This document discusses techniques for automatically extracting lines from a digital image. It introduces two common edge detection operators - Sobel and Canny - to identify edges in an image that can then be input to the Hough transform for line detection. It also explores using different filtering masks prior to edge detection and adaptive thresholding to improve results. The identified lines from the Hough transform are then intersected and clustered using k-means to estimate vanishing points for perspective calculation. Experimental validation of the results is also discussed.




















![1.8.1 Reti neurali
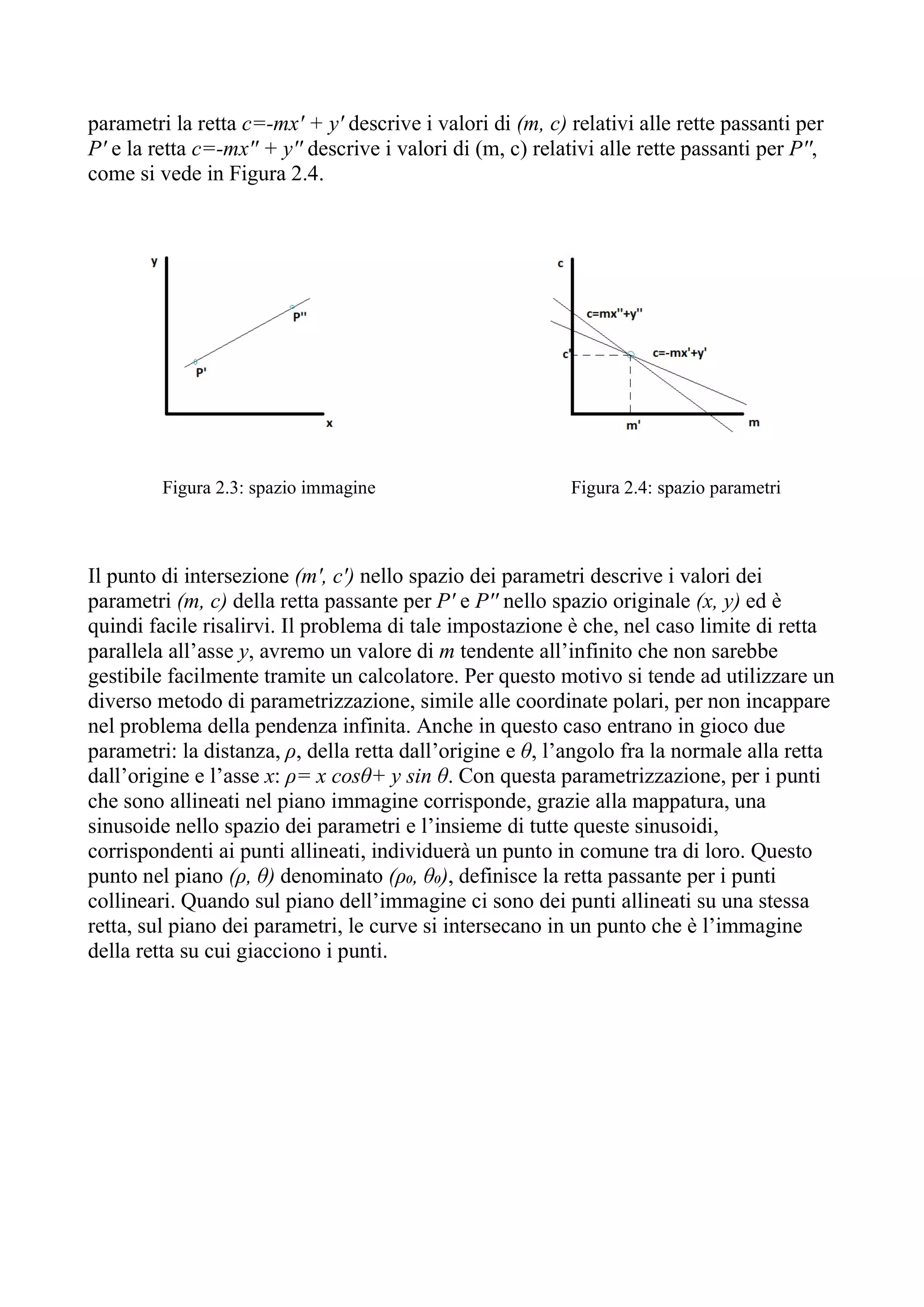
Prima di scegliere la trasformata di Hough, si sono valutate varie tecniche di
estrazione delle linee da un’immagine, in primis quella tramite l’utilizzo delle reti
neurali oppure un affiancamento delle stesse per avvalorare i risultati trovati con altri
algoritmi. Le reti neurali sono degli algoritmi basati sulle connessioni fra il neurone
trasmettitore e quello ricevitore, dove ogni connessione è caratterizzata da un peso
che sarà quello che verrà modificato per ridurre l’errore. Queste reti spesso si basano
su un apprendimento supervised, ovvero vi sarà un external teacher che determinerà
la durata dell’apprendimento, la frequenza di presentazione degli esempi e la misura
degli errori. In pratica mentre si addestra la rete, si presenta un pattern di foto
all’ingresso e si vuole che la rete modifichi l’insieme dei pesi per avere le uscite
desiderate ai nodi di uscita.
Per non appesantire il codice e non occupare eccessiva memoria, si era valutato dal
