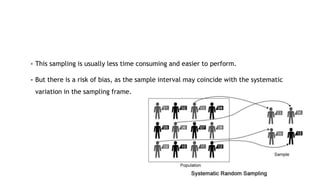
This document provides an overview of key concepts in sampling and statistics. It defines key terms like population, parameter, sample, and sampling error. It discusses different sampling methods like simple random sampling, systematic sampling, stratified sampling, cluster sampling, and multi-stage sampling. It also covers non-probability sampling methods. The document explains how to calculate sampling error and discusses other sources of bias. Overall, it serves as an introduction to important statistical concepts for sample surveys and studies.