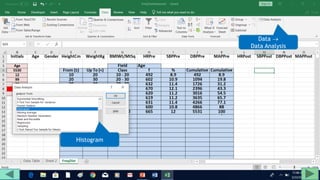
This document provides a step-by-step tutorial for creating a frequency distribution table in Excel. It explains how to:
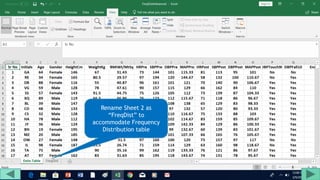
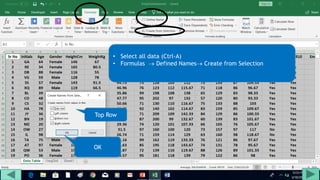
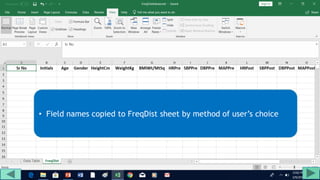
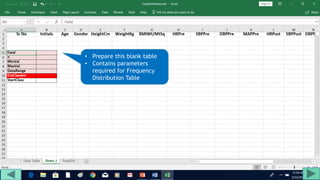
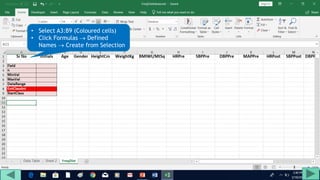
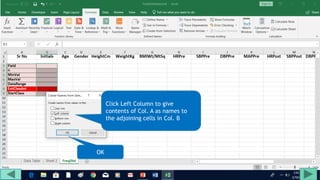
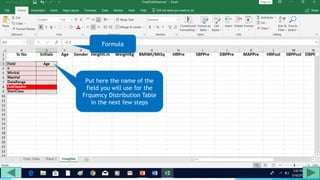
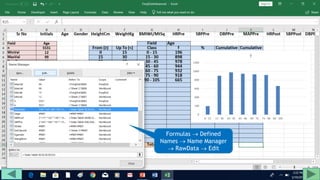
1. Prepare the data by naming columns and creating a "FreqDist" sheet.
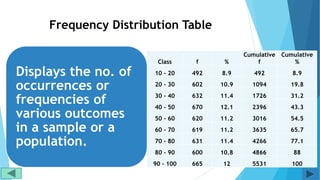
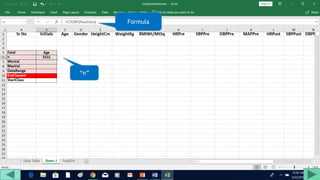
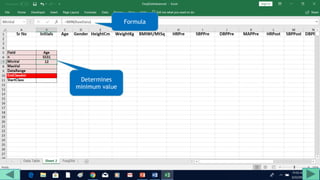
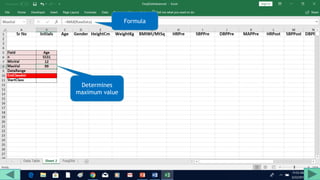
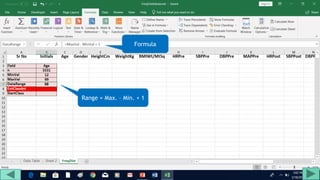
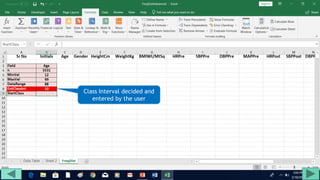
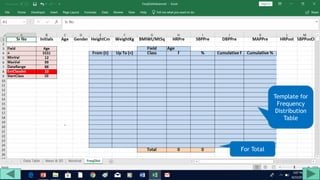
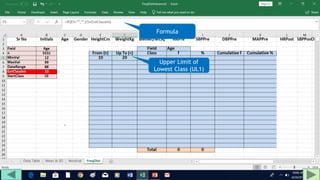
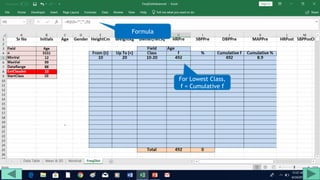
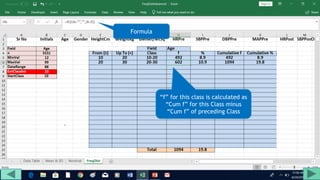
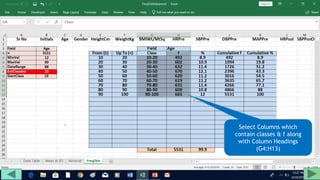
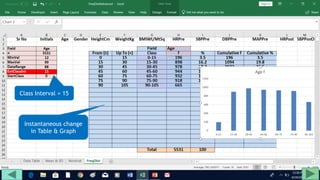
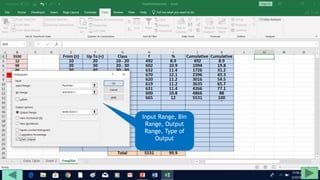
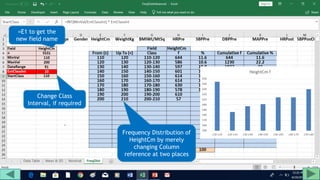
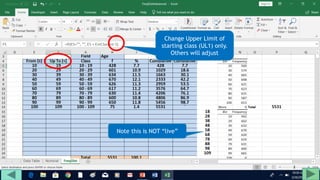
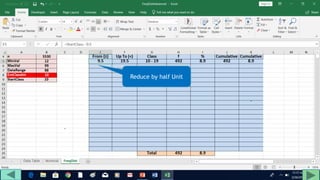
