Downloaded 23 times



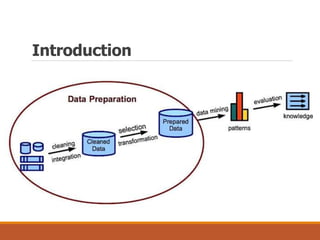









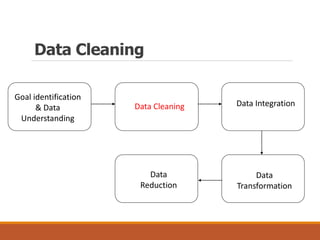
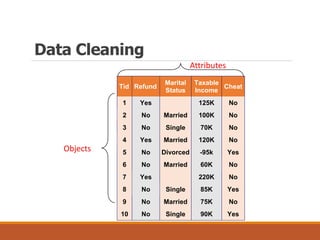

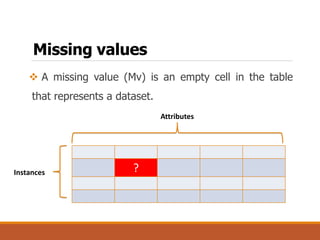




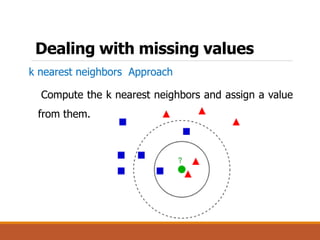



This document discusses data preparation and processing for data mining. It covers topics like domain expertise, goal identification, data understanding, and data cleaning. Data cleaning involves handling missing values, noisy data, and inconsistent data. Common techniques for missing values include ignoring records, manually filling in values, replacing with attribute means, and using k-nearest neighbors. The goal of data cleaning is to increase the accuracy of data mining by preparing raw data for analysis.























































