Paper [2] “Deep Learning for Vanishing Point Detection Using an Inverse Gnomonic
Projection”: la Inverse Gnomonic Projection. Questa è una mappatura che trasforma
il piano dell’immagine illimitato in uno spazio limitato, rendendo in tal modo il punto
di fuga, lontano dal centro dell’immagine, più facile da trattare. L’approccio
consisteva nei seguenti passi: estrazione delle linee, mappatura delle linee nella sfera
gaussiana e visualizzazione dell’immagine. Questa immagine veniva poi usata come
input per un CNN, allenato solo con dati sintetici. Questo CNN dava una previsione
sui possibili punti di fuga. La mappatura era utile al fine di permettere l’utilizzo di
dati sintetici piuttosto che quelli reali, occupando così minore spazio e permettendo di
crearsi i dati da sé.
Però, sebbene questa tecnica offra dei risultati molto soddisfacenti e precisi, non è
adatta al nostro caso principalmente per due motivi. Il primo si basa sul fatto che, per
una questione di compatibilità, il codice deve essere scritto in linguaggio C++ ed
essere coerente con la versione di OpenCV, già utilizzata nel software preesistente
mentre per le reti neurali si usa utilizzare Python oppure le nuove versioni di
OpenCV, per sfruttare al meglio e non appesantire troppo il codice.
Il secondo motivo si basa sul fatto che i dati forniti dal codice saranno poi utilizzati in
ambito legale e l’utilizzo delle reti neurali non è avvalorato da tutte le legislazioni
proprio perché è l’utente che decide di addestrare la rete sulla base dei dati che lui
stesso carica, introducendo dunque una parte non oggettiva nel computo delle linee.