2. Fill out a template table with parameters like number of observations, class interval, and minimum/maximum values.
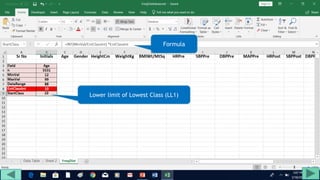
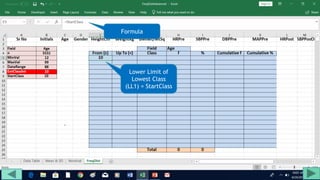
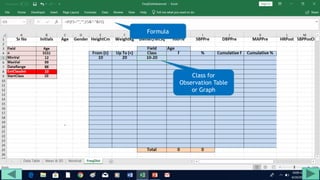
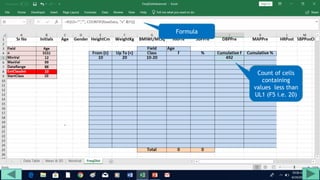
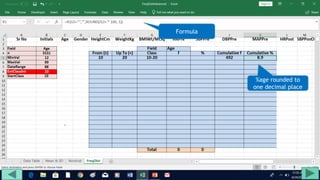
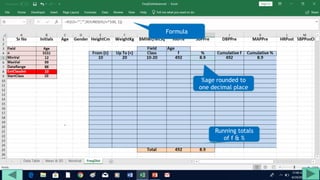
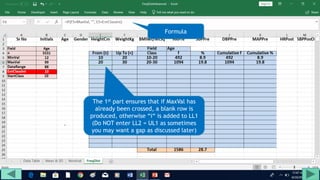
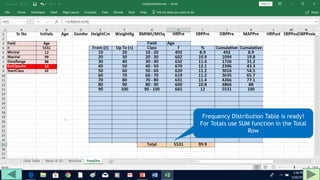
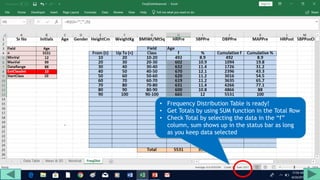
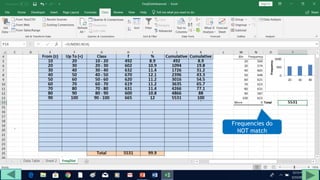
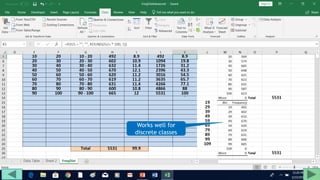
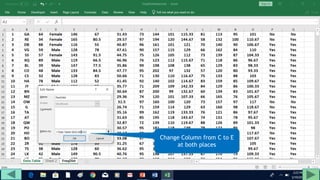
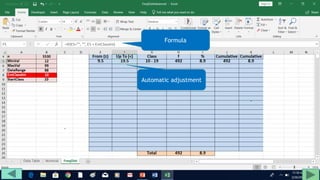
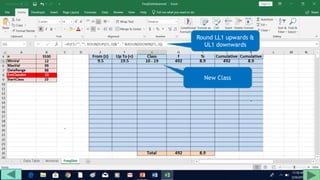
3. Use formulas to determine values like class limits, frequencies, and cumulative percentages.
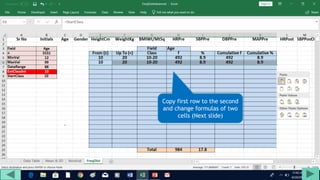
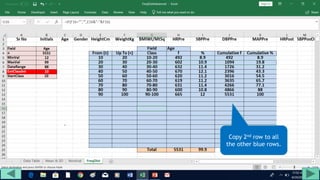
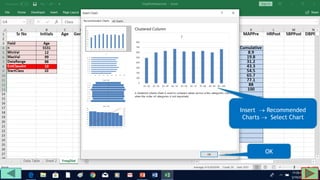
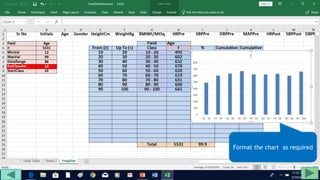
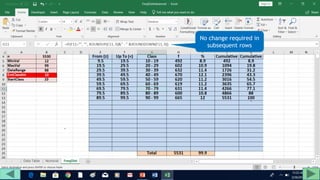
4. Copy formulas down to automatically generate the full distribution table.
The tutorial demonstrates an easy way to analyze numeric data sets in Excel by creating frequency distributions.