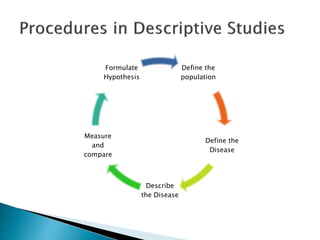
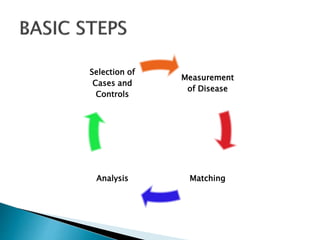
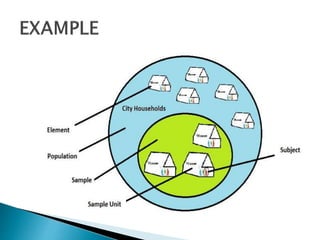
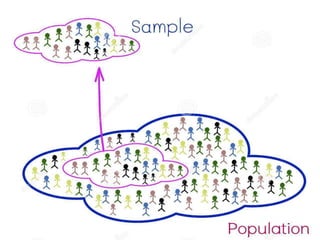
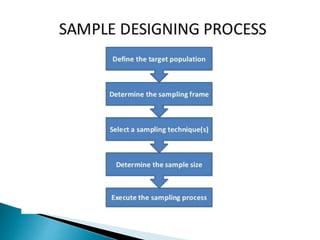
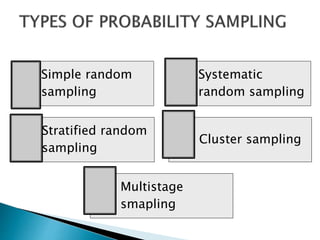
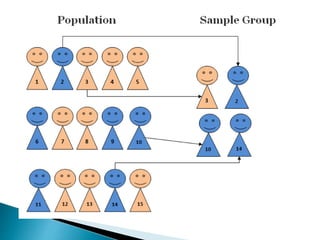
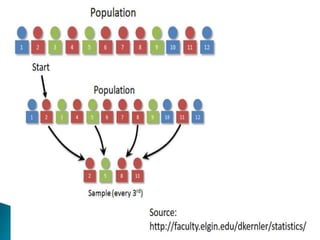
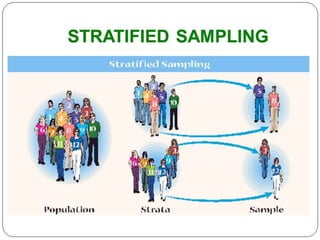
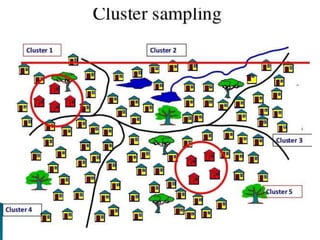
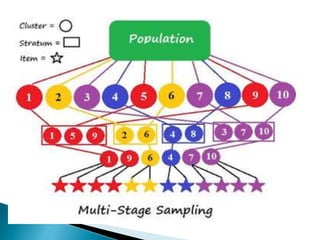
This document discusses various concepts related to epidemiology and epidemiological study designs. It defines epidemiology and its phases. It discusses observational and experimental study designs including descriptive studies, case-control studies, cohort studies, randomized control trials and field trials. It explains key epidemiological terms like target population, sampling, and probability and non-probability sampling techniques.




































































































































![CTEV [ clubfoot] DR ARUN LAL ,DR MOHAMED ASHRAF travancore medical college k...](https://cdn.slidesharecdn.com/ss_thumbnails/ctevclubfootdrarunlaldrmohamedashraftravancoremedicalcollegekollamkeralaindia-260208063247-18fc466c-thumbnail.jpg?width=640&height=640&fit=bounds)













