Downloaded 12 times







![• Substitution of (5.3.2) into (5.3.3)Substitution of (5.3.2) into (5.3.3) YieldsYields
• Rearranging (5.3.4), we obtainRearranging (5.3.4), we obtain
• Pr [Pr [βˆβˆ22 −− tt α/2α/2 se (se (βˆβˆ22) ≤ β) ≤ β22 ≤ βˆ≤ βˆ22 ++ ttα/2α/2 se (se (βˆβˆ22)] = 1 − α)] = 1 − α (5.3.5)(5.3.5)
• Equation (5.3.5) provides a 100(1 −Equation (5.3.5) provides a 100(1 − α) percent confidence interval for βα) percent confidence interval for β22,,
which can be written more compactly aswhich can be written more compactly as
• 100(1 −100(1 − α)% confidence interval for βα)% confidence interval for β22::
• βˆβˆ22 ±± ttα/2α/2 se (se (βˆ2)βˆ2) (5.3.6)(5.3.6)
• Arguing analogously, and using (4.3.1) and (4.3.2), we can then write:Arguing analogously, and using (4.3.1) and (4.3.2), we can then write:
• Pr [Pr [βˆβˆ11 −− ttα/2α/2 se (se (βˆβˆ11) ≤ β) ≤ β11 ≤ βˆ≤ βˆ11 ++ ttα/2α/2 se (se (βˆβˆ11)] = 1 − α)] = 1 − α (5.3.7)(5.3.7)
• or, more compactly,or, more compactly,
• 100(1 −100(1 − α)% confidence interval for β1:α)% confidence interval for β1:
• βˆβˆ11 ±± ttα/2α/2 se (se (βˆβˆ11)) (5.3.8)(5.3.8)](https://image.slidesharecdn.com/econometricsch6-160908053047/85/Econometrics-ch6-8-320.jpg)










![• The confidence-interval statementsThe confidence-interval statements such as the following can be made:such as the following can be made:
• Pr [−tPr [−tα/2α/2 ≤≤ ((βˆβˆ22 − β*− β*22)/se ()/se (βˆβˆ22) ≤) ≤ ttα/2α/2 ]=]= 1 − α1 − α (5.7.1)(5.7.1)
• wherewhere β*β*22 is the value ofis the value of ββ22 under Hunder H00.. Rearranging (5.7.1), we obtainRearranging (5.7.1), we obtain
• Pr [Pr [β*β*22 − t− tα/2α/2 se (se (βˆ2) ≤ βˆβˆ2) ≤ βˆ22 ≤ β*≤ β*22 + t+ tα/2α/2 se (se (βˆβˆ22)] = 1 − α)] = 1 − α (5.7.2)(5.7.2)
• which gives the confidence interval inwhich gives the confidence interval in with 1 − α probability.with 1 − α probability.
• (5.7.2) is known as(5.7.2) is known as the region of acceptancethe region of acceptance and theand the region(s) outside theregion(s) outside the
confidence interval is (are)confidence interval is (are) called the region(s) of rejection (ofcalled the region(s) of rejection (of HH00) or the) or the
critical regioncritical region(s).(s).
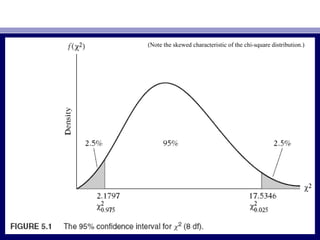
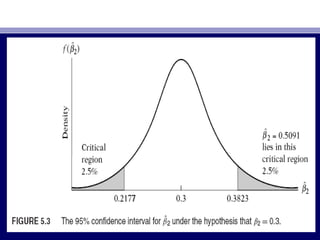
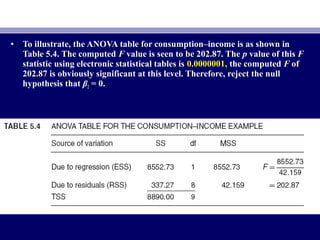
• Using consumption–income example. We know thatUsing consumption–income example. We know that βˆβˆ22 = 0.5091, se (βˆ= 0.5091, se (βˆ22) =) =
0.0357, and df = 8. If we assume α = 5 percent, t0.0357, and df = 8. If we assume α = 5 percent, tα/2α/2 = 2.306. If we let:= 2.306. If we let:
• HH00: β: β22 = β*= β*22 = 0= 0.3 and H1: β.3 and H1: β22 ≠≠ 0.3, (5.7.2) becomes0.3, (5.7.2) becomes
• Pr (0Pr (0.2177 ≤.2177 ≤ βˆβˆ22 ≤ 0.3823) = 0.95≤ 0.3823) = 0.95 (5.7.3)(5.7.3)
• Since the observedSince the observed βˆβˆ22 lies in thelies in the critical region, we reject the null hypothesiscritical region, we reject the null hypothesis
that truethat true ββ22 = 0.3.= 0.3.](https://image.slidesharecdn.com/econometricsch6-160908053047/85/Econometrics-ch6-20-320.jpg)


















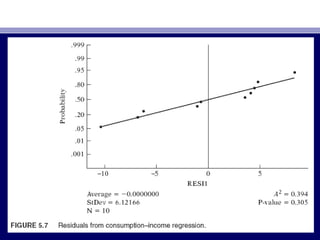
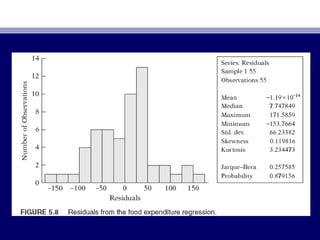
![• Jarque–Bera (JB) Test of Normality.
• The JB test of normality is an asymptotic, or large-sample, test. It is also
based on the OLS residuals. This test first computes the skewness and
kurtosis, measures of the OLS residuals and uses the following test statistic:
• JB = n[S2
/ 6 + (K − 3)2
/ 24] (5.12.1)
• where n = sample size, S = skewness coefficient, and K = kurtosis coefficient.
For a normally distributed variable, S = 0 and K = 3. In that case the value
of the JB statistic is expected to be 0.](https://image.slidesharecdn.com/econometricsch6-160908053047/85/Econometrics-ch6-44-320.jpg)







This document discusses interval estimation and hypothesis testing for two-variable regression models. It defines a confidence interval as a range of values that has a certain probability, such as 95%, of containing the true unknown parameter value based on the point estimate and its standard error. Formulas are provided for constructing 95% confidence intervals for the regression coefficients based on their point estimates, standard errors, and the t-distribution. An example calculates the 95% confidence intervals for the coefficients in a consumption-income regression model.























































































