Download to read offline







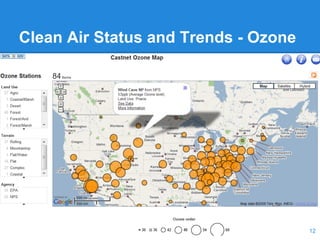

















![Example Polynomial
select ?lat ?long where {
?a [] ``Eiffel Tower''.
?a inCountry FR .
?a lat ?lat .
?a long ?long .
}
(l1 ⊕ l2 ⊕ l3) ⊗ (l4 ⊕ l5) ⊗ ( l6 ⊕ l7) ⊗ (l8 ⊕ l9) 39](https://image.slidesharecdn.com/pdfid1qk81or5u8gkk0gvdgnwr-pqajotpxcxtodrgq-mwkipageidga15fe47db00attachmentfalseoptssb1tsnspp1ss365-151006143450-lva1-app6892/85/Efficient-Scalable-and-Provenance-Aware-Management-of-Linked-Data-38-320.jpg)









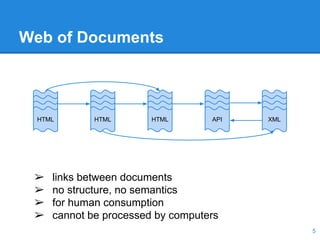
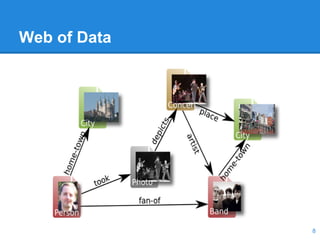
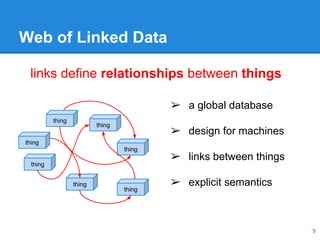
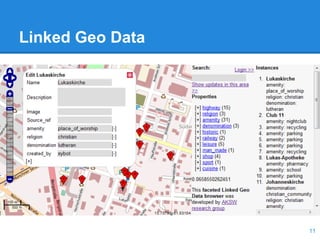
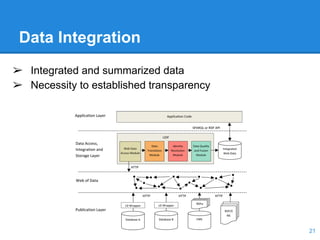
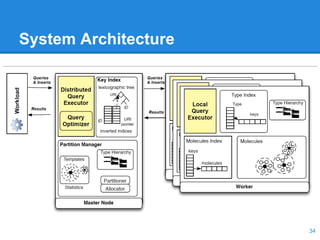
This document discusses the management of linked data, emphasizing the need for efficient, scalable, and provenance-aware systems. It introduces new techniques for data co-location and partitioning to improve query processing in the cloud and highlights the importance of data provenance for ensuring quality and trustworthiness. Additionally, it outlines a distributed linked data management system and various query execution strategies that utilize provenance information.































































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)




