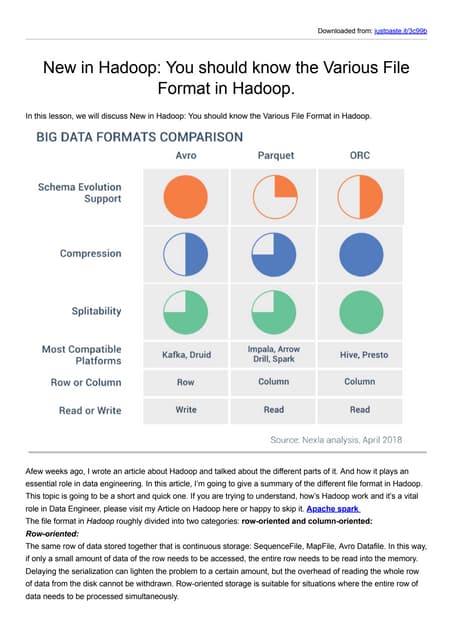
The document discusses storage formats in Hadoop, covering options such as CSV, JSON, Sequence files, Avro, ORC, and Parquet, with a focus on Apache Parquet for its compression and query performance. It also explains the importance of choosing appropriate codecs like Gzip, Bzip2, LZO, and Snappy based on processing capacity and speed. The overarching message emphasizes no single file format meets all needs, urging consideration of data handling requirements when selecting formats.










![CoDecs – performance comparison
Space Savings and CPU Time comparison [Yahoo]
11](https://image.slidesharecdn.com/storageinhadoop-180425183229/75/Storage-in-hadoop-11-2048.jpg)



![Parquet – Specifications
• Supports primitive datatypes – Boolean, INT(32,64,96), Float, Double, Byte_Array
• Schema is defined as Protocol Buffer
> has root called message
> fields are required, optional & repeated
• Field types are either Group or Primitive type
• Each cell is encoded as triplet – repetition level, definition level & value
• Structure of Record is captured by 2 ints – repetition level & definition level
• Definition level explain columns & nullity of columns
• Repetition Level explains where a new list
[repeated fields are stored as lists] starts
15
Definition Level
message ExampleDefinitionLevel {
optional group a {
optional group b {
optional string c;
}
}
}
one column: a.b.c
Image Source – Twitter’s Blog - https://blog.twitter.com/engineering/en_us/a/2013/dremel-made-simple-with-parquet.html](https://image.slidesharecdn.com/storageinhadoop-180425183229/75/Storage-in-hadoop-15-2048.jpg)








![[Nvidia] Divide Your Depots](https://cdn.slidesharecdn.com/ss_thumbnails/dividing-depots-slides-130523180926-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)