Downloaded 18 times







![8/55
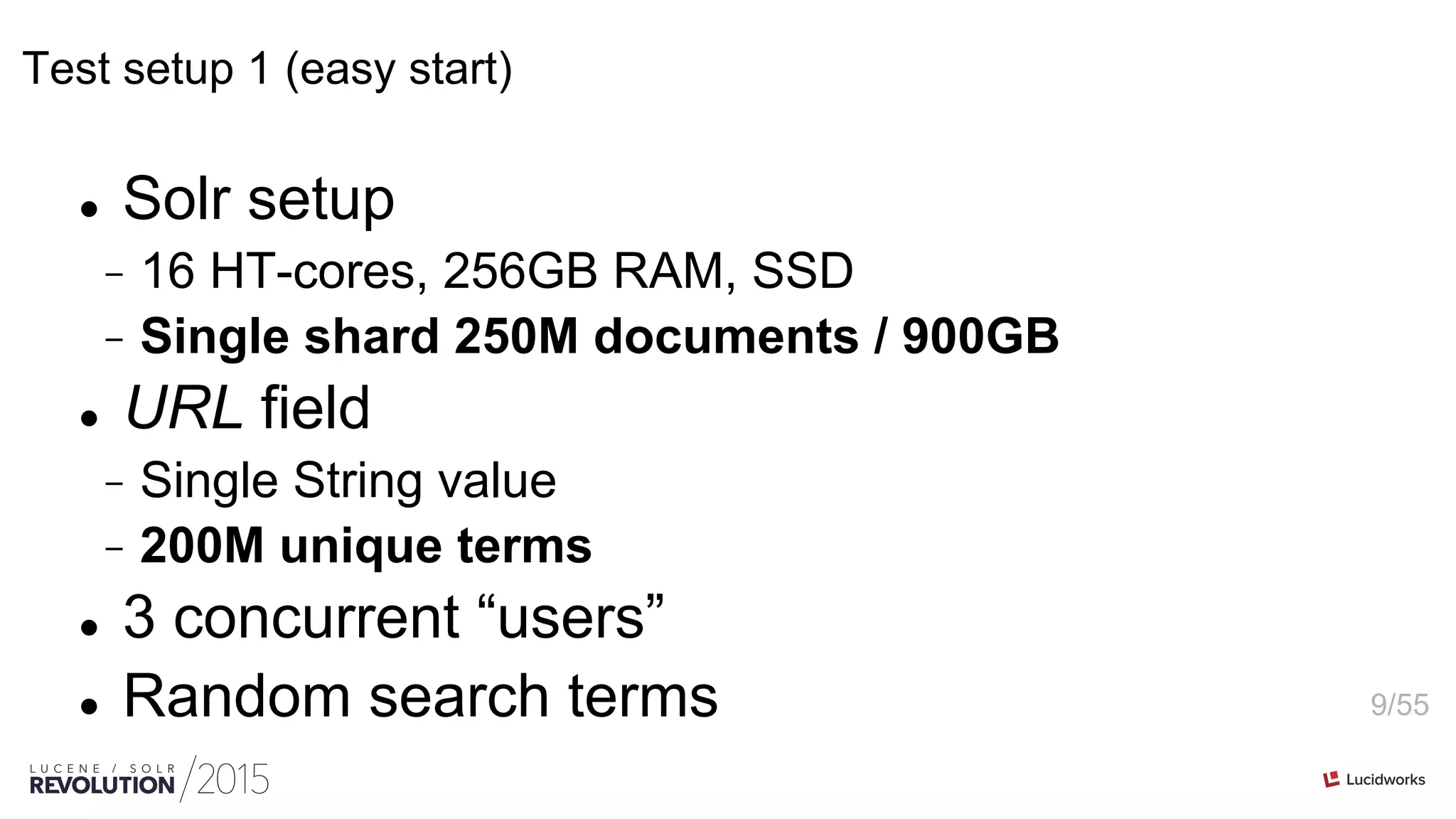
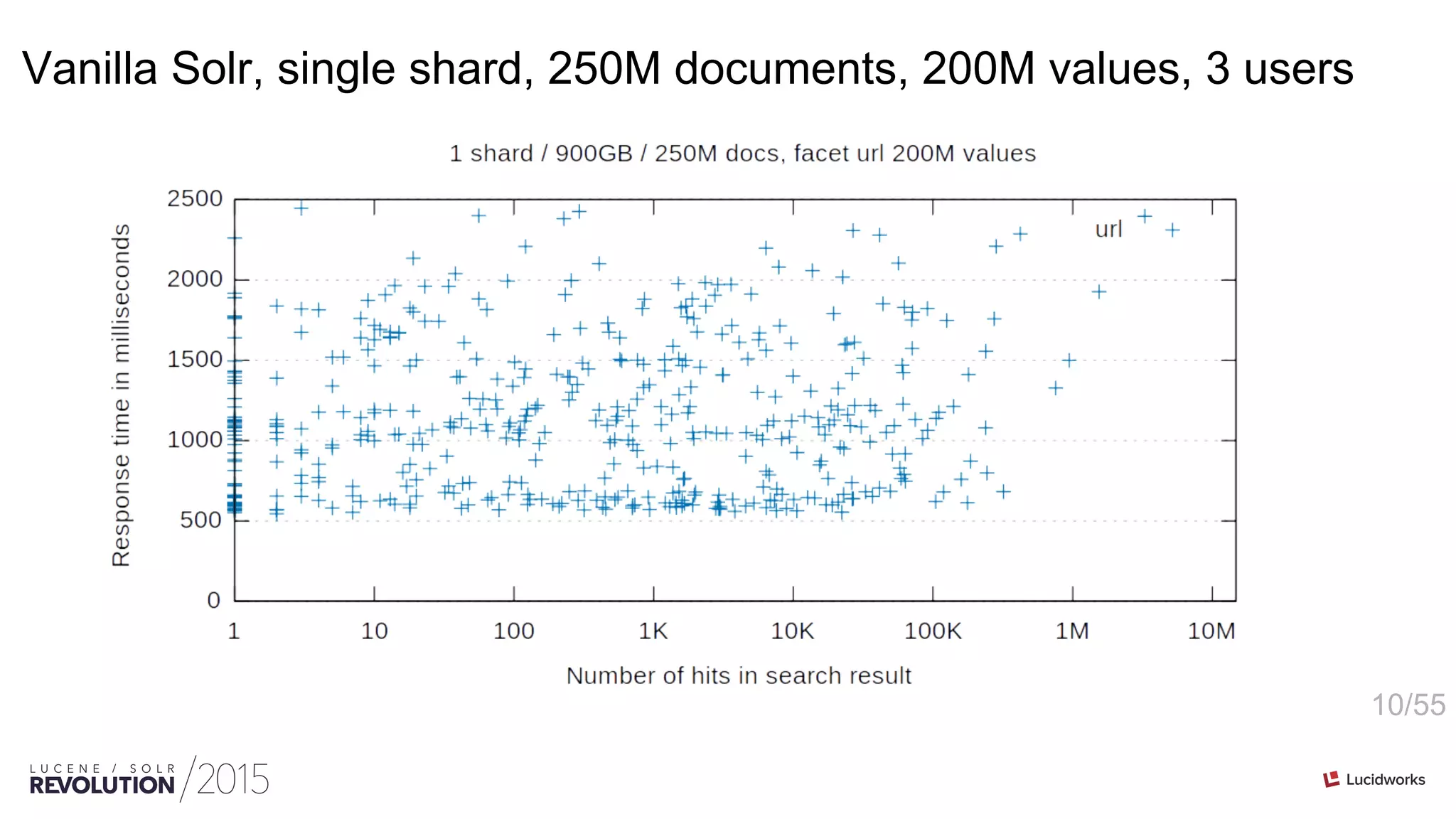
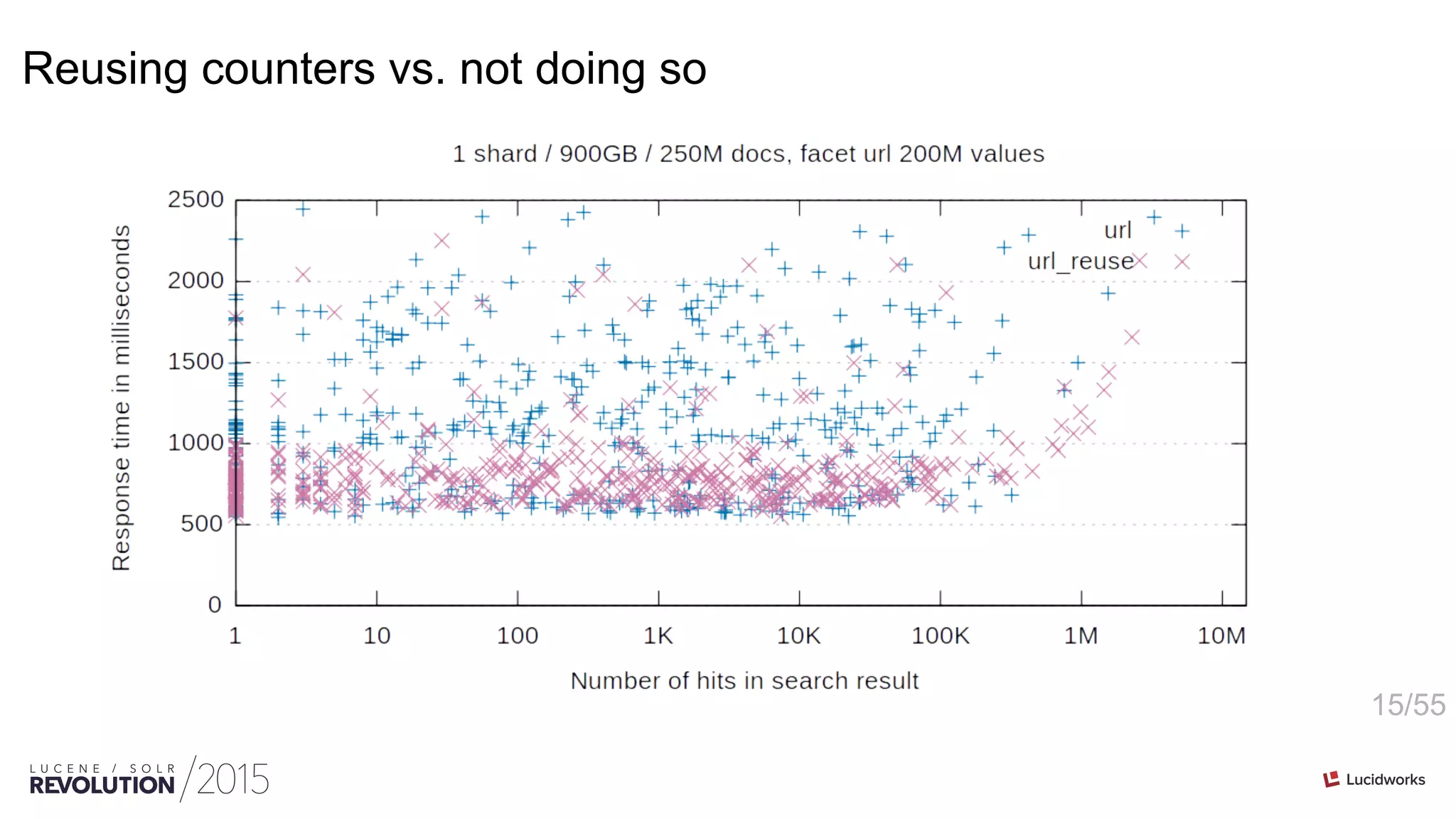
String faceting 101 (single shard)
counter = new int[ordinals]
for docID: result.getDocIDs()
for ordinal: getOrdinals(docID)
counter[ordinal]++
for ordinal = 0 ; ordinal < counters.length ; ordinal++
priorityQueue.add(ordinal, counter[ordinal])
for entry: priorityQueue
result.add(resolveTerm(ordinal), count)
ord term counter
0 A 0
1 B 3
2 C 0
3 D 1006
4 E 1
5 F 1
6 G 0
7 H 0
8 I 3](https://image.slidesharecdn.com/facetingoptimizationsforsolr-tokeeskildsen-151021185330-lva1-app6892/75/Faceting-Optimizations-for-Solr-Presented-by-Toke-Eskildsen-State-University-Library-Denmark-8-2048.jpg)
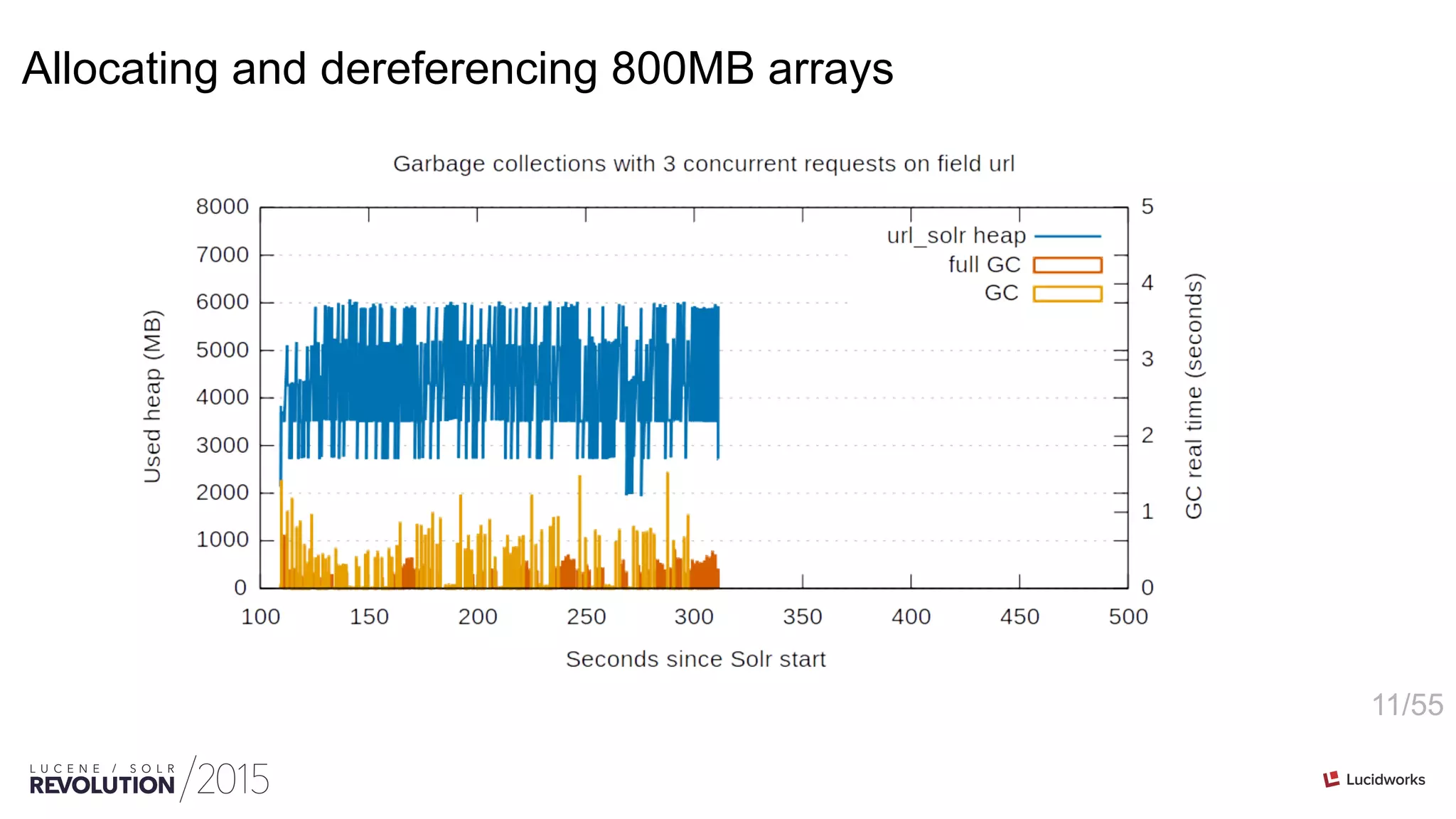
![12/55
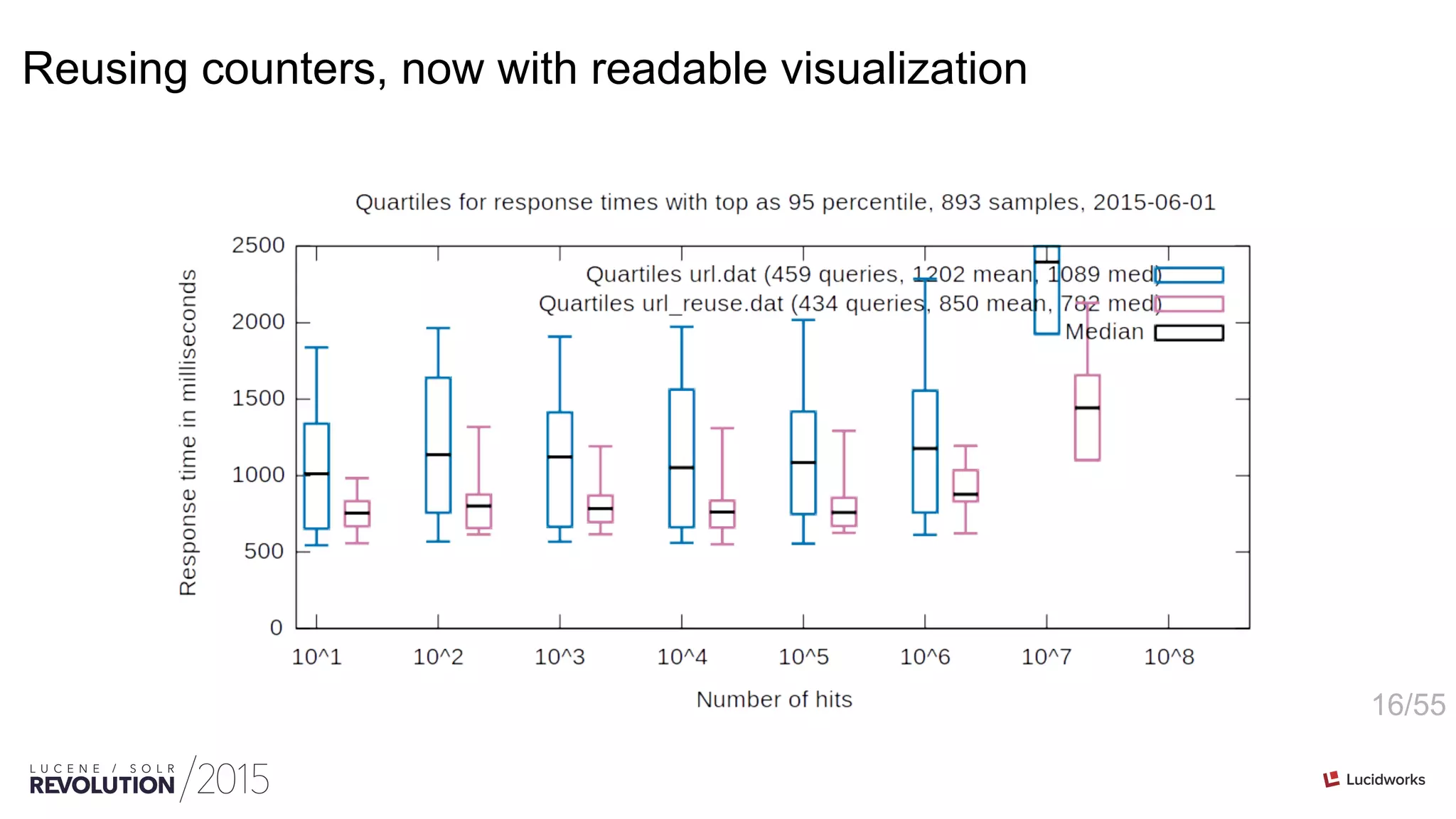
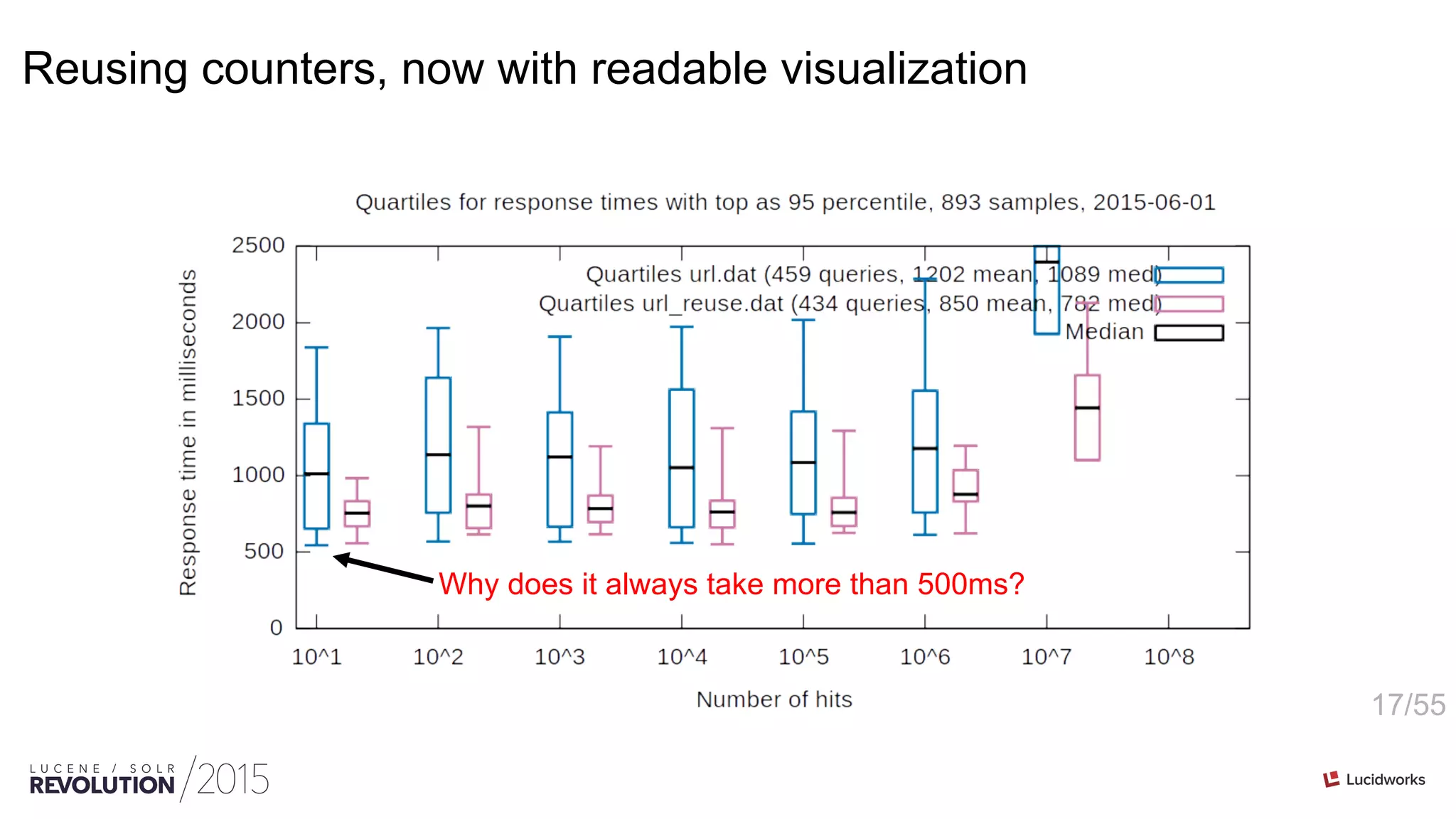
