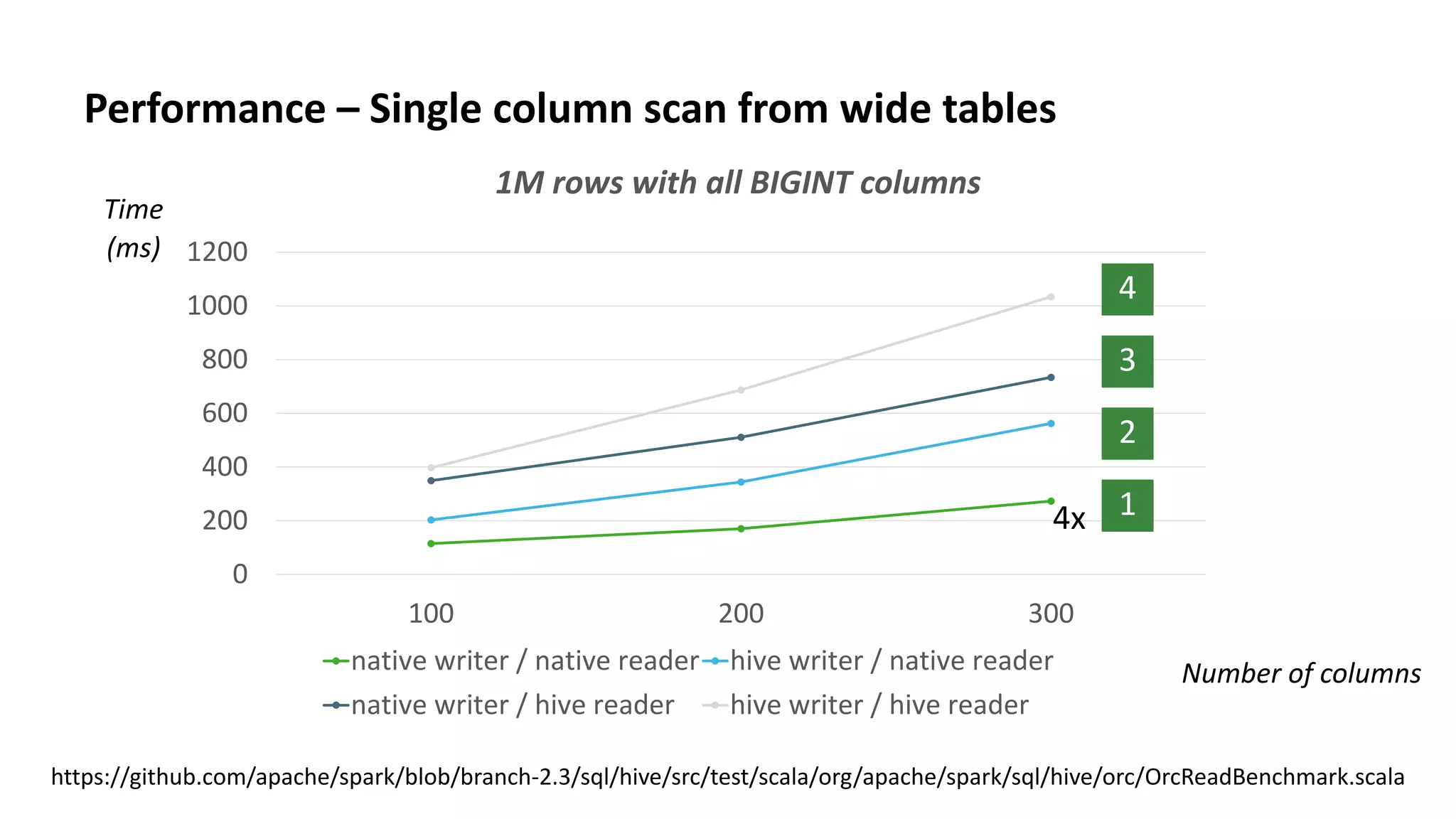

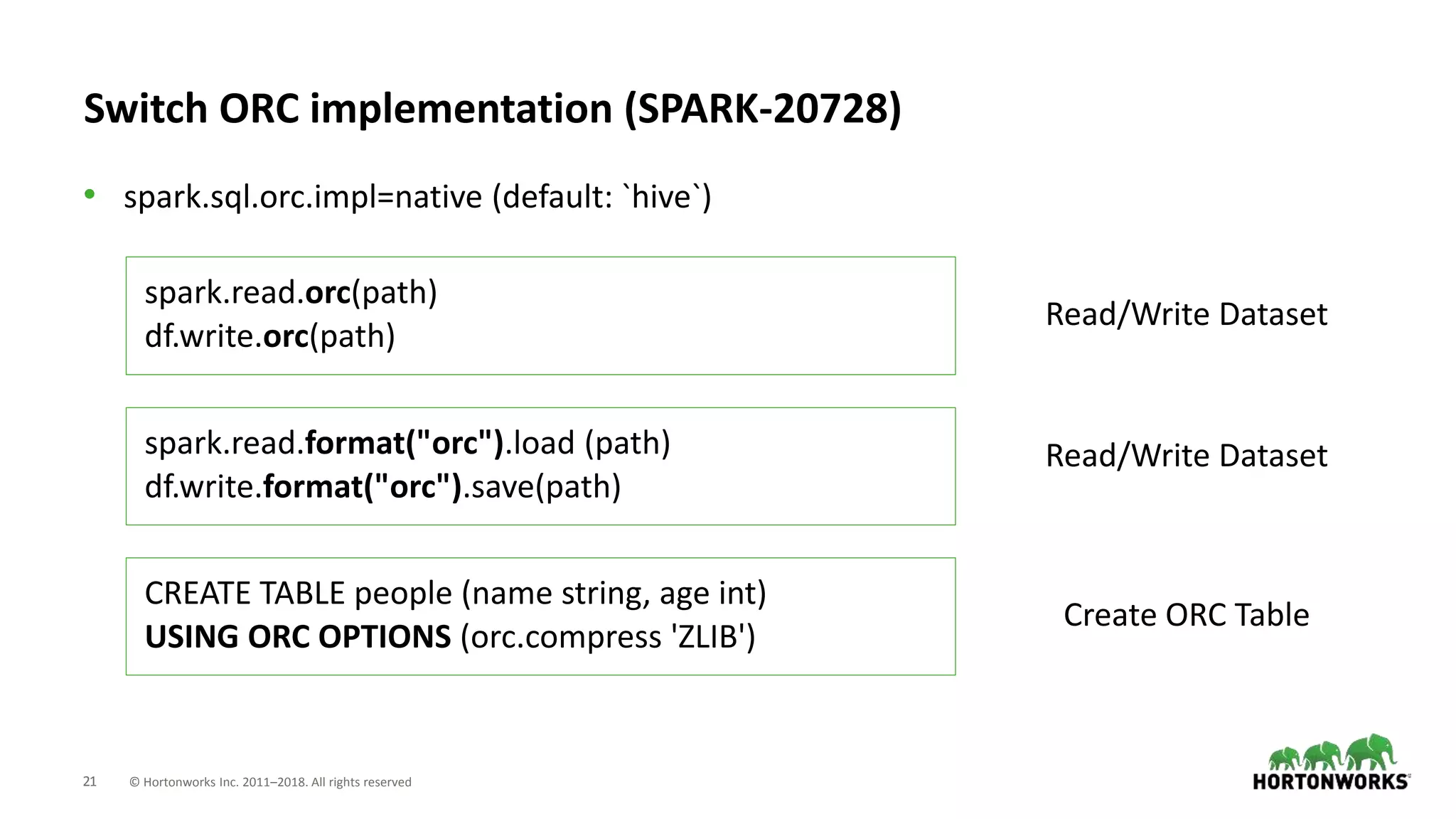

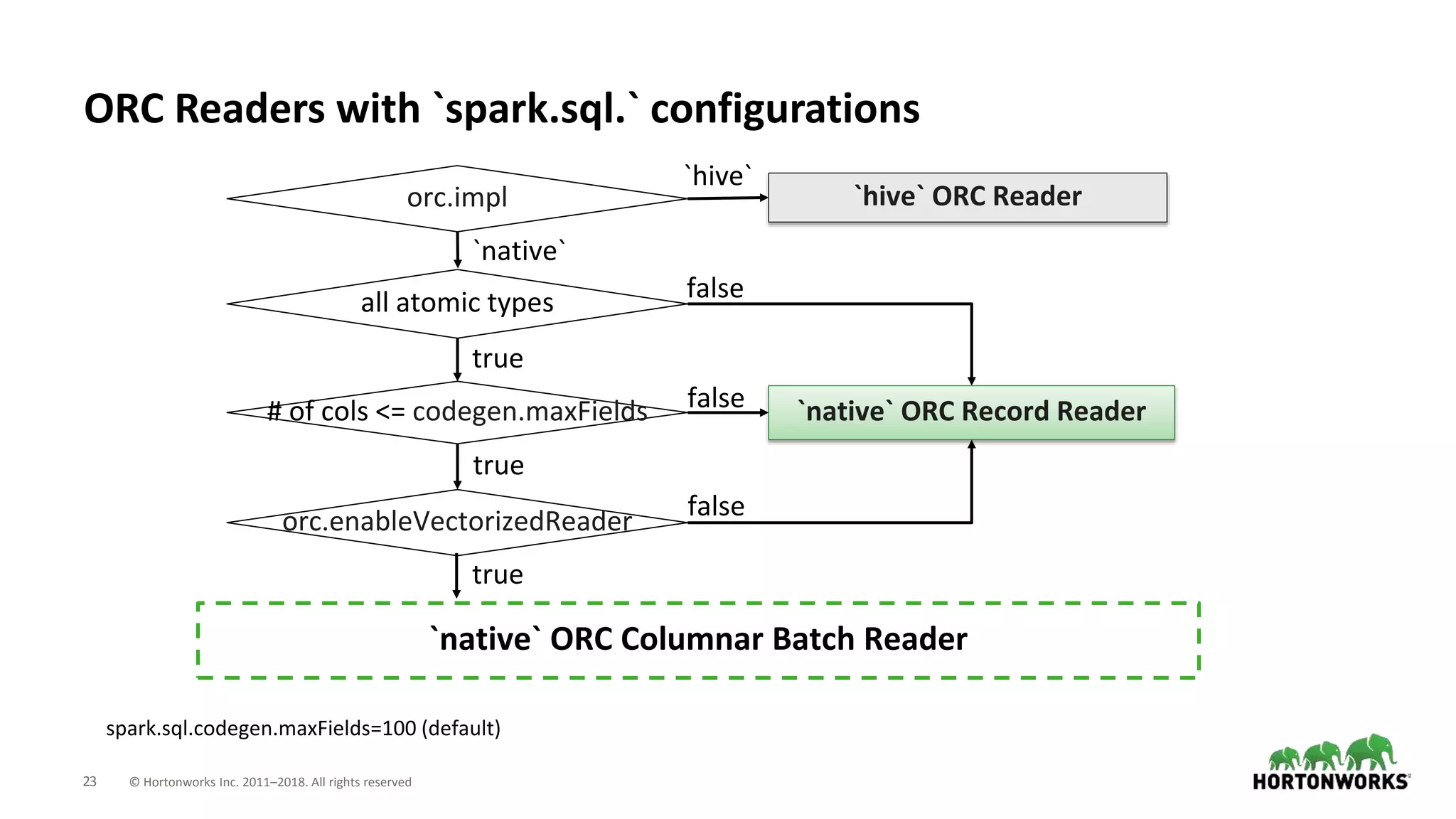
