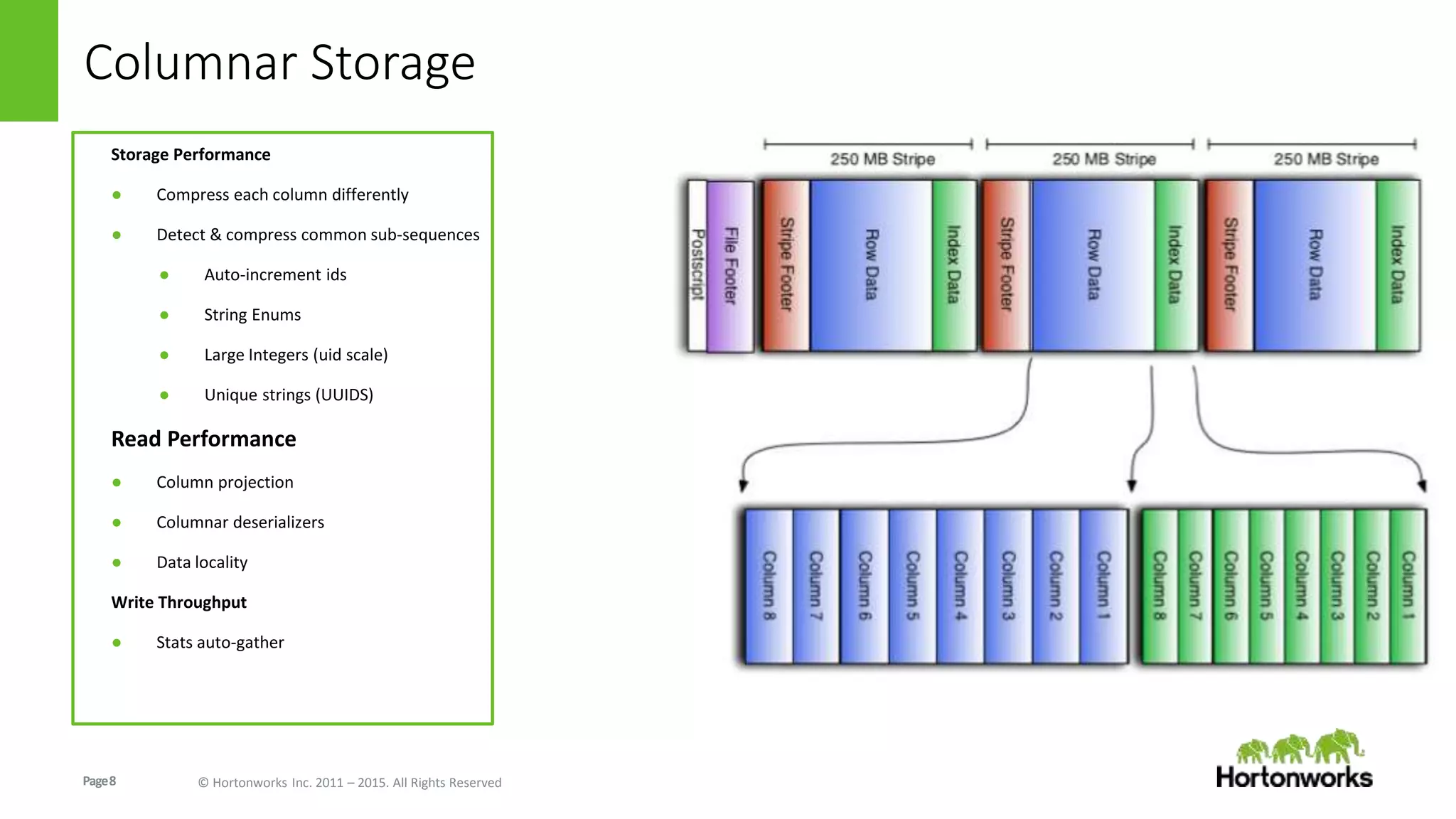
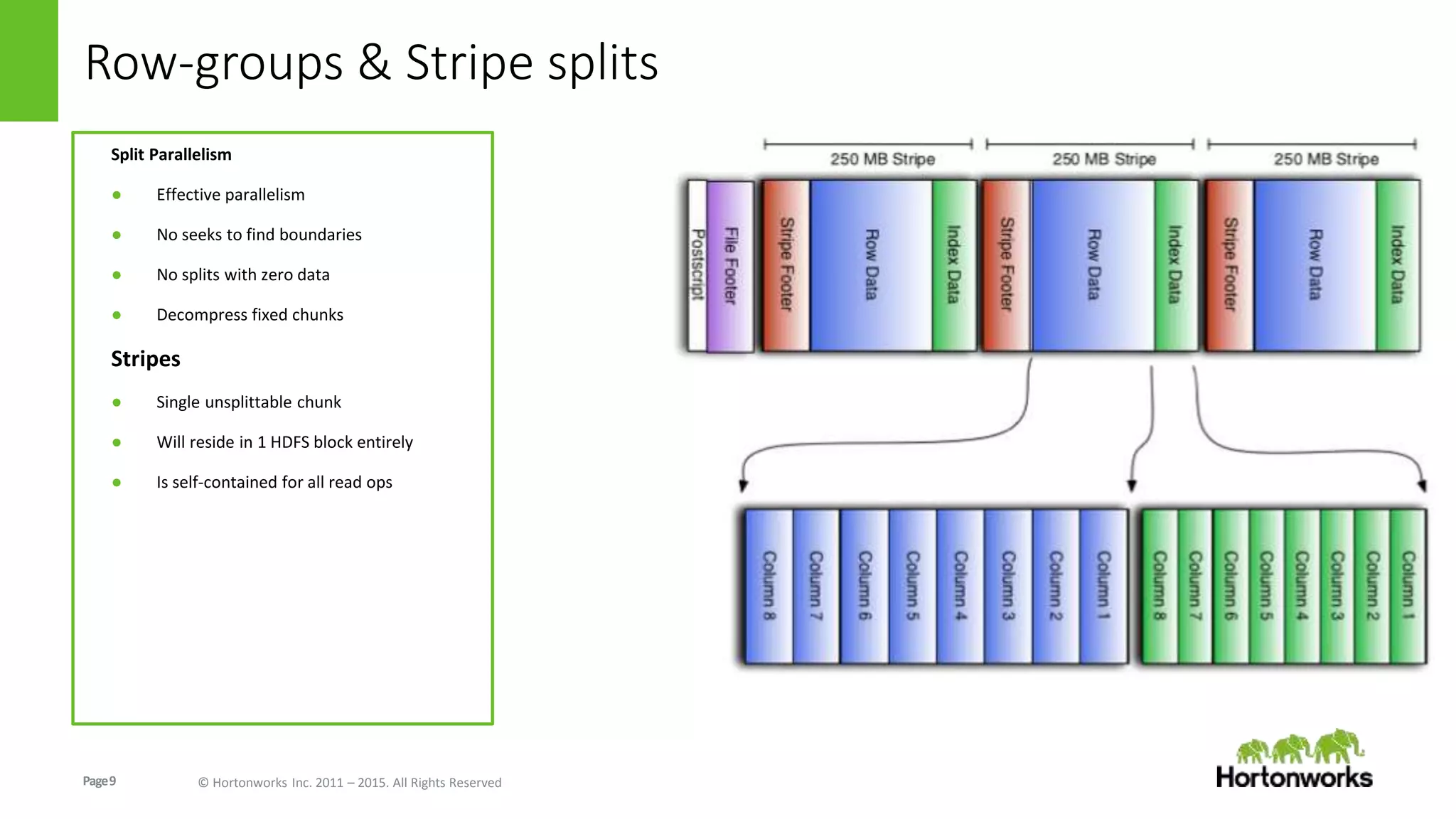
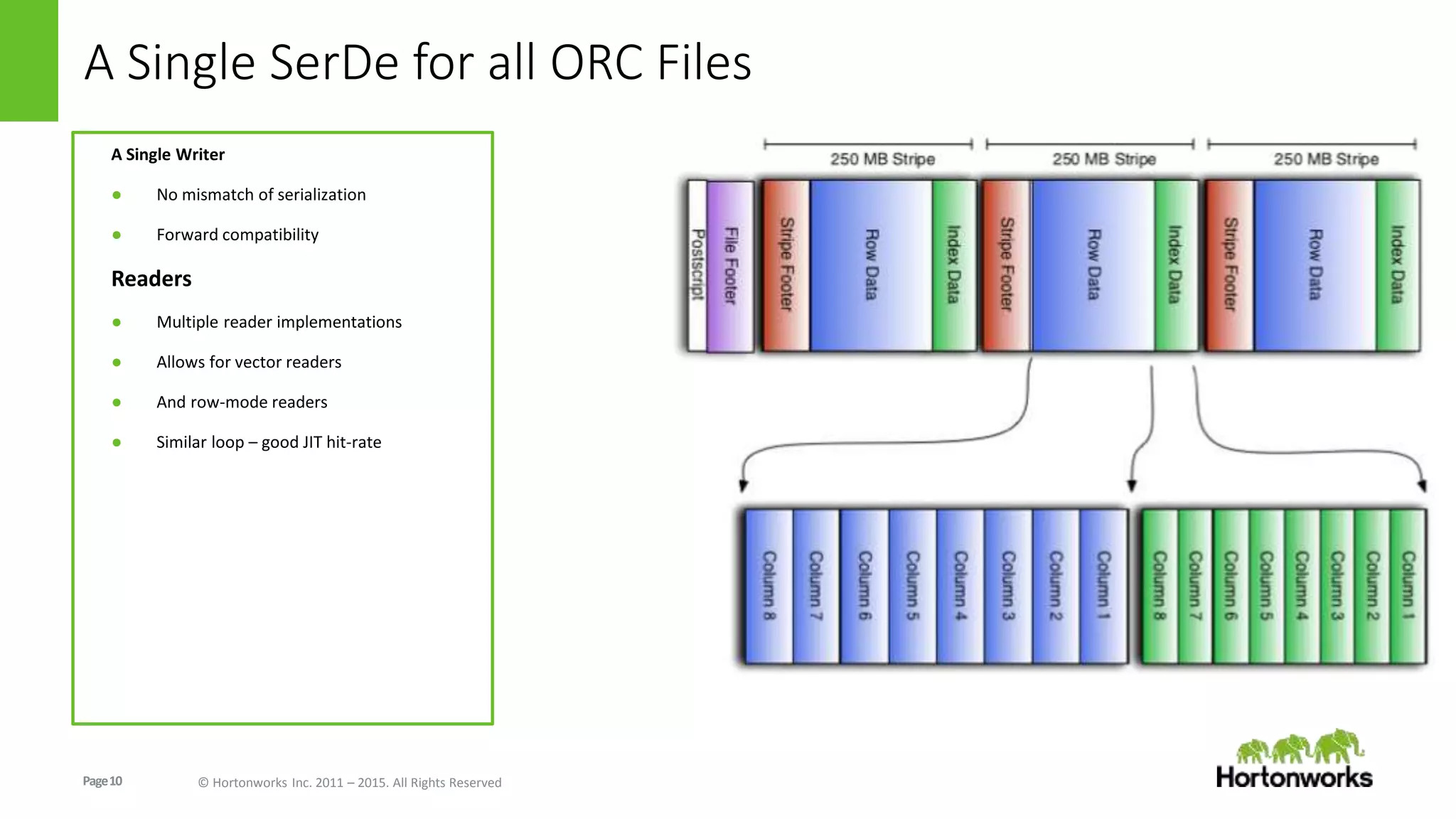
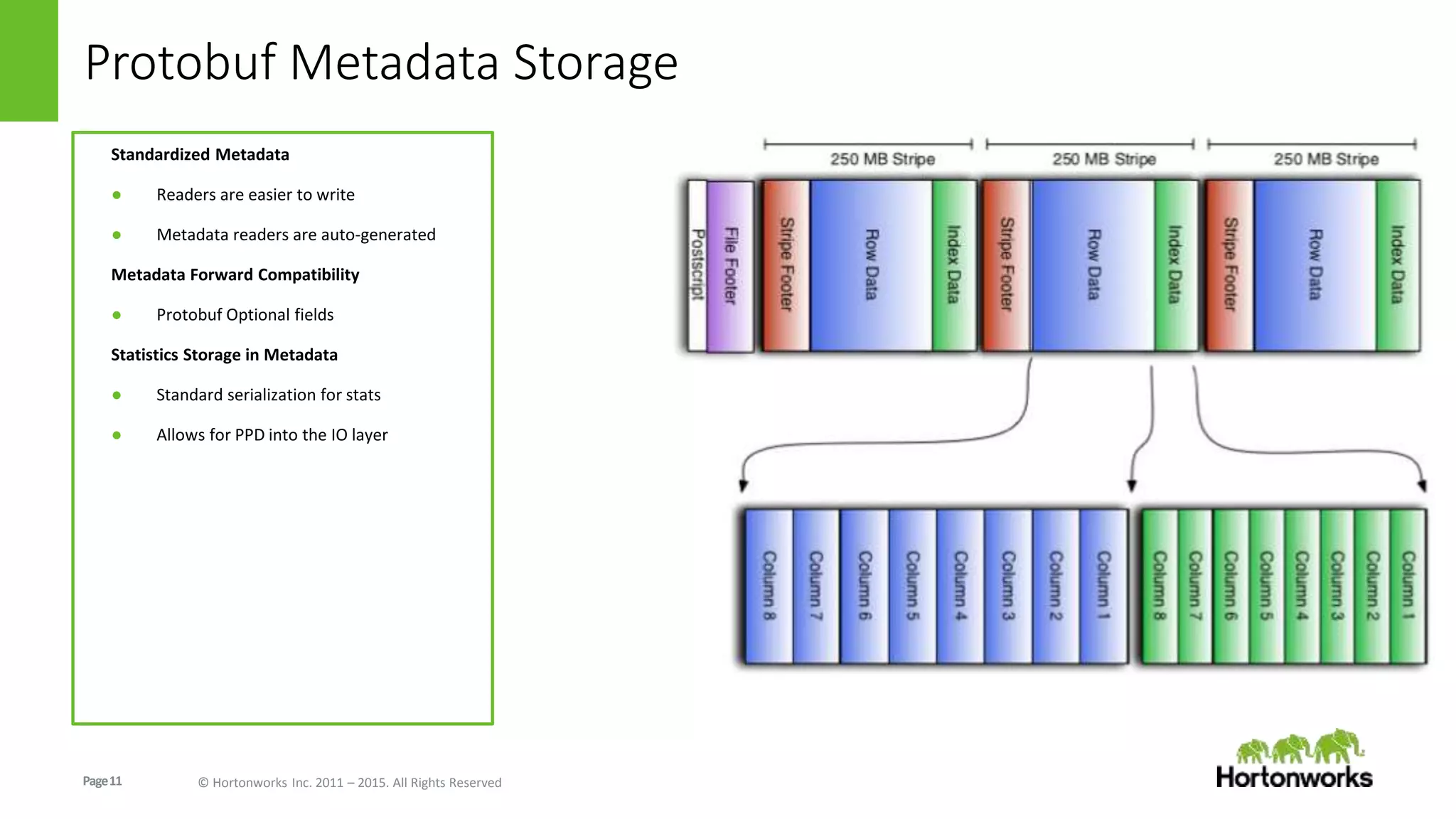
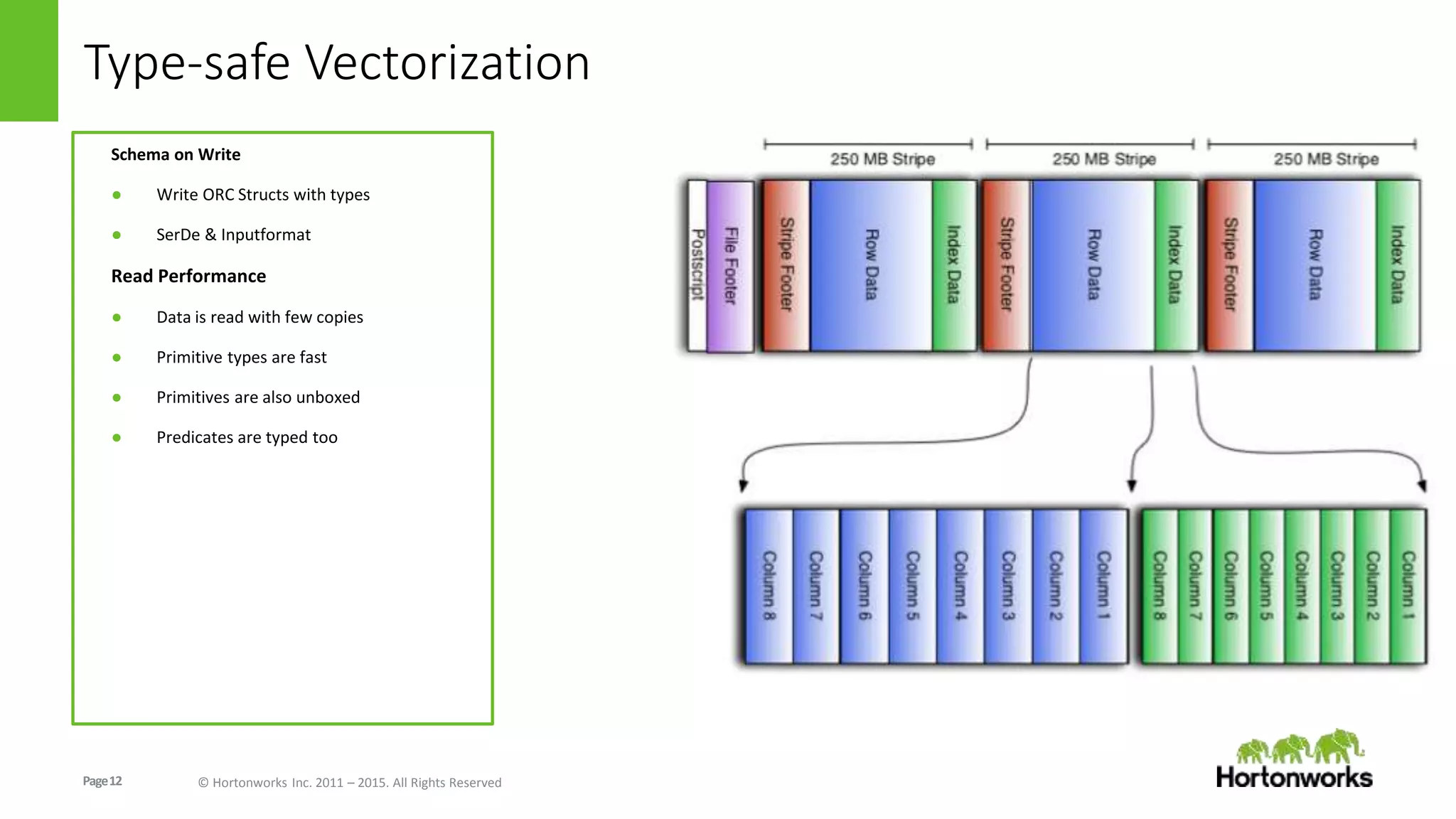