Reuse the counter
counter = new int[ordinals]
for docID: result.getDocIDs()
for ordinal: getOrdinals(docID)
counter[ordinal]++
for ordinal = 0 ; ordinal < counters.length ; ordinal++
priorityQueue.add(ordinal, counter[ordinal])
<counter no more referenced and will be garbage collected at some point>](https://image.slidesharecdn.com/facetingoptimizationsforsolr-tokeeskildsen-151021185330-lva1-app6892/75/Faceting-Optimizations-for-Solr-Presented-by-Toke-Eskildsen-State-University-Library-Denmark-12-2048.jpg)
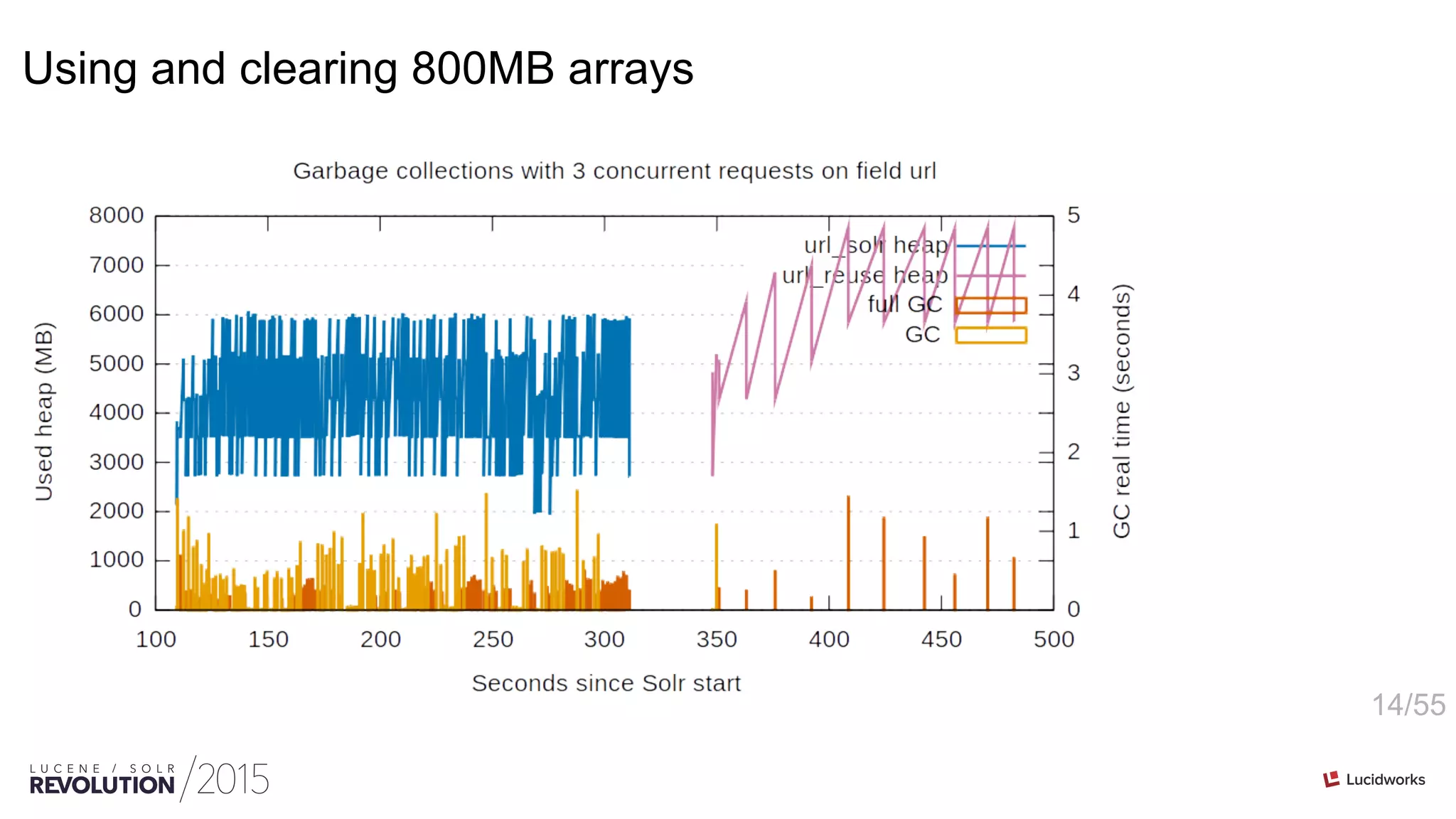
![13/55
Reuse the counter
counter = pool.getCounter()
for docID: result.getDocIDs()
for ordinal: getOrdinals(docID)
counter[ordinal]++
for ordinal = 0 ; ordinal < counters.length ; ordinal++
priorityQueue.add(ordinal, counter[ordinal])
pool.release(counter)
