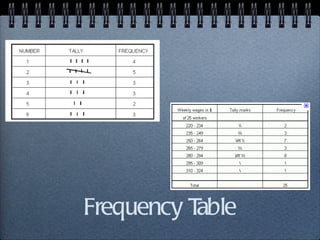
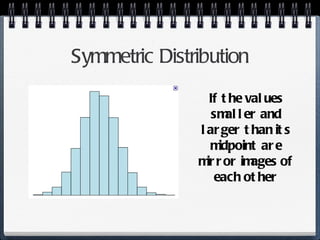
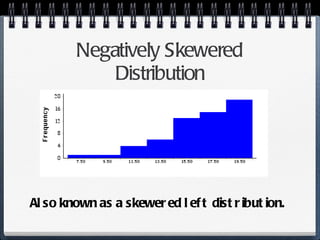
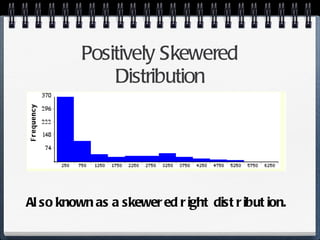
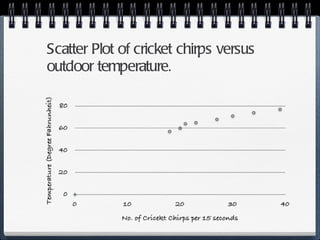
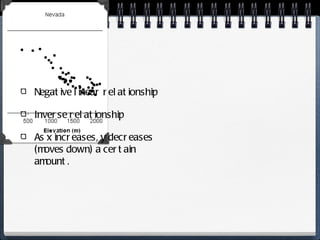
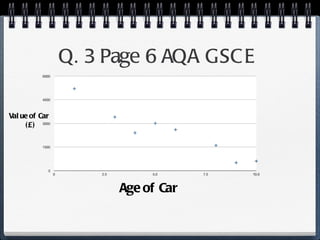
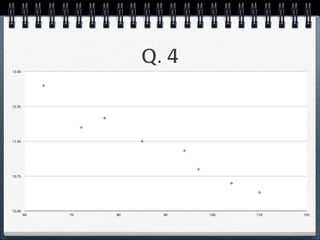
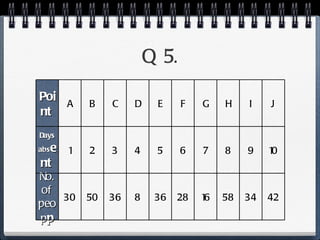
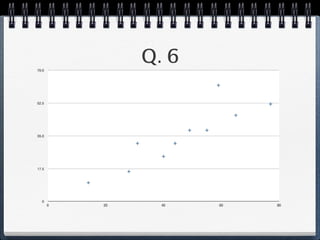
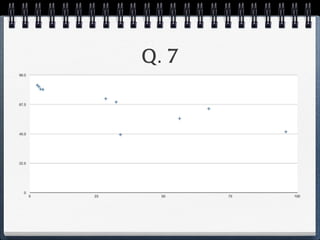
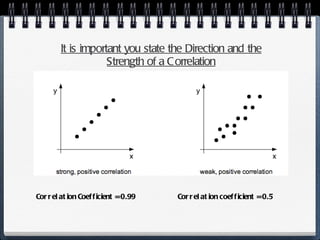
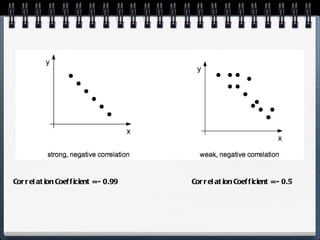
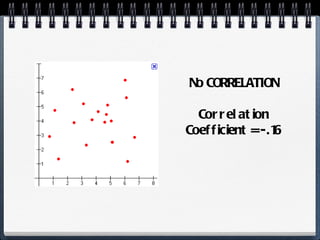
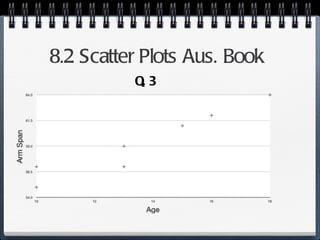
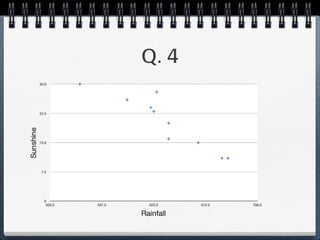
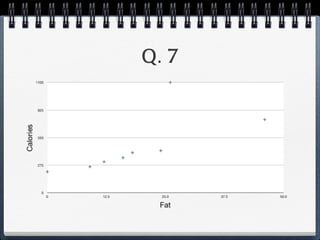
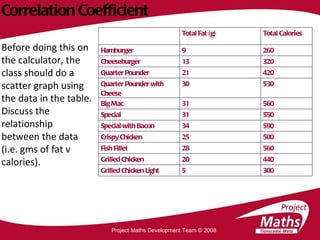
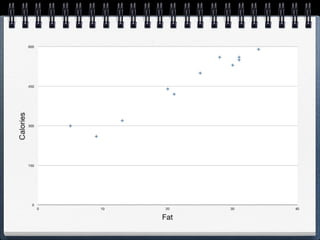
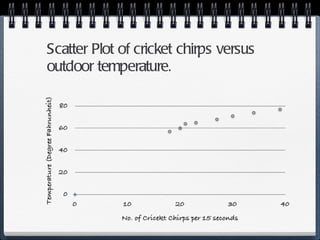
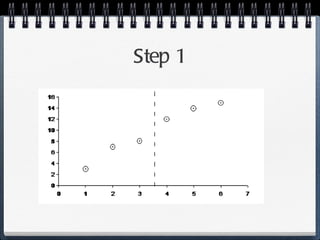
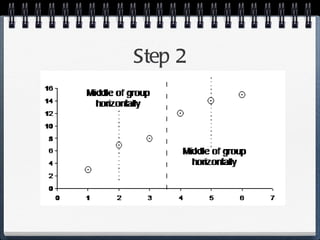
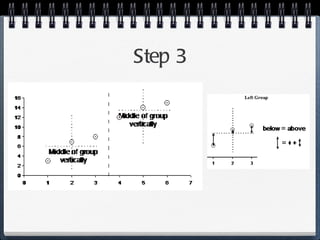
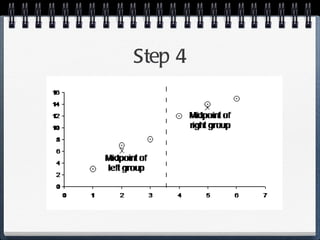
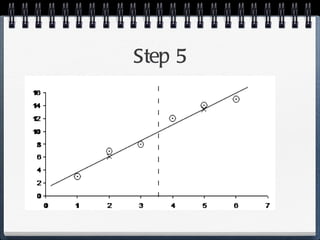
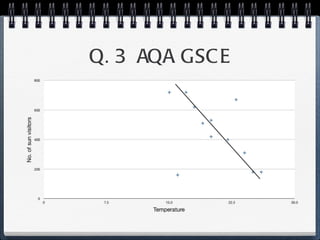
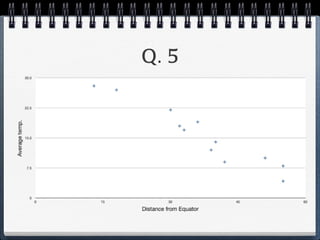
