Downloaded 75 times



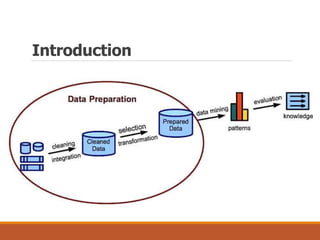









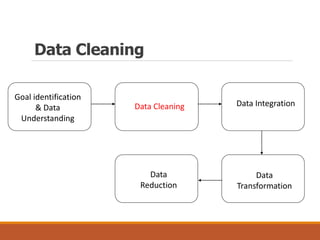
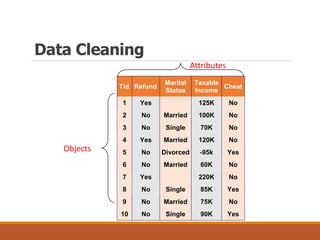

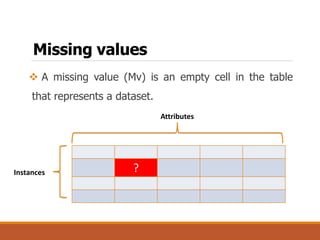




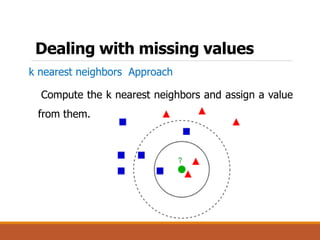




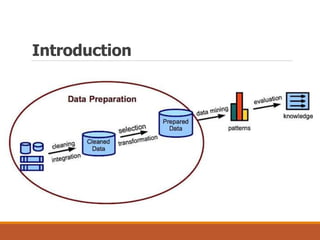







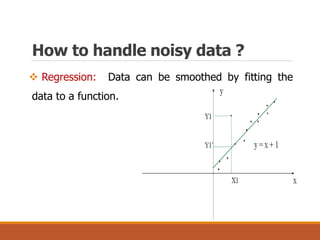


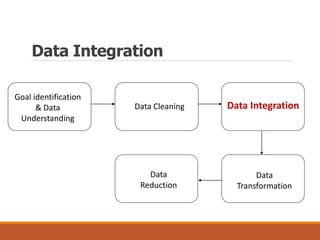



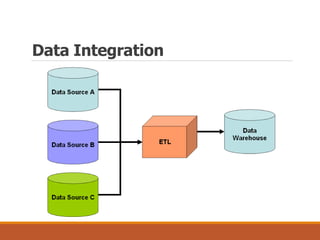



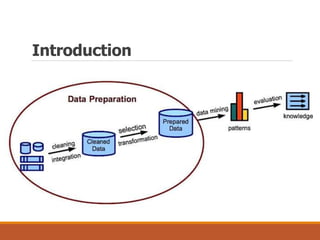







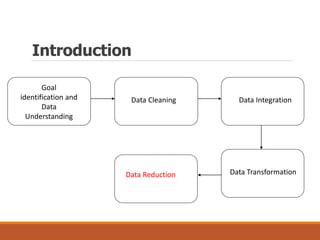
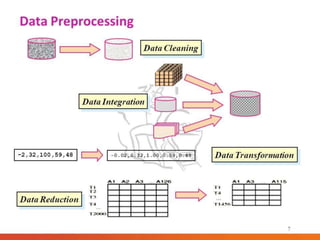
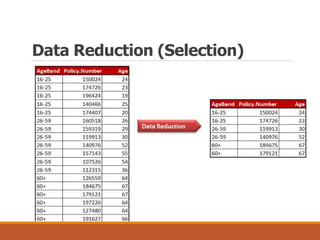














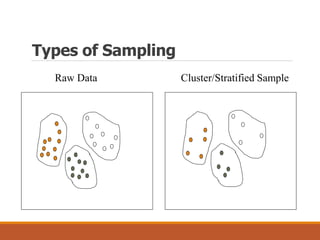




This document provides an overview of key aspects of data preparation and processing for data mining. It discusses the importance of domain expertise in understanding data. The goals of data preparation are identified as cleaning missing, noisy, and inconsistent data; integrating data from multiple sources; transforming data into appropriate formats; and reducing data through feature selection, sampling, and discretization. Common techniques for each step are outlined at a high level, such as binning, clustering, and regression for handling noisy data. The document emphasizes that data preparation is crucial and can require 70-80% of the effort for effective real-world data mining.























































