Note: The JSON Facet API in Solr 5 already supports reuse of counters](https://image.slidesharecdn.com/facetingoptimizationsforsolr-tokeeskildsen-151021185330-lva1-app6892/75/Faceting-Optimizations-for-Solr-Presented-by-Toke-Eskildsen-State-University-Library-Denmark-13-2048.jpg)
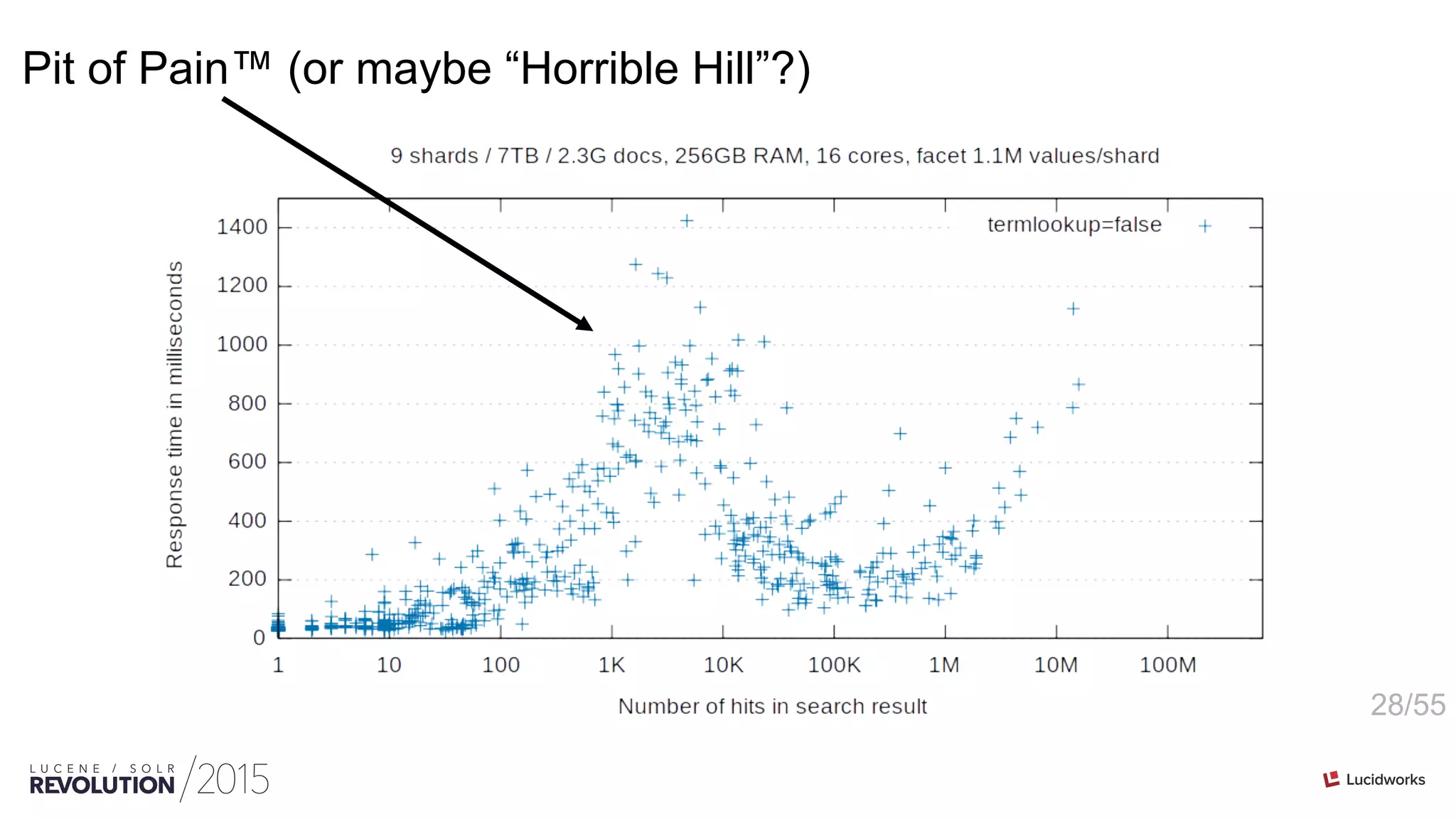
![18/55
Iteration is not free
counter = pool.getCounter()
for docID: result.getDocIDs()
for ordinal: getOrdinals(docID)
counter[ordinal]++
for ordinal = 0 ; ordinal < counters.length ; ordinal++
priorityQueue.add(ordinal, counter[ordinal])
pool.release(counter)
200M unique terms = 800MB](https://image.slidesharecdn.com/facetingoptimizationsforsolr-tokeeskildsen-151021185330-lva1-app6892/75/Faceting-Optimizations-for-Solr-Presented-by-Toke-Eskildsen-State-University-Library-Denmark-18-2048.jpg)
![20/55
ord counter
0 0
1 0
2 0
3 1
4 0
5 0
6 0
7 0
8 0
tracker
3
N/A
N/A
N/A
N/A
N/A
N/A
N/A
N/A
counter[3]++
