Downloaded 33 times








![• Now ifNow if we take the expected valuewe take the expected value of (2.4.1) on both sides, we obtainof (2.4.1) on both sides, we obtain
• E(YE(Yii | X| Xii) = E[E(Y | X) = E[E(Y | Xii)] + E(u)] + E(uii | X| Xii))
• == E(Y | XE(Y | Xii) + E(u) + E(uii | X| Xii)) (2.4.4)(2.4.4)
• Where expected value of a constant is that constant itself.Where expected value of a constant is that constant itself.
• SinceSince E(YE(Yii | X| Xii)) is the same thing asis the same thing as E(Y | XE(Y | Xii),), Eq. (2.4.4) implies thatEq. (2.4.4) implies that
• E(uE(uii | X| Xii) = 0) = 0 (2.4.5)(2.4.5)
• Thus, the assumption that the regression line passes through the conditionalThus, the assumption that the regression line passes through the conditional
means ofmeans of Y implies that theY implies that the conditional mean valuesconditional mean values ofof uuii (conditional upon(conditional upon
the giventhe given X’sX’s)) are zeroare zero..
• It is clear thatIt is clear that
• E(Y | XE(Y | Xii) = β) = β11 + β+ β22XXii (2.2.2)(2.2.2)
• andand
• YYii == ββ11 + β+ β22XXii + u+ uii (2.4.2)(2.4.2) BetterBetter
• are equivalent forms ifare equivalent forms if E(uE(uii | X| Xii) = 0.) = 0.](https://image.slidesharecdn.com/econometricsch3-160908053031/85/Econometrics-ch3-13-320.jpg)












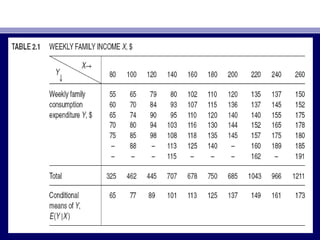
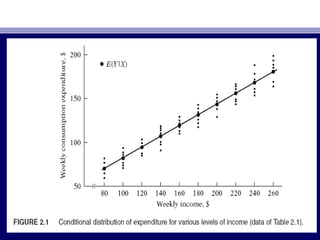
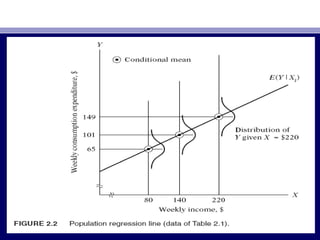
This document provides an overview of two-variable regression analysis and the concept of the population regression function. It discusses how regression analysis is used to estimate the mean value of the dependent variable based on the independent variable. It introduces a hypothetical example using family income and consumption expenditure data. It defines key concepts like the population regression line and function, and explains how the regression model specifies the dependent variable as a linear function of the independent variables plus a stochastic disturbance term to account for omitted variables.























































