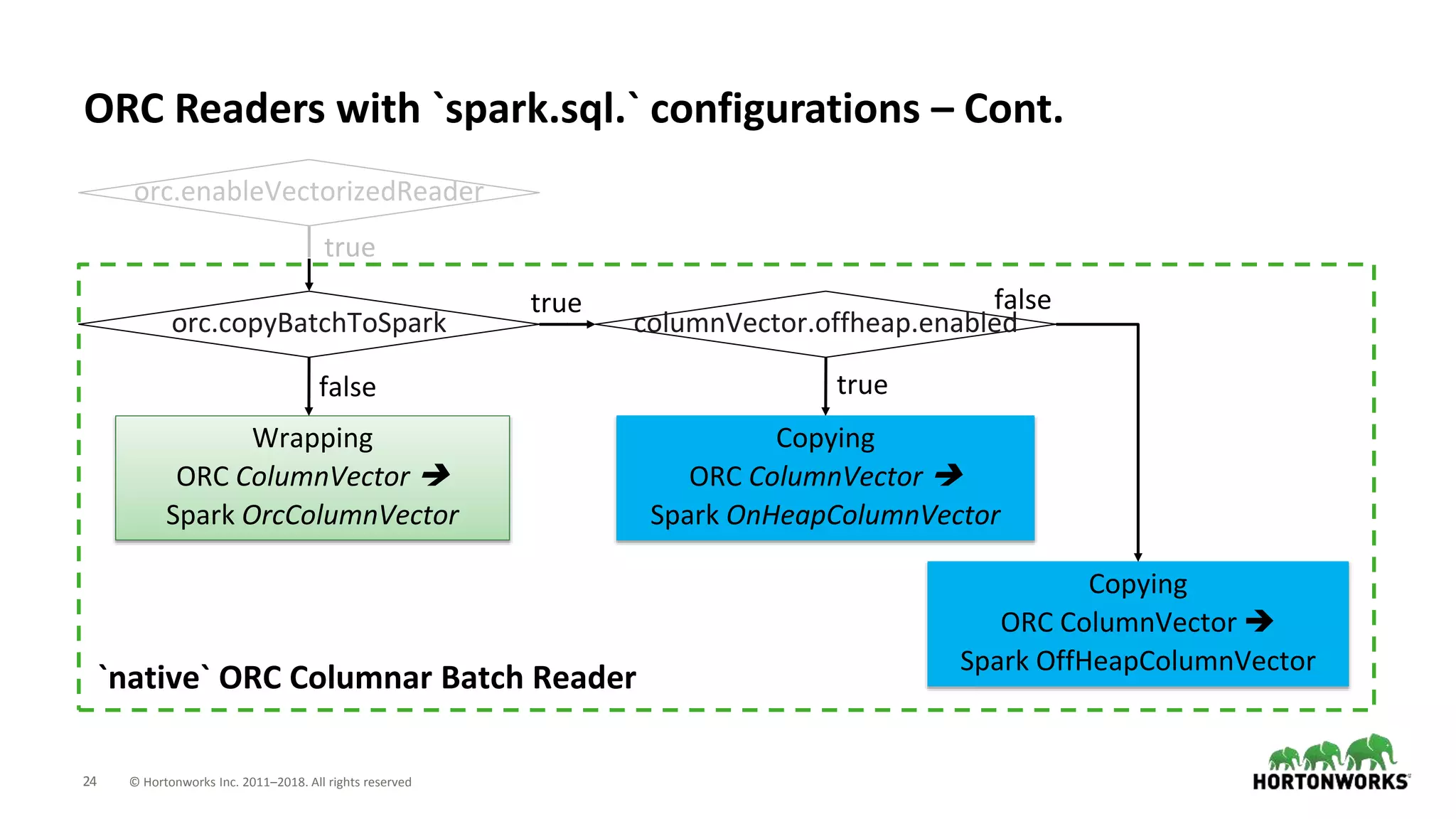


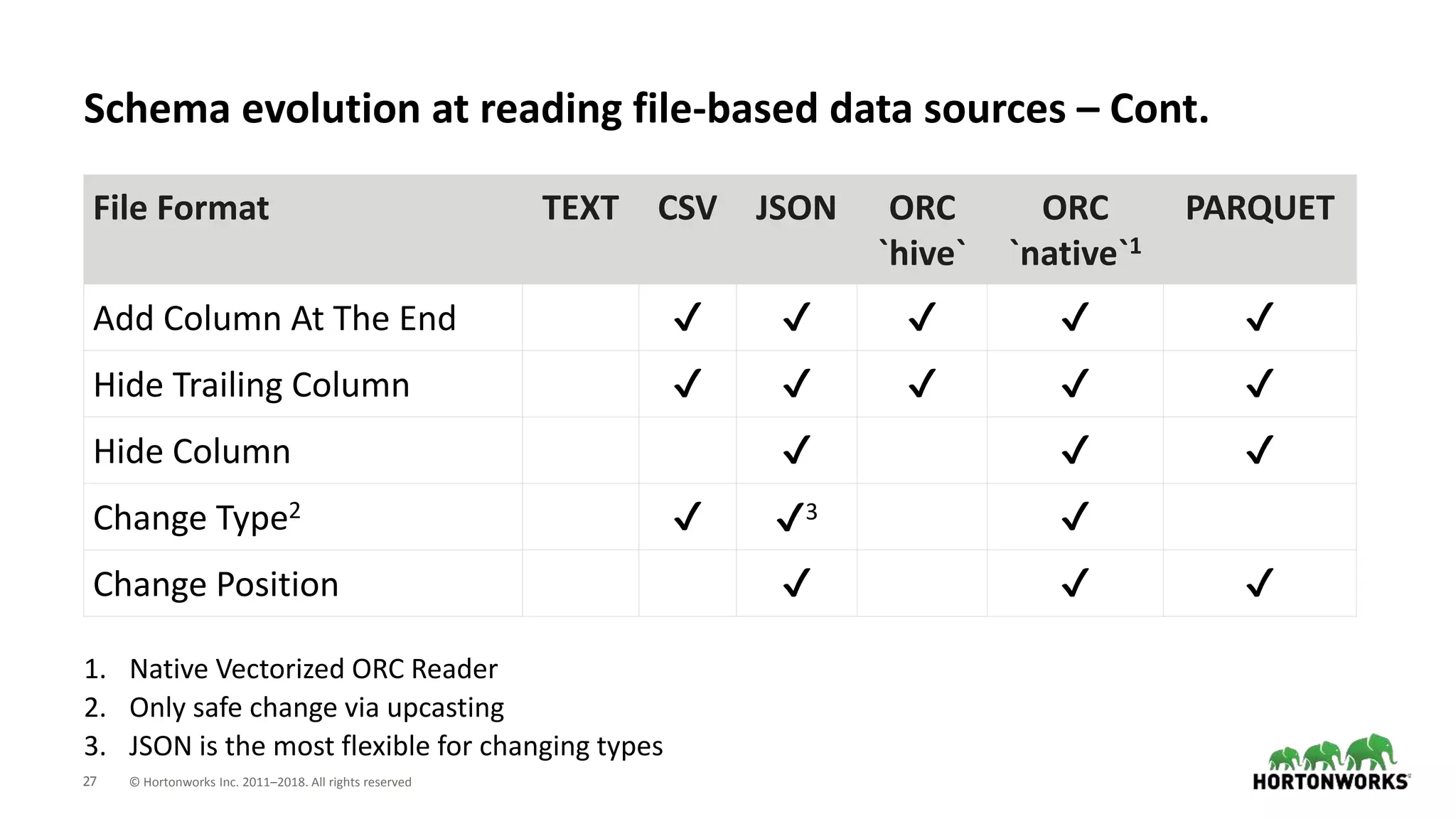




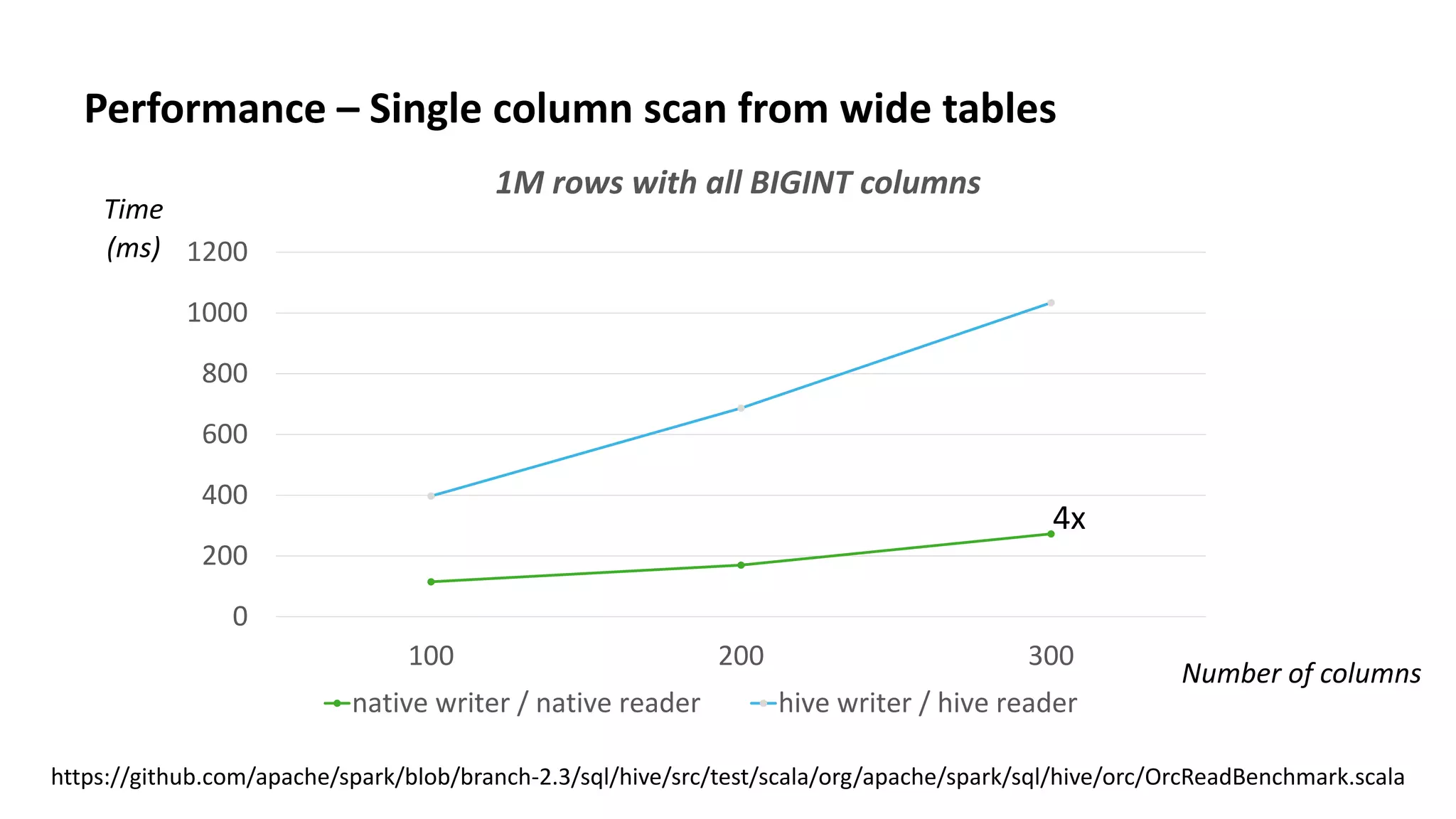
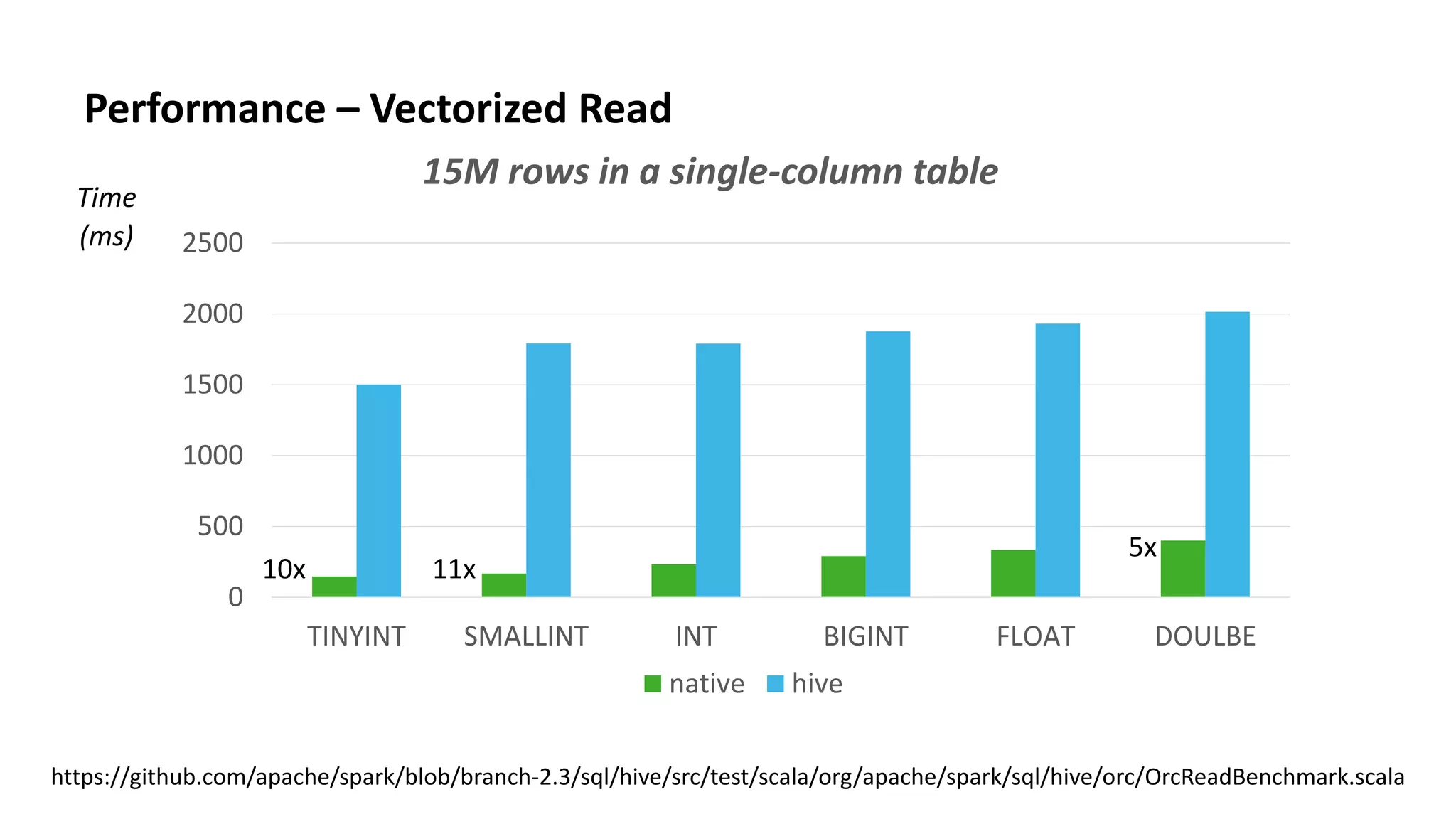