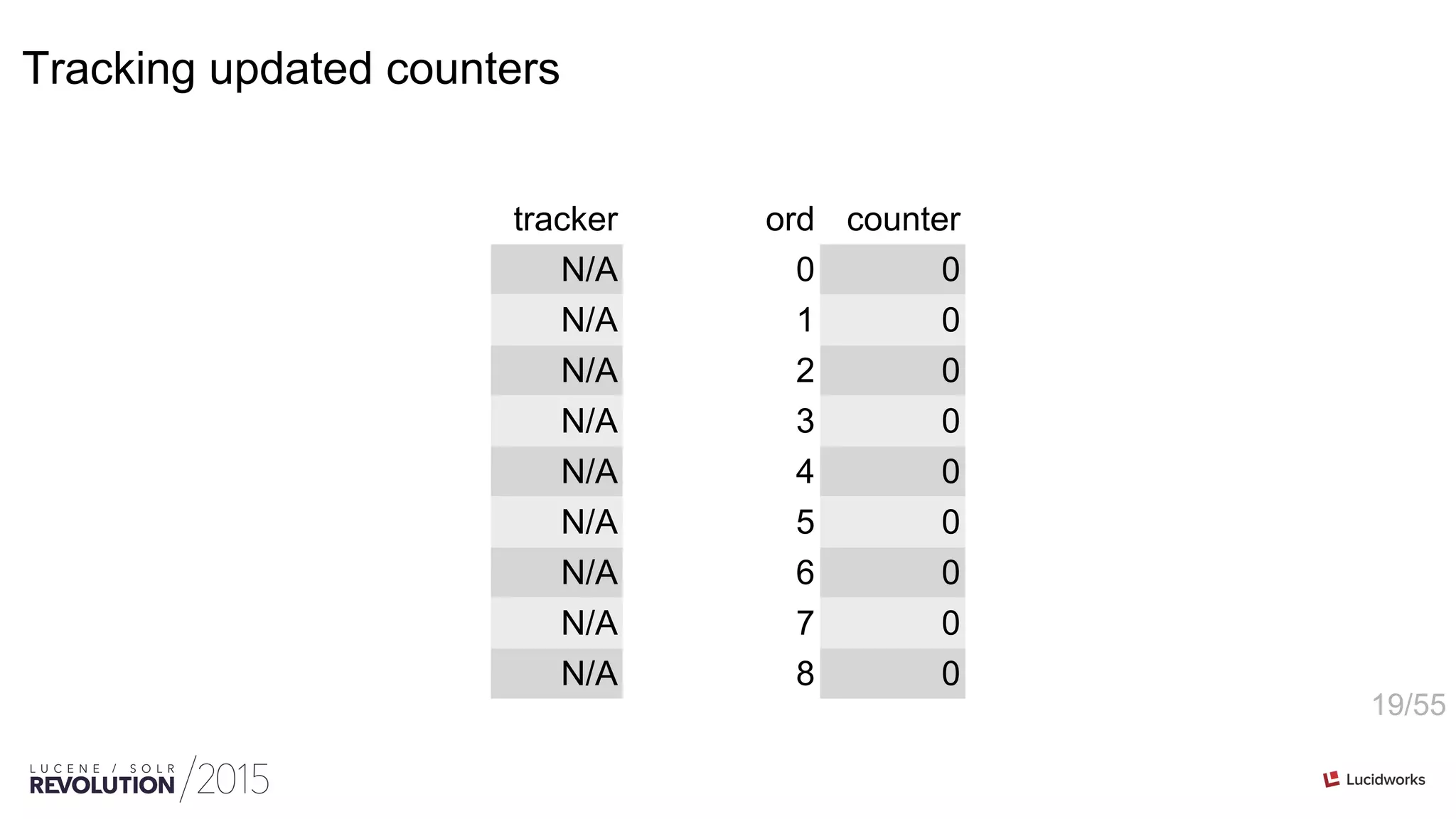
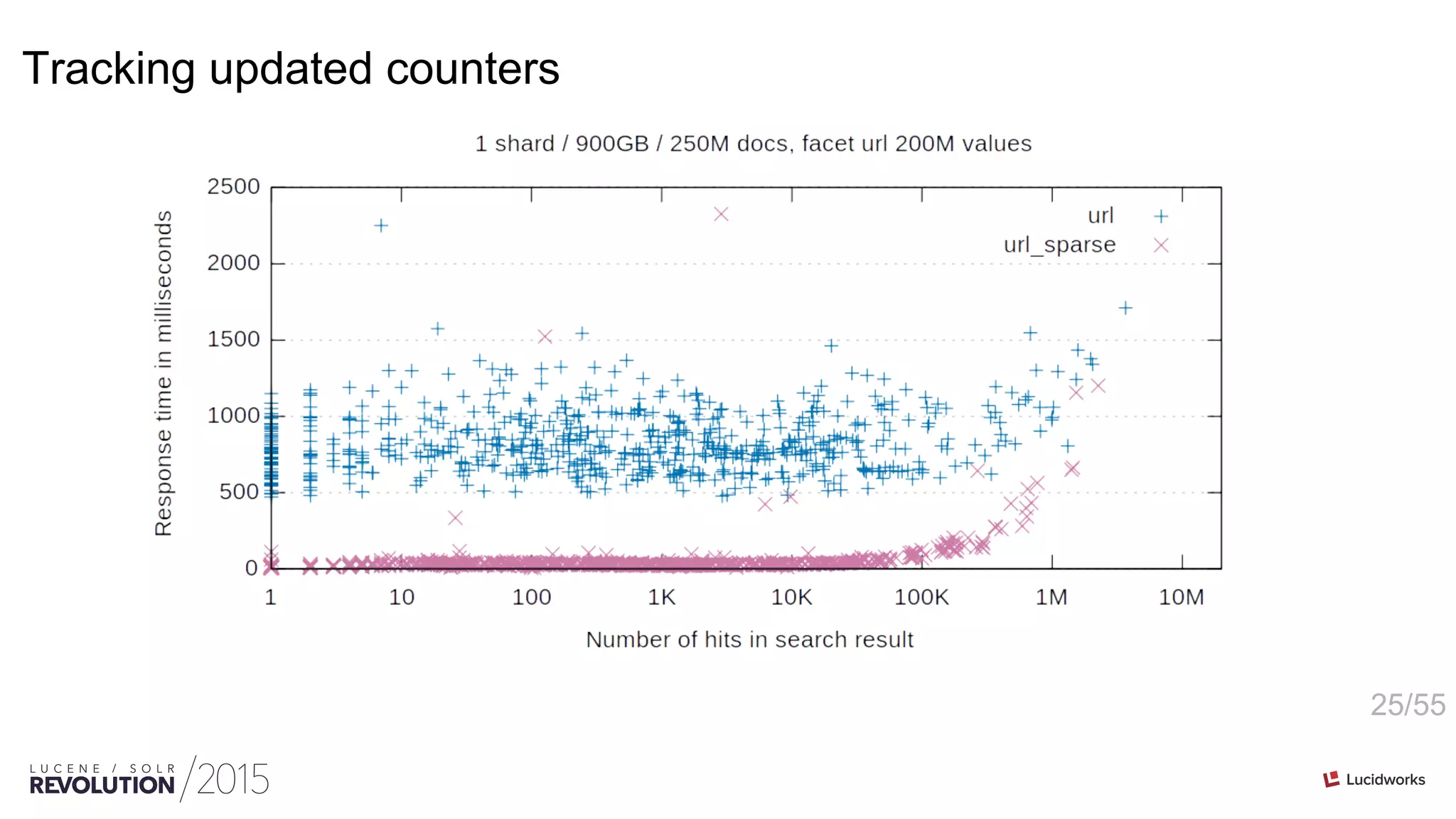
Tracking updated counters](https://image.slidesharecdn.com/facetingoptimizationsforsolr-tokeeskildsen-151021185330-lva1-app6892/75/Faceting-Optimizations-for-Solr-Presented-by-Toke-Eskildsen-State-University-Library-Denmark-20-2048.jpg)
![21/55
ord counter
0 0
1 1
2 0
3 1
4 0
5 0
6 0
7 0
8 0
tracker
3
1
N/A
N/A
N/A
N/A
N/A
N/A
N/A
counter[3]++
counter[1]++
Tracking updated counters](https://image.slidesharecdn.com/facetingoptimizationsforsolr-tokeeskildsen-151021185330-lva1-app6892/75/Faceting-Optimizations-for-Solr-Presented-by-Toke-Eskildsen-State-University-Library-Denmark-21-2048.jpg)
![22/55
ord counter
0 0
1 3
2 0
3 1
4 0
5 0
6 0
7 0
8 0
tracker
3
1
N/A
N/A
N/A
N/A
N/A
N/A
N/A
counter[3]++
counter[1]++
counter[1]++
counter[1]++