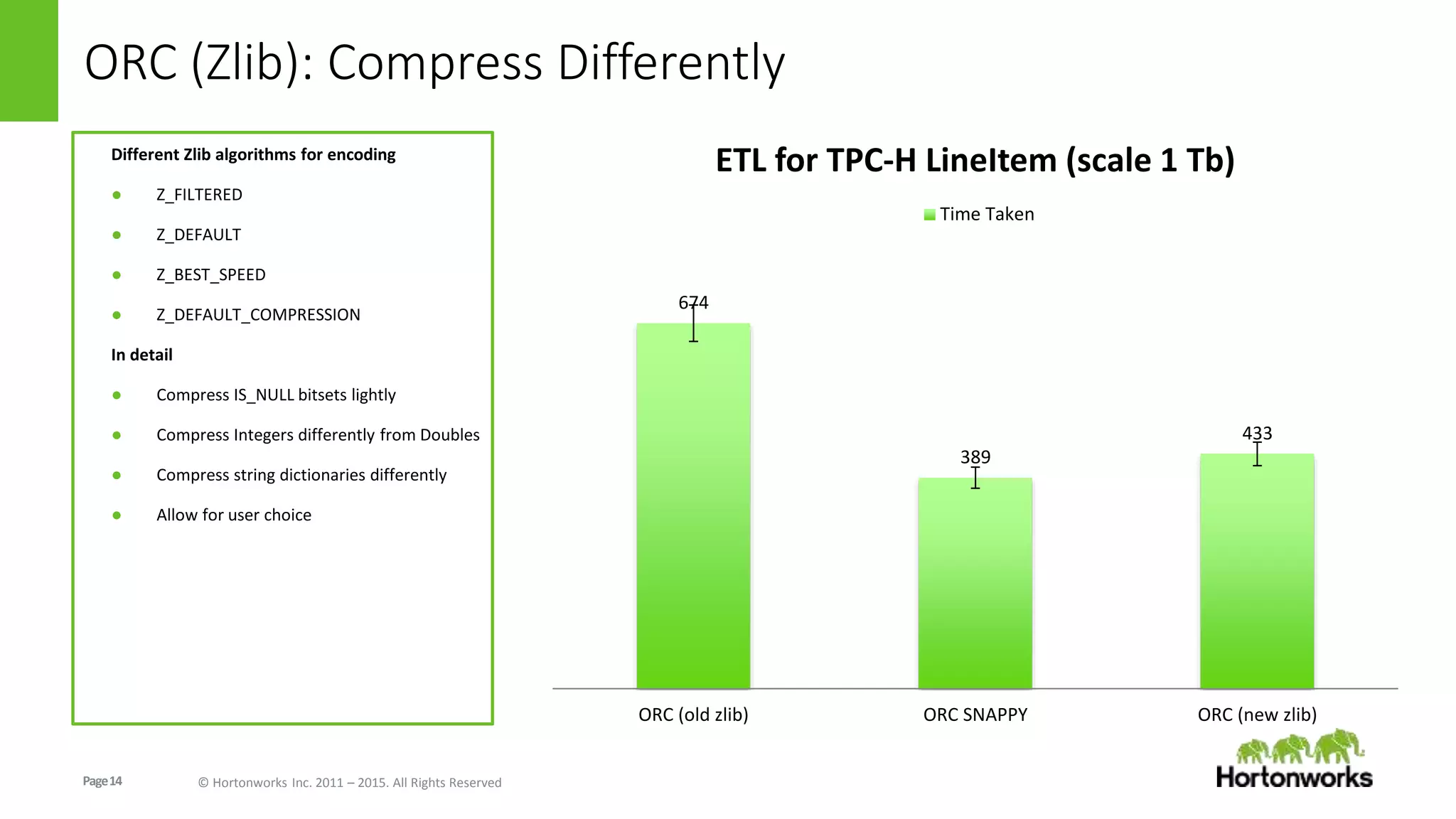
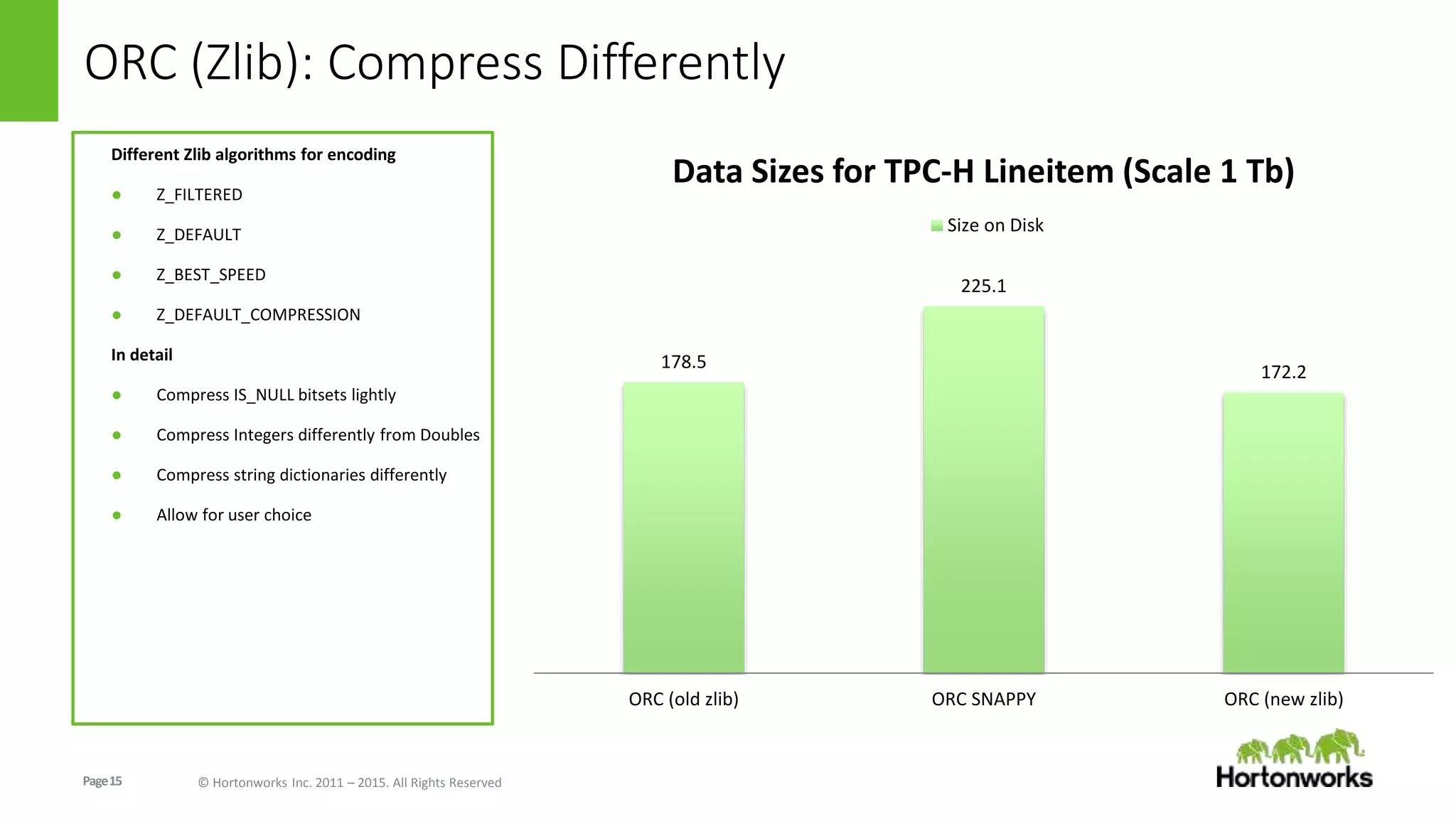
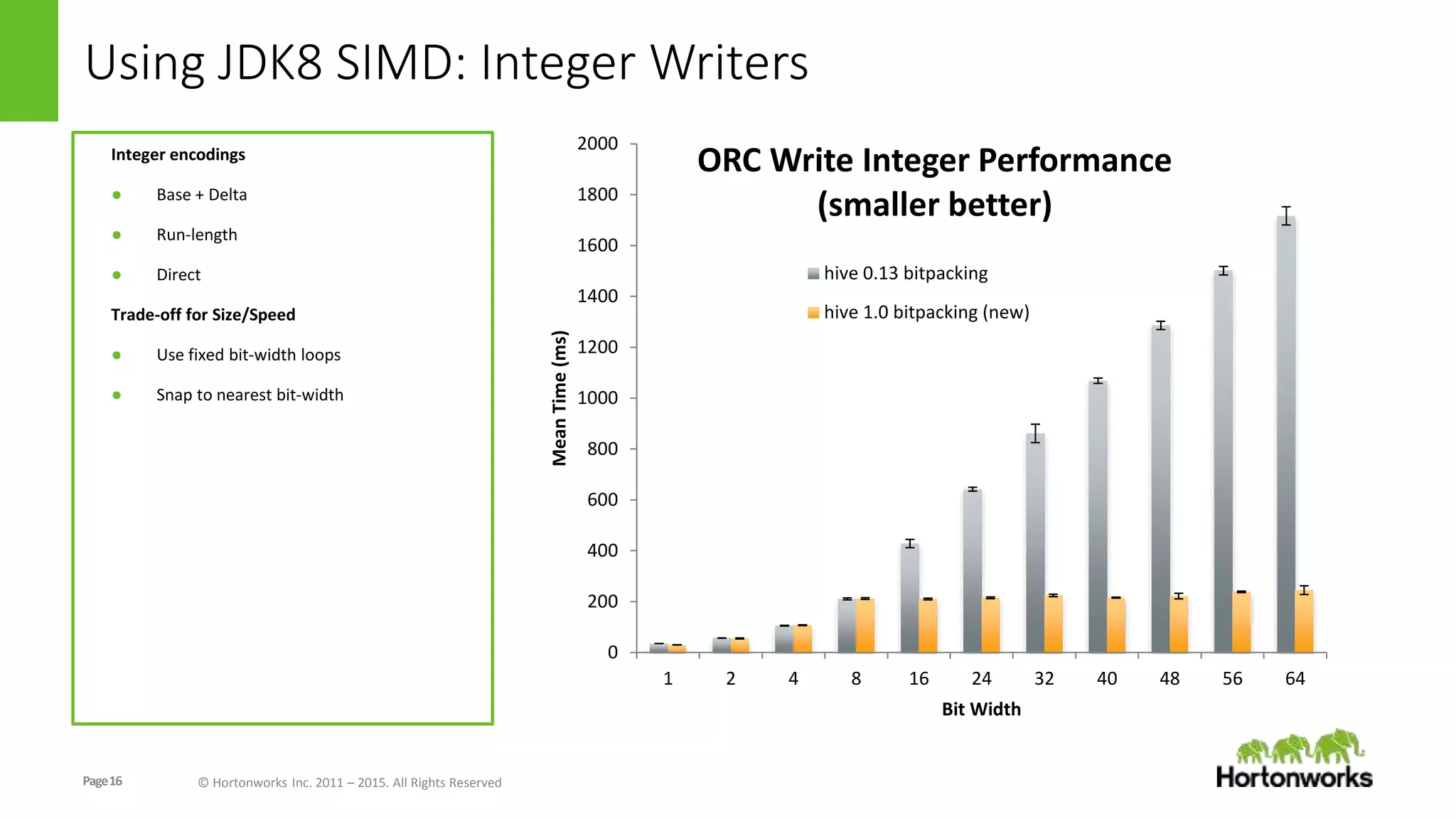
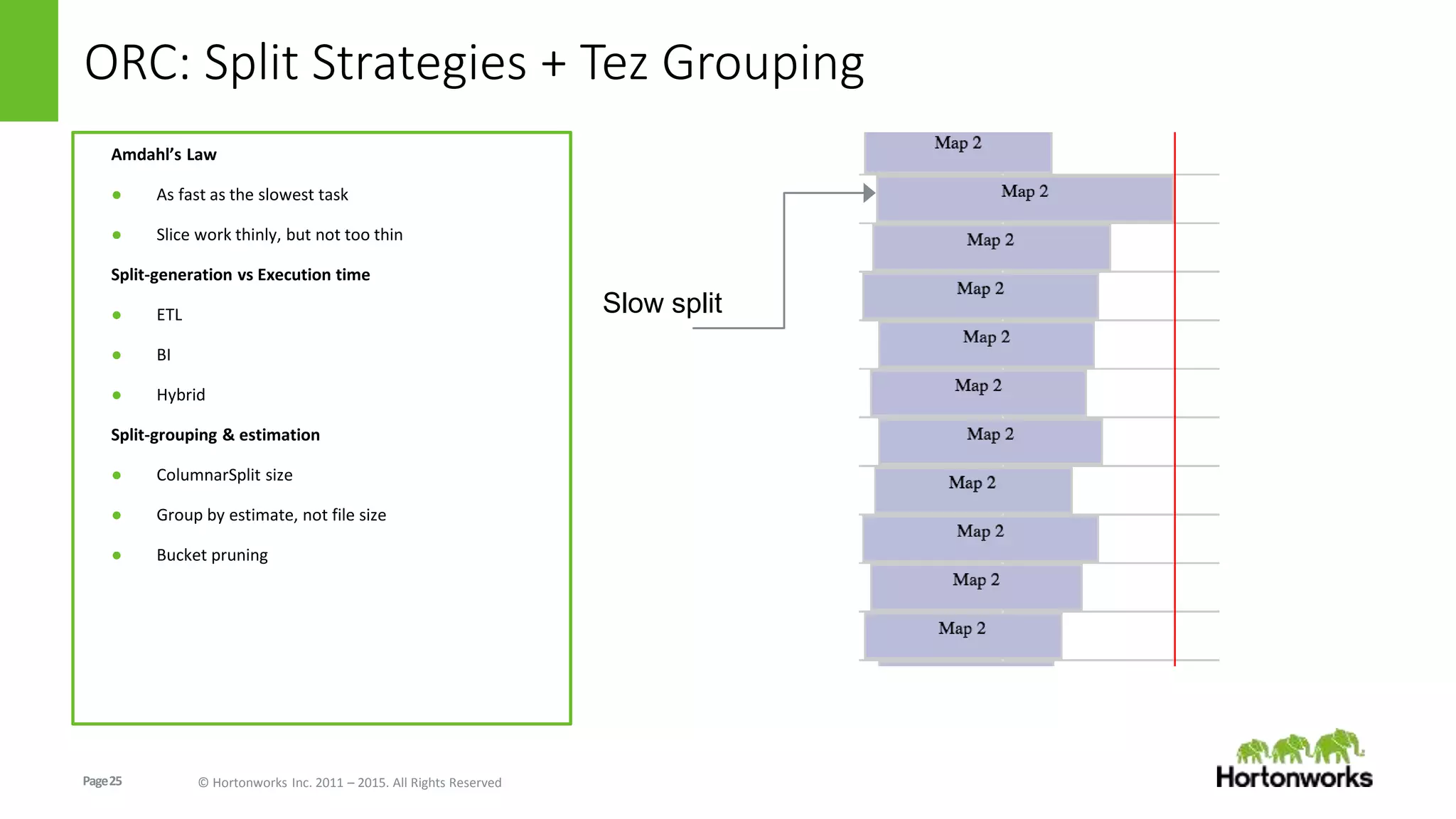
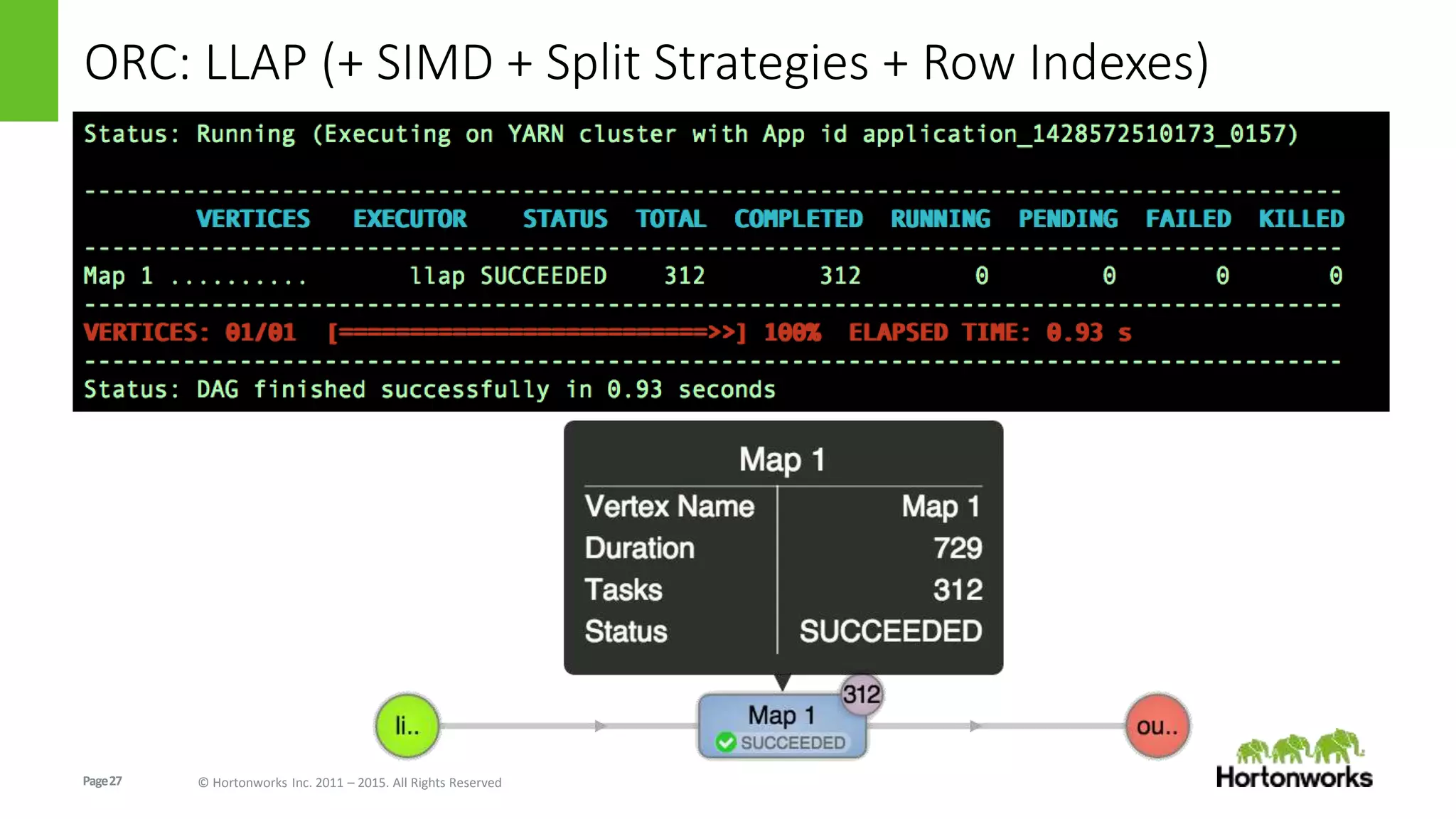
The document discusses the Optimized Row Columnar (ORC) file format. ORC provides columnar storage, row groups, optimized compression, vectorized processing and other features to improve performance of Hive queries up to 100x. It describes how ORC has been implemented at companies like Facebook and Spotify to significantly reduce storage needs, improve query performance and reduce CPU usage. The document outlines various optimizations in ORC including column projection, stripe splitting, statistics gathering, vectorized processing using SIMD and improvements in compression and encoding of integer, double and string data types.



![Page4 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
ORC at Facebook
Saved more than 1,400
servers worth of storage.
Compressioni
Compression ratio
increased from 5x to 8x
globally.
Compressioni
[1]](https://image.slidesharecdn.com/orc2015-public-150422102158-conversion-gate02/75/ORC-2015-4-2048.jpg)
![Page5 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
ORC at Spotify
16x less HDFS read when
using ORC versus Avro.(5)
IOi
32x less CPU when using
ORC versus Avro.(5)
CPUi
[2]](https://image.slidesharecdn.com/orc2015-public-150422102158-conversion-gate02/75/ORC-2015-5-2048.jpg)