1.8.2 Algoritmo Haar-like
Si era valutato anche l’utilizzo di un algoritmo Haar-like[3], che si basa sulla
differenza di intensità luminosa fra aree vicine dell’immagine tramite la Haar
wavelets. Una Haar-like features considera regioni rettangolari adiacenti e somma le](https://image.slidesharecdn.com/estrazioneautomaticadellelineeinunimmaginedigitale-211203161154/75/Estrazione-automatica-delle-linee-in-un-immagine-digitale-21-2048.jpg)












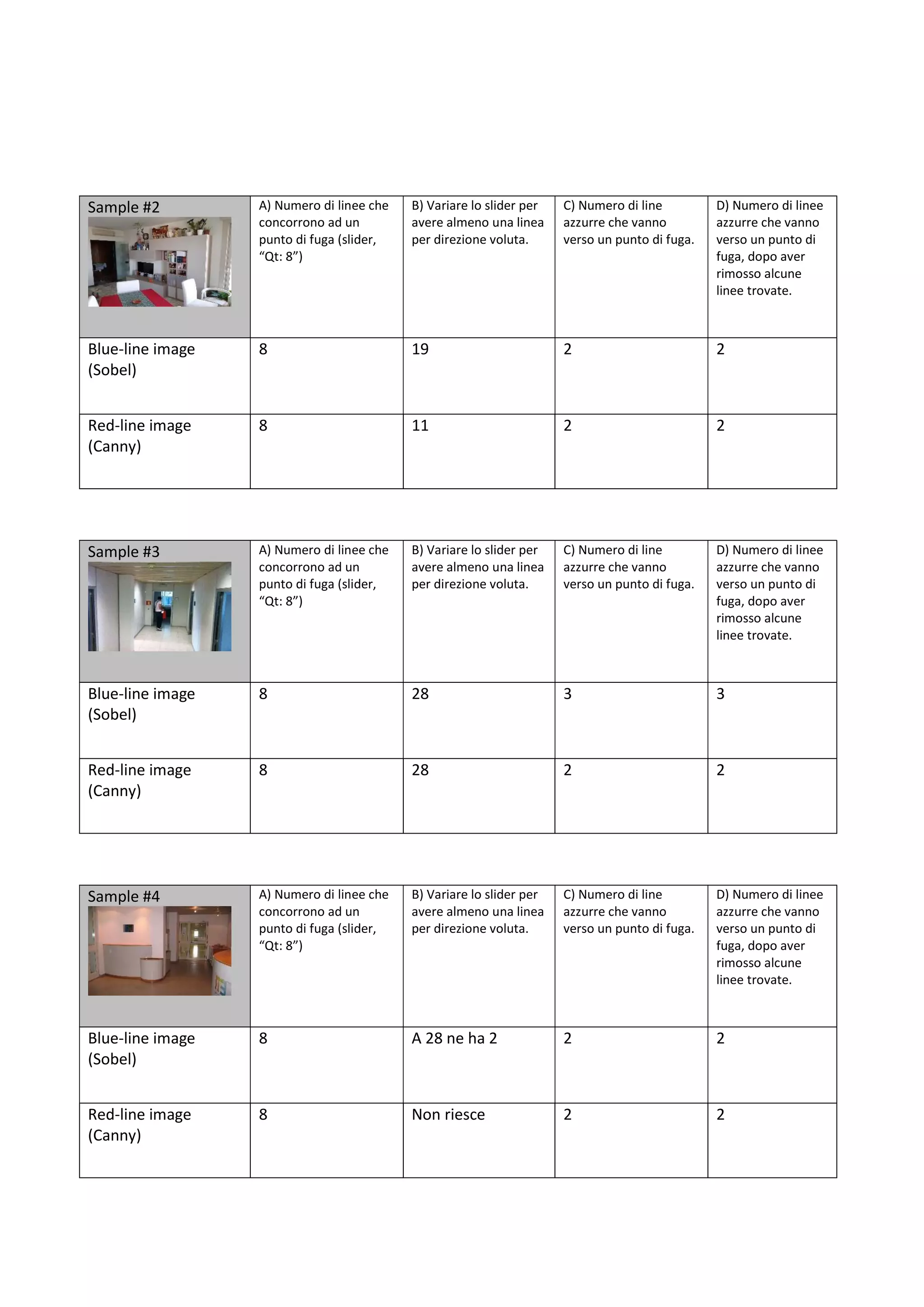
![Fig. 3.3 Confronto intersezioni utilizzando Canny (a sinistra) e Sobel (a destra)
Una volta trovati i punti d’intersezione, si inseriscono le rispettive coordinate in un
vettore, che sarà la base di partenza per l’algoritmo di clustering.