Tracking updated counters](https://image.slidesharecdn.com/facetingoptimizationsforsolr-tokeeskildsen-151021185330-lva1-app6892/75/Faceting-Optimizations-for-Solr-Presented-by-Toke-Eskildsen-State-University-Library-Denmark-22-2048.jpg)
![23/55
ord counter
0 0
1 3
2 0
3 1006
4 1
5 1
6 0
7 0
8 3
tracker
3
1
8
4
5
N/A
N/A
N/A
N/A
counter[3]++
counter[1]++
counter[1]++
counter[1]++
counter[8]++
counter[8]++
counter[4]++
counter[8]++
counter[5]++
counter[1]++
counter[1]++
…
counter[1]++
Tracking updated counters](https://image.slidesharecdn.com/facetingoptimizationsforsolr-tokeeskildsen-151021185330-lva1-app6892/75/Faceting-Optimizations-for-Solr-Presented-by-Toke-Eskildsen-State-University-Library-Denmark-23-2048.jpg)
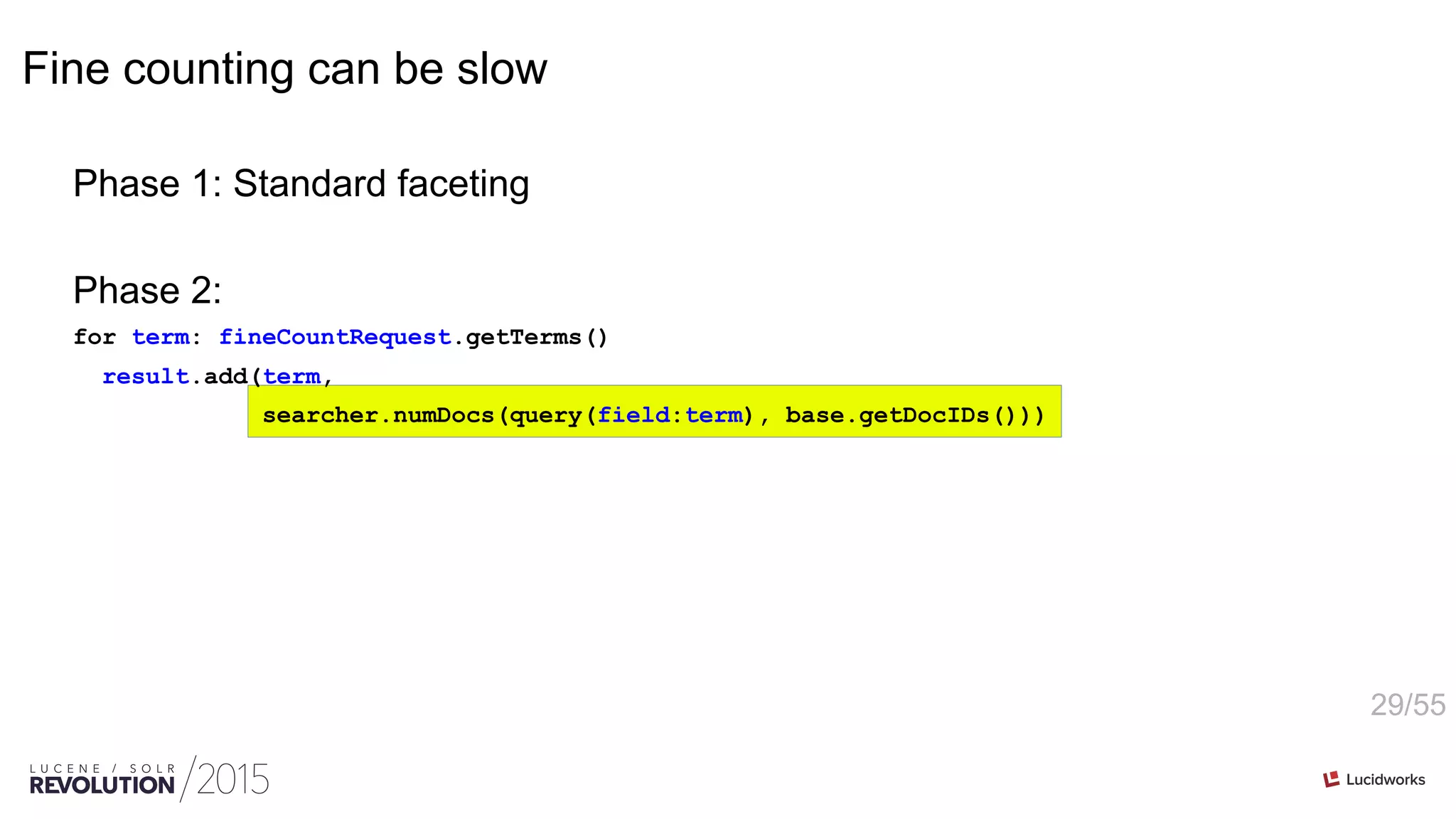
![24/55
Tracking updated counters
counter = pool.getCounter()
for docID: result.getDocIDs()
for ordinal: getOrdinals(docID)
if counter[ordinal]++ == 0 && tracked < maxTracked