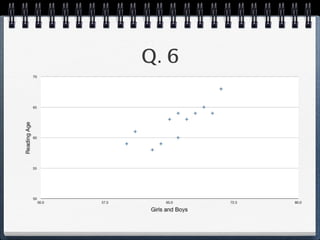
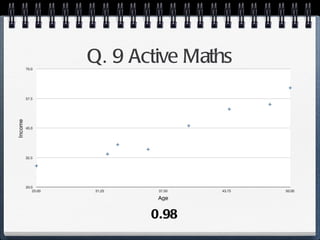
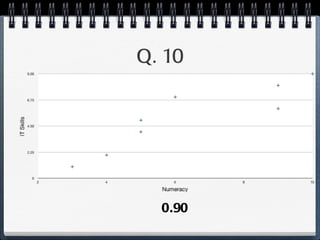
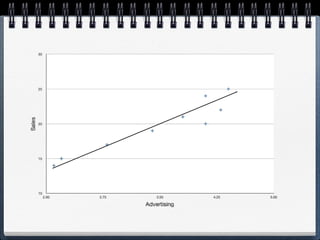
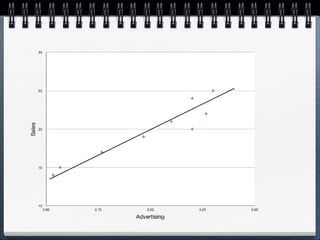
The document discusses different statistical methods for organizing and summarizing data, including frequency tables, stem-and-leaf plots, histograms, and scatter plots. It provides examples of each method and explains how to interpret the results, such as looking for relationships between variables in scatter plots. Key terms defined include correlation, variables, and linear regression lines.


























































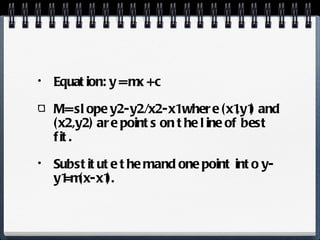




































![Statistics Chapter 01[1]](https://cdn.slidesharecdn.com/ss_thumbnails/statistics-chapter011-1295487514-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![Statistice Chapter 02[1]](https://cdn.slidesharecdn.com/ss_thumbnails/statistice-chapter021-1296091979-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






















































