
Downloaded 20 times




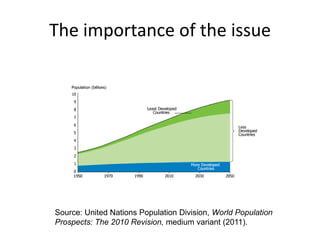
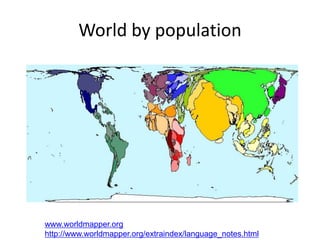

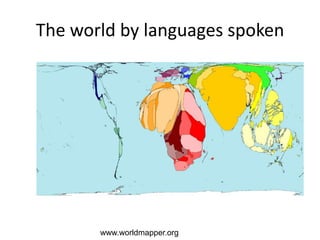

















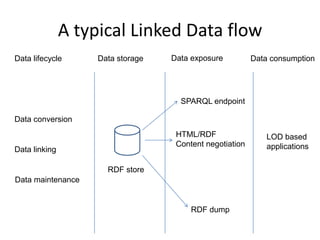
















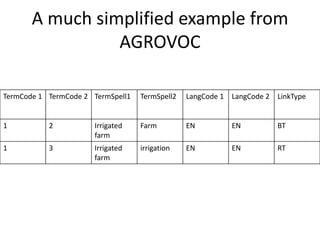























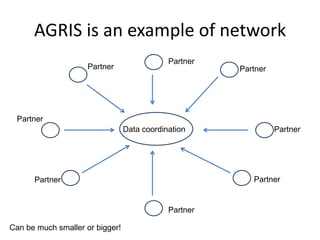




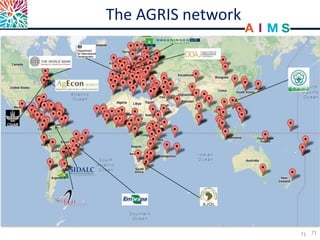

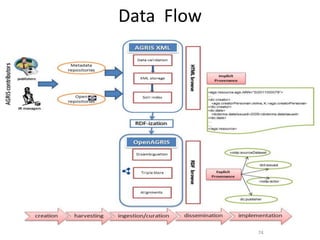
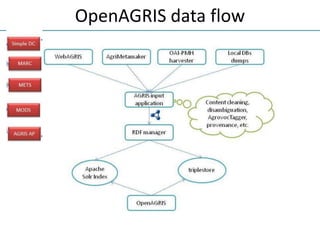


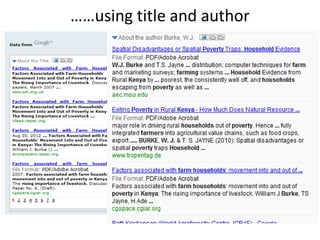

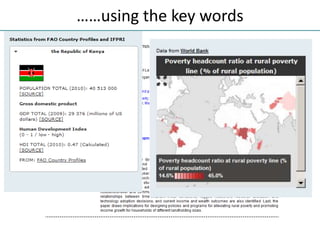





The NISO/DCMI webinar on September 25, 2013, discussed the implementation of linked data in developing countries with limited resources. Key topics included the difficulties of data generation, the significance of using standard vocabularies, and the importance of collaboration among institutions to overcome challenges. The discussion highlighted that linked data technologies must become more accessible and resource-efficient to encourage adoption in low-resource contexts.























































