tracker[tracked++] = ordinal
if tracked < maxTracked
for i = 0 ; i < tracked ; i++
priorityQueue.add(tracker[i], counter[tracker[i]])
else
for ordinal = 0 ; ordinal < counter.length ; ordinal++
priorityQueue.add(ordinal, counter[ordinal])
ord counter
0 0
1 3
2 0
3 1006
4 1
5 1
6 0
7 0
8 3
tracker
3
1
8
4
5
N/A
N/A
N/A
N/A](https://image.slidesharecdn.com/facetingoptimizationsforsolr-tokeeskildsen-151021185330-lva1-app6892/75/Faceting-Optimizations-for-Solr-Presented-by-Toke-Eskildsen-State-University-Library-Denmark-24-2048.jpg)







![39/55
int vs. PackedInts
domain: 4 MB
url: 780 MB
links: 2350 MB
int[ordinals] PackedInts(ordinals, maxBPV)
domain: 3 MB (72%)
url: 420 MB (53%)
links: 1760 MB (75%)](https://image.slidesharecdn.com/facetingoptimizationsforsolr-tokeeskildsen-151021185330-lva1-app6892/75/Faceting-Optimizations-for-Solr-Presented-by-Toke-Eskildsen-State-University-Library-Denmark-39-2048.jpg)