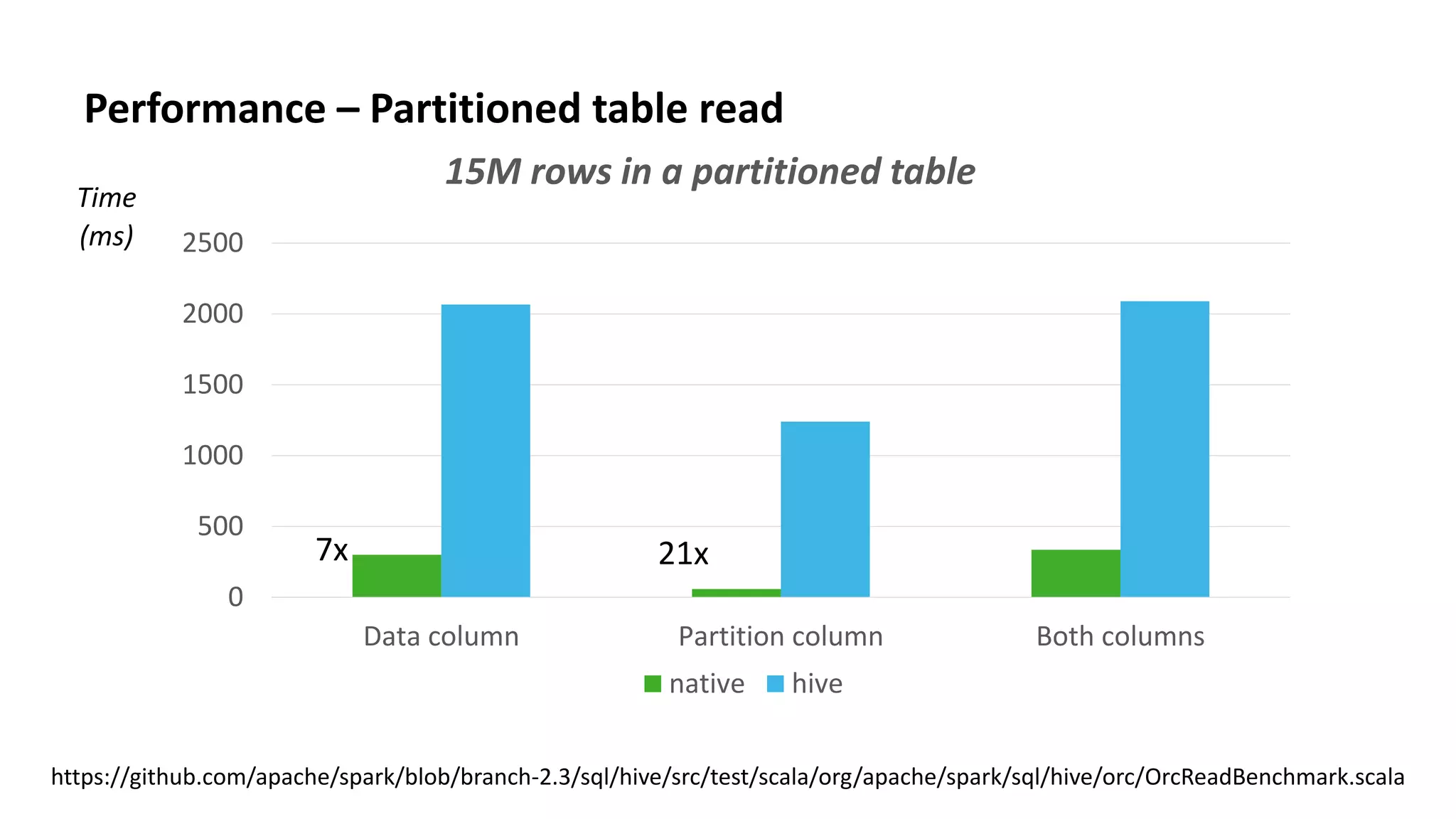
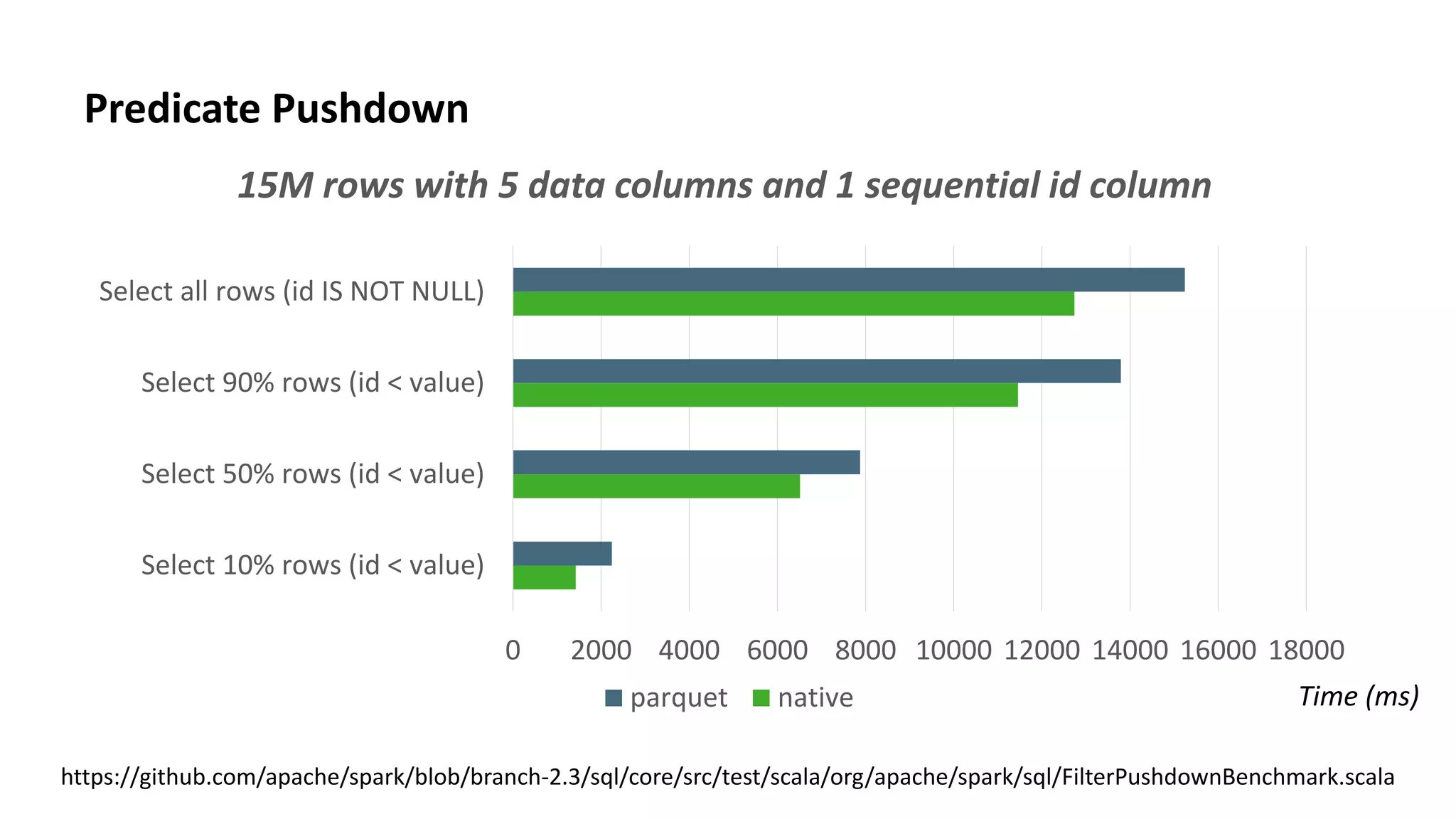









This document discusses improvements to ORC support in Apache Spark 2.3. It describes previous issues with ORC performance and compatibility in Spark. The current approach in Spark 2.3 introduces a new native ORC file format that provides significantly better performance compared to the previous Hive ORC implementation. It allows configuring the ORC implementation and reader type. The document also demonstrates ORC usage in Spark and PySpark. Benchmark results show the native ORC reader provides up to 15x faster performance for scans and predicate pushdown. Future work items are discussed to further improve ORC support in Spark.







































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