3.4 Tecniche di clustering
Una volta trovati tutti i punti di intersezione fra le rette presenti nell’immagine, si
prosegue nella ricerca delle zone con una maggiore densità di punti. Lo scopo di tale
ricerca è l’individuazione delle tre direzioni principali di convergenza delle linee per
trovare i punti di fuga dell’immagine. Per fare questo si utilizzano degli algoritmi di
clustering, dove il clustering consiste nel raggruppare oggetti in classi omogenee. Un
cluster è un insieme di oggetti che presentano tra loro delle similarità, mentre per
contro presentano dissimilarità con oggetti in altri cluster. Come input nell’algoritmo
verrà dato un certo numero di elementi, che poi saranno suddivisi in base alle loro
similarità. In output avremo invece un certo numero di cluster, trovati dall’algoritmo.
In molti approcci, come pure nel nostro, questa similarità è concepita in termini di
distanza in uno spazio multidimensionale.
Vi sono varie tecniche di clustering, inizialmente suddivise in metodi aggregativi o
bottom-up e metodi divisivi o top-down. Nel primo caso si considera ogni singolo
dato come un cluster a sé e a successive iterazioni si raggruppa in base alla
somiglianza agli altri cluster; mentre il secondo considera inizialmente l’insieme dei
dati come un unico cluster e per successive iterazioni e confronti, li divide in un
numero minore di cluster.
Inoltre, vi sono altre due classificazioni importanti [3] in base all’algoritmo che si
vuole utilizzare: clustering partizionale e clustering gerarchico. Il primo definisce
l’appartenenza ad un gruppo in base alla distanza da un punto rappresentativo del
cluster (centroide, medioide, ecc…), dopo aver prefissato il numero di gruppi della
partizione. L’algoritmo gerarchico invece costruisce una gerarchia di partizioni
caratterizzata da un numero crescente o decrescente di gruppi. Da queste due](https://image.slidesharecdn.com/estrazioneautomaticadellelineeinunimmaginedigitale-211203161154/75/Estrazione-automatica-delle-linee-in-un-immagine-digitale-35-2048.jpg)












![Bibliografia
[1] Rafael C. Gonzalez - Richard E. Woods, Digital image processing (third edition),
Prentice Hall, 2008.
[2] Richard O.Duda and Peter E.Hart “Use of the Hough transformation to detect
lines and curves in pictures”, January 1972.
[2] Florian Kluger1 - Hanno Ackermann1 - Michael Ying Yang2 - Bodo
Rosenhahn1, “Deep Learning for Vanishing Point Detection Using an Inverse
Gnomonic Projection”, Leibniz Universit ̈at Hannover - University of Twente
[3] Heechul Jung – Junggon Min – Junmo Kim, “An efficient lane detection
algorithm for lane departure detection”, June 2013, Conference: Intelligent Vehicles
Symposium (IV), 2013 IEEE
[4] A. Rezzani, “Business Intelligence. Processi, metodi, utilizzo in azienda”,
APOGEO, 2012
[5] Mehmed Kantardzic “Data Mining: Concepts, Models, Methods, and
Algorithms”, John Wiley & Sons, 2003
[6] Jiawei Han, Micheline Kamber, “Data Mining:Concepts and Techniques” Second
Edition, Morgan Kaufmann Publishers, 2006
[7] https://docs.opencv.org/3.4.8/d9/df8/tutorial_root.html
[8] MacQueen J.B., Some Methods for Classification Analysis of Multivariate
Observations, Proceedings of 5-th Berkeley Symposium on Mathematical Statistics
and Probability, Berkeley, 1967, University of California Press, 1:281-297.
[9] Roiger R.J., Geatz M.W., Introduzione al Data Mining, McGraw-Hill, 2004.
[10] Tan P., Steinbach M., Kumar V., Introduction to Data Mining, Pearson Addison
Wesley, 2005.](https://image.slidesharecdn.com/estrazioneautomaticadellelineeinunimmaginedigitale-211203161154/75/Estrazione-automatica-delle-linee-in-un-immagine-digitale-50-2048.jpg)



































































