Downloaded 19 times

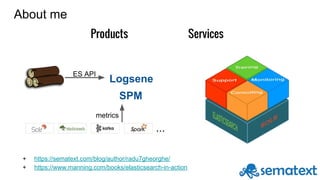


![More on search: the term dictionary and its friends
Term Docs Positions counts,
stored, etc
big 1,2 [0],[2] ...
bucharest 3 [0]
data 1 [1]
fun 1 ...
is 1,3
other 2
text 2
1) Big data is fun
2) Other text
3) Bucharest is big
analysis
big AND data
“big data”](https://image.slidesharecdn.com/introductiontosolr-2-161124090714/85/Introduction-to-solr-5-320.jpg)
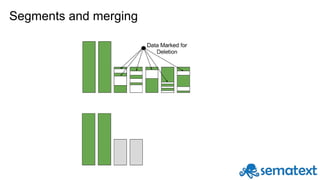
![The [relevancy] score
BM25: bag-of-words based on TF-IDFq=big AND data
big
big
big
big
big
big
I have big big big data
Term
Frequency data
data
Inverse
Document
Frequency
more
occurrences in
the document,
more weight
less
occurrences
in the index,
more weight](https://image.slidesharecdn.com/introductiontosolr-2-161124090714/85/Introduction-to-solr-7-320.jpg)
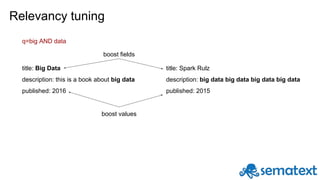
![Back to sorting: where the inverted index fails
Term Docs
1 [star] 1,2,8,5,128
2 7,84,129,
3 3,29,345
4 11,123,455
5 12,14,16,17
Search returned docs
84, 455, 12 and 8
Now sort them by
rating.
¯_(ツ)_/¯](https://image.slidesharecdn.com/introductiontosolr-2-161124090714/85/Introduction-to-solr-9-320.jpg)

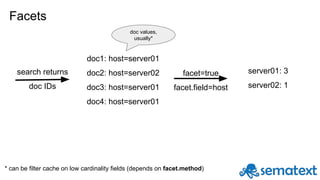
![Facets can be hierarchical
top_genres:{
terms:{
field: genre,
limit: 5,
facet:{
top_authors:{
terms:{
field: author,
limit: 2
"top_genres":{
"buckets":[
{
"val":"Fantasy",
"count":5432,
"top_authors":{ // top authors in the "Fantasy" genre
"buckets":[{
"val":"Mercedes Lackey",
"count":121},
{
"val":"Piers Anthony",
"count":98}
]
}
},
{
"val":"Mystery",
"count":4322,
"top_authors":{ // top authors in the "Mystery" genre
"buckets":[{
"val":"James Patterson",
"count":146},
Can also be numeric/date
ranges or functions like avg,
sum, unique or percentile](https://image.slidesharecdn.com/introductiontosolr-2-161124090714/85/Introduction-to-solr-12-320.jpg)
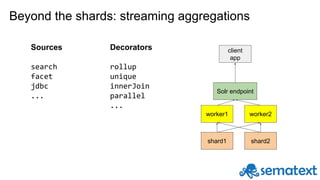
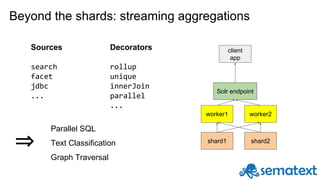
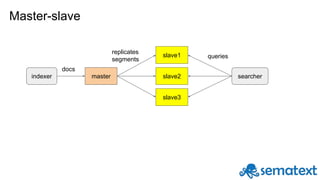
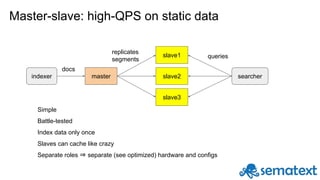
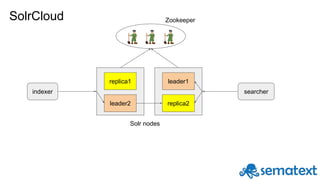
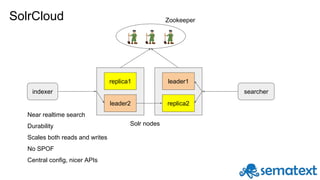



Radu Gheorghe gives an introduction to Solr, an open source search engine based on Apache Lucene. He discusses when Solr would be used, such as for product search, as well as when it may not be suitable, such as for sparse data. The presentation covers how Solr works with inverted indexes and scoring documents, as well as features like facets, streaming aggregations, master-slave and SolrCloud architectures. A demo is offered to illustrate Solr functionality.






























































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)





