Downloaded 38 times





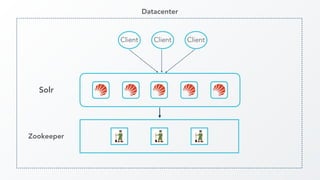
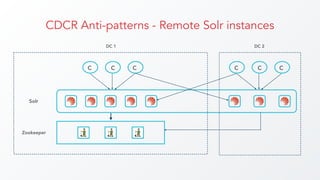
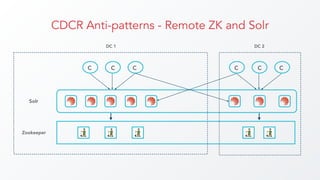
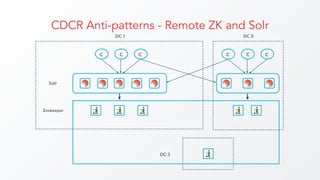


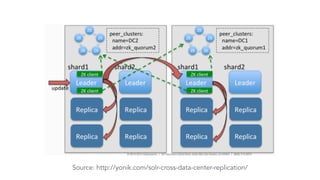

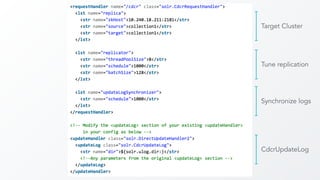


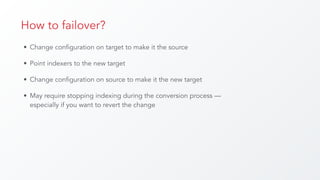









The document discusses cross datacenter replication (CDCR) in Apache Solr 6, detailing its architecture, challenges, setup, limitations, and alternative strategies. It covers asynchronous updates, active/passive setups for disaster recovery, and the necessary configurations for both source and target clusters. Future work suggestions include improved monitoring, dynamic configuration changes, and rate limiting for replication.
































![[Hic2011] using hadoop lucene-solr-for-large-scale-search by systex](https://cdn.slidesharecdn.com/ss_thumbnails/hic2011usinghadoop-lucene-solr-for-large-scale-searchbysystex-111205021544-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)