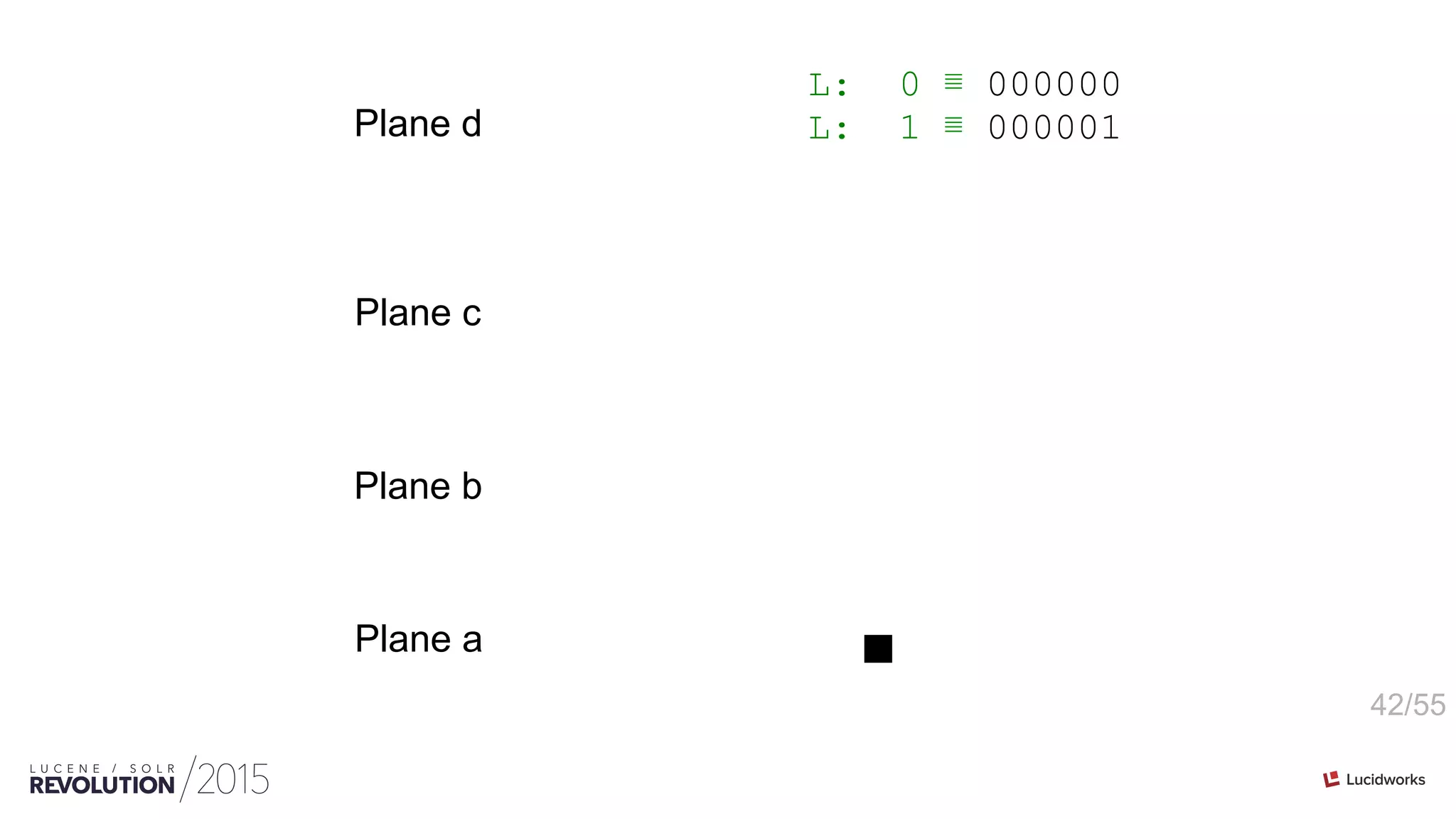
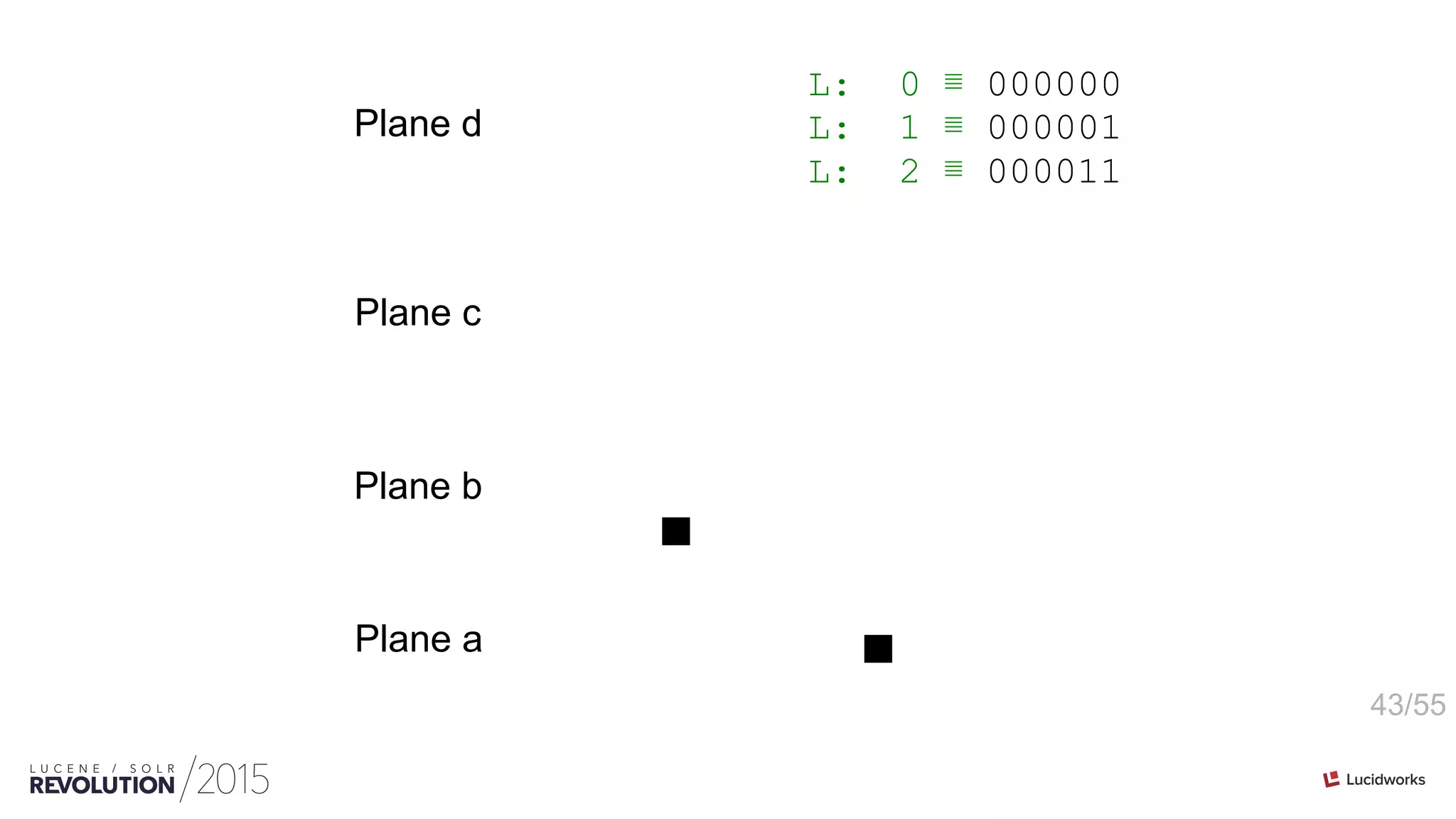
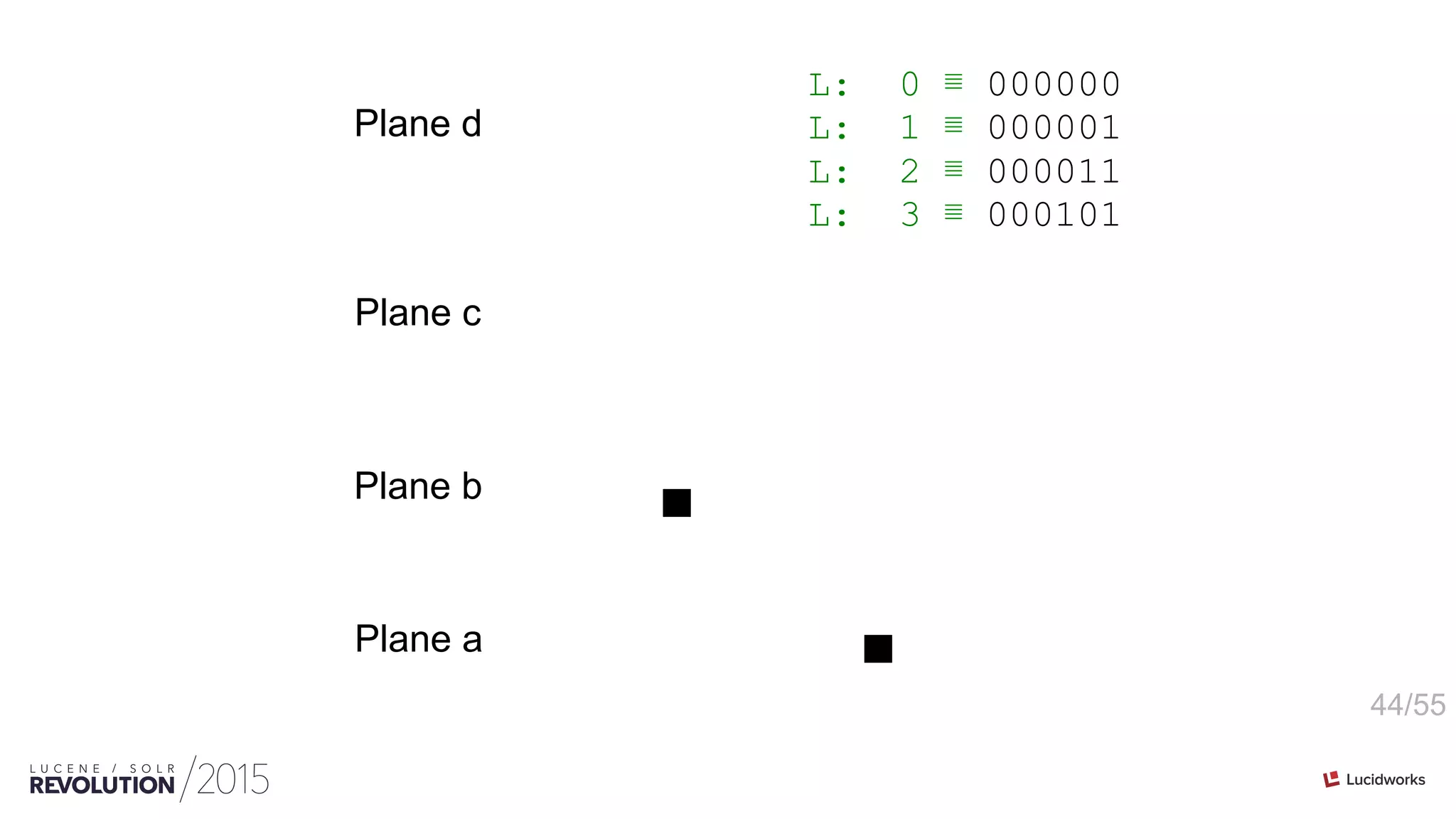
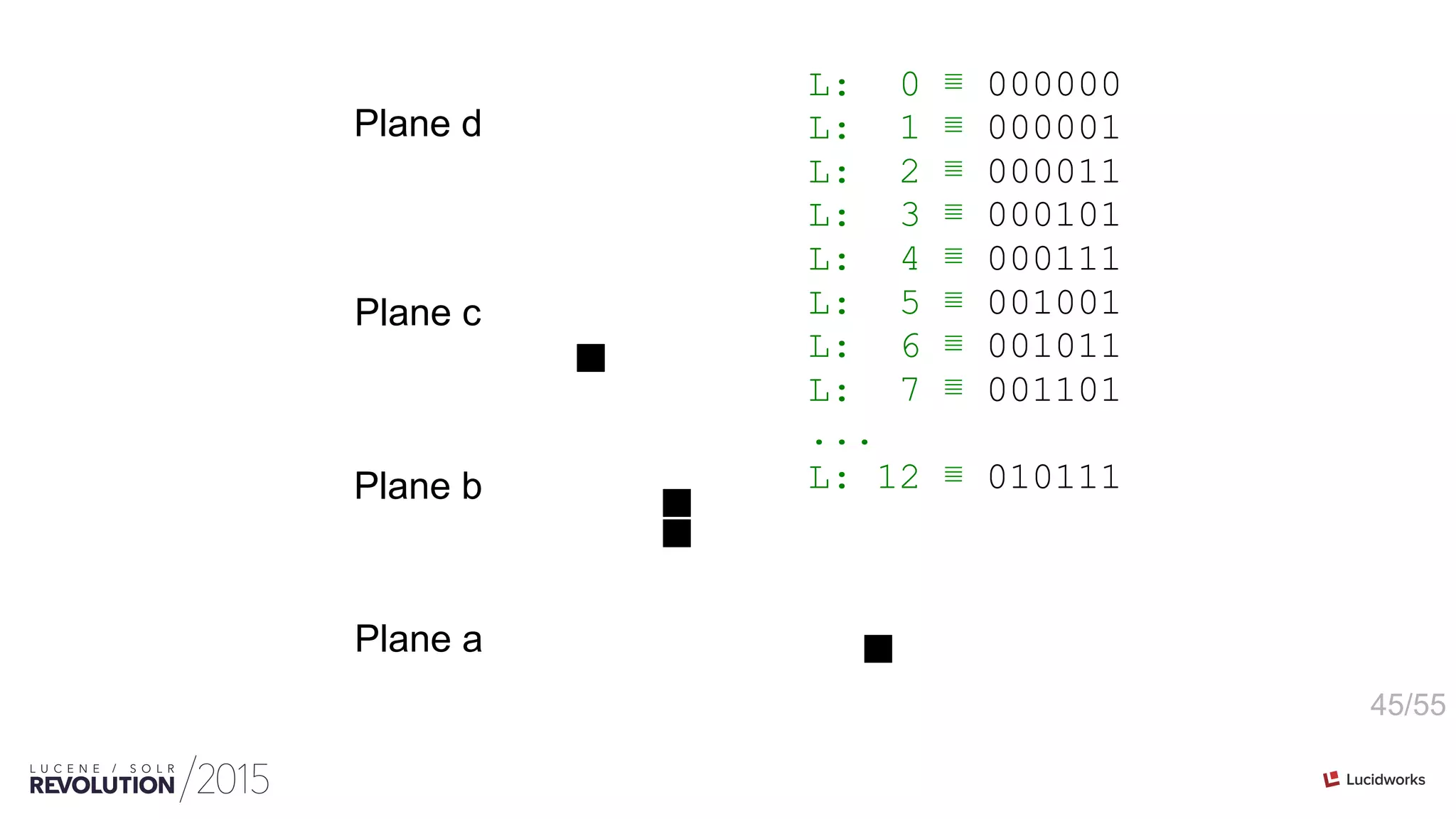
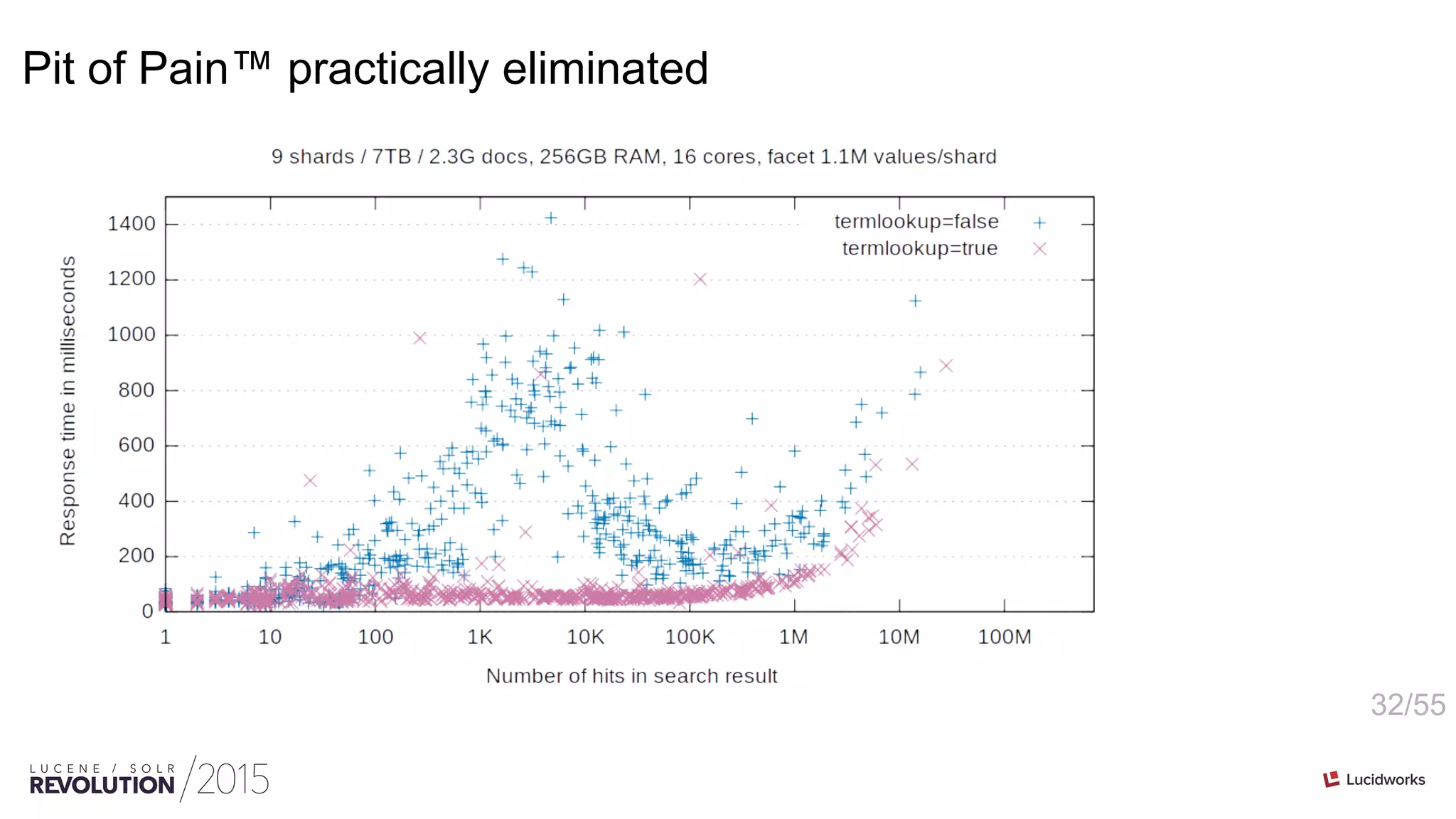
![46/55
Comparison of counter structures
domain: 4 MB
url: 780 MB
links: 2350 MB
domain: 3 MB (72%)
url: 420 MB (53%)
links: 1760 MB (75%)
domain: 1 MB (30%)
url: 66 MB ( 8%)
links: 311 MB (13%)
int[ordinals] PackedInts(ordinals, maxBPV) n-plane-z](https://image.slidesharecdn.com/facetingoptimizationsforsolr-tokeeskildsen-151021185330-lva1-app6892/75/Faceting-Optimizations-for-Solr-Presented-by-Toke-Eskildsen-State-University-Library-Denmark-46-2048.jpg)
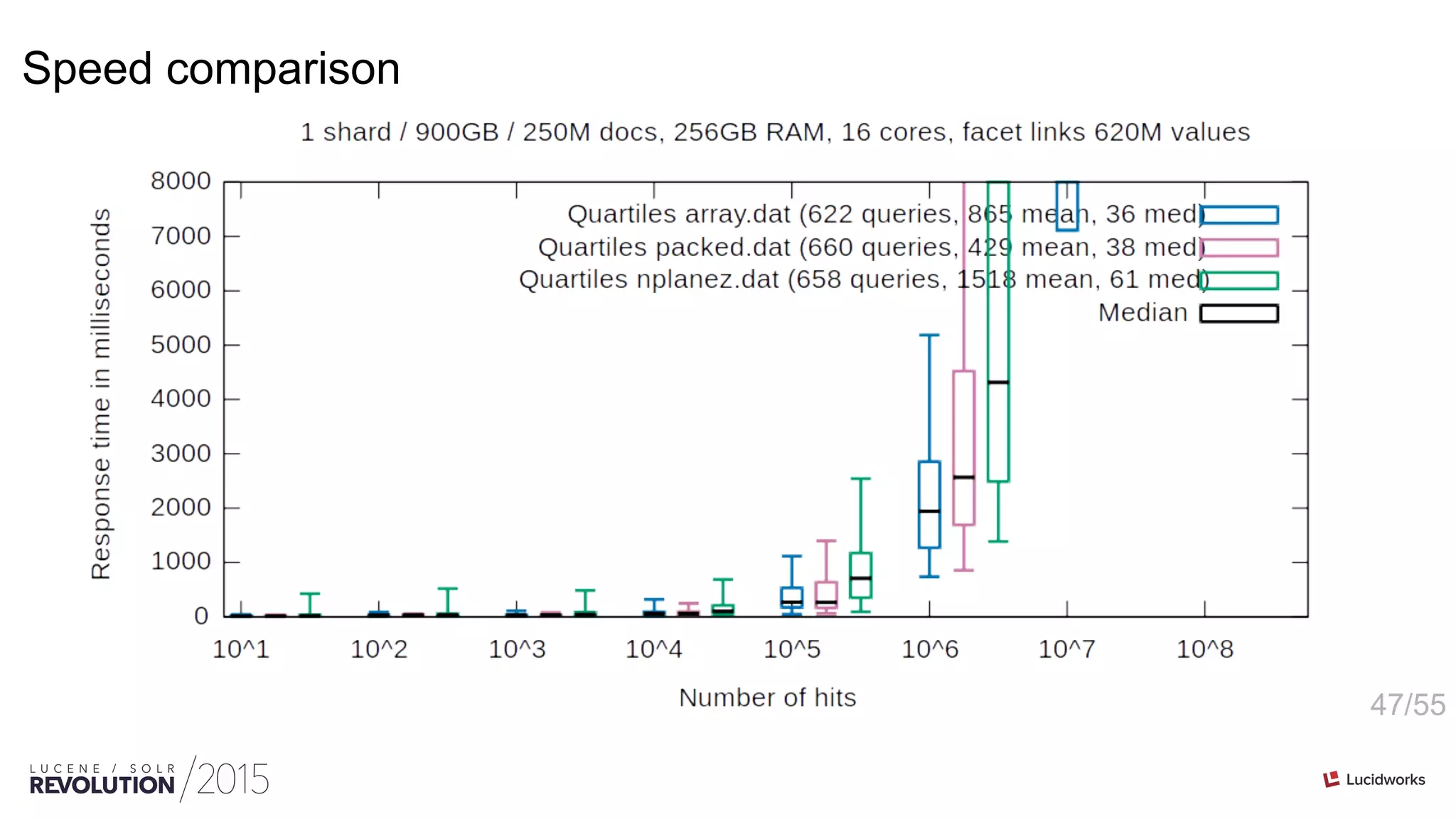


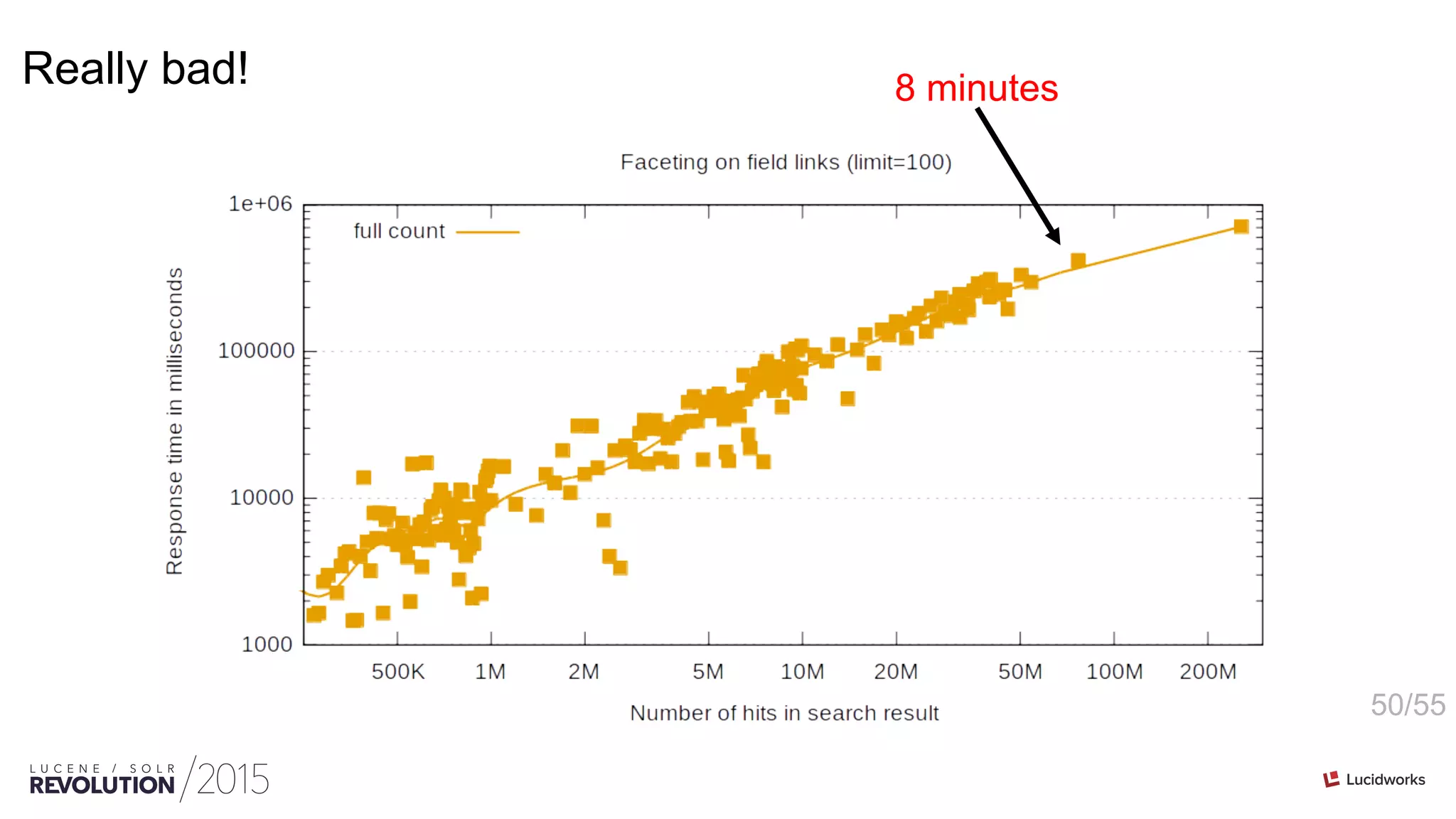

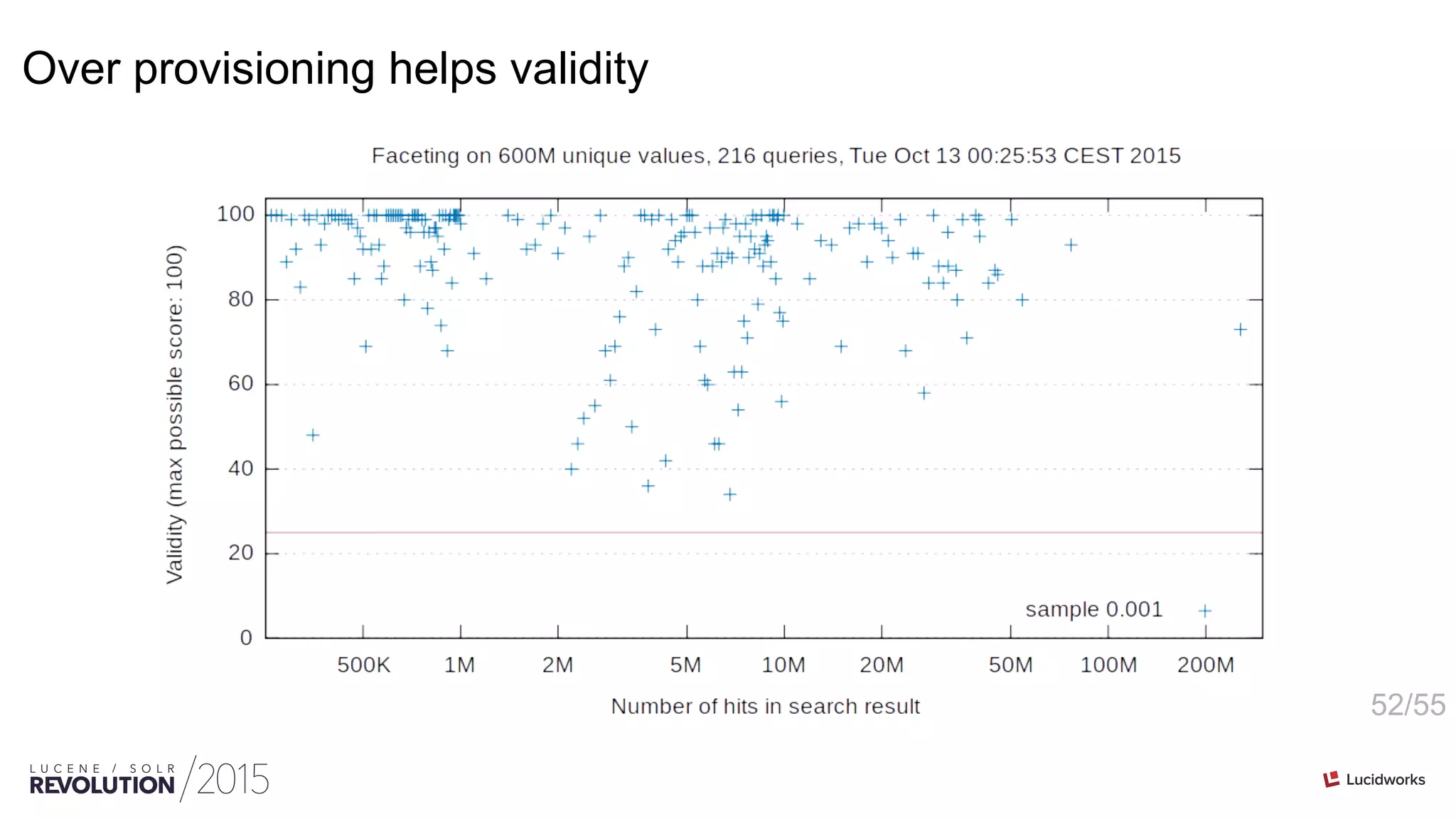
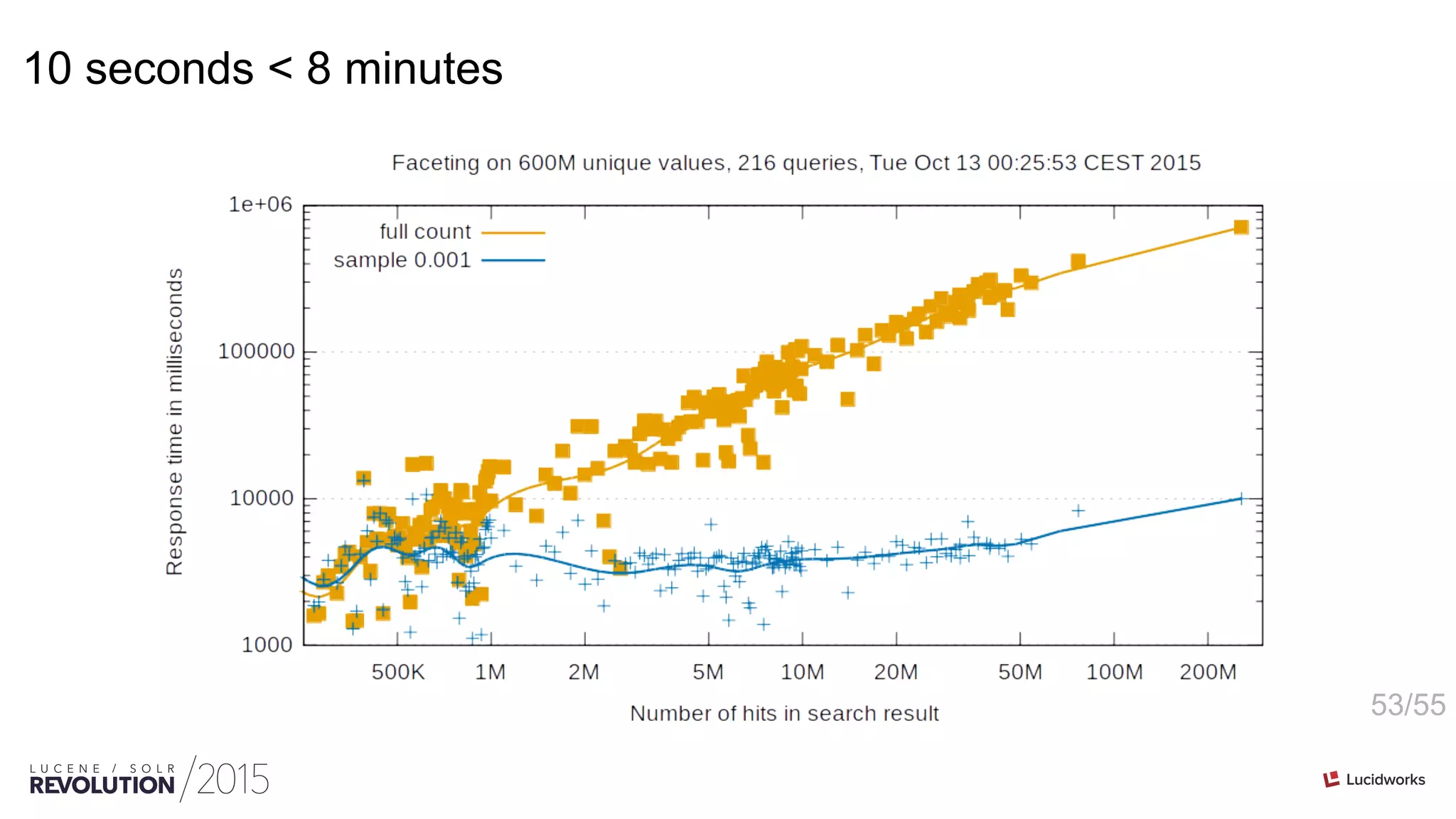



This document discusses optimizations for field faceting in Solr. It begins with an overview of faceting at web scale for the Danish Net Archive. Various techniques for optimizing faceting performance are then presented, including reusing counters, tracking updated counters, caching counters across shards, and using alternative counter structures like PackedInts and n-plane counters. The optimizations are shown to significantly speed up faceting for fields with high cardinality.








































































![[Webinar] Intelligent Policing. Leveraging Data to more effectively Serve Com...](https://cdn.slidesharecdn.com/ss_thumbnails/insightdrivenpolicingv2-201027222903-thumbnail.jpg?width=640&height=640&fit=bounds)





















![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)









