Downloaded 29 times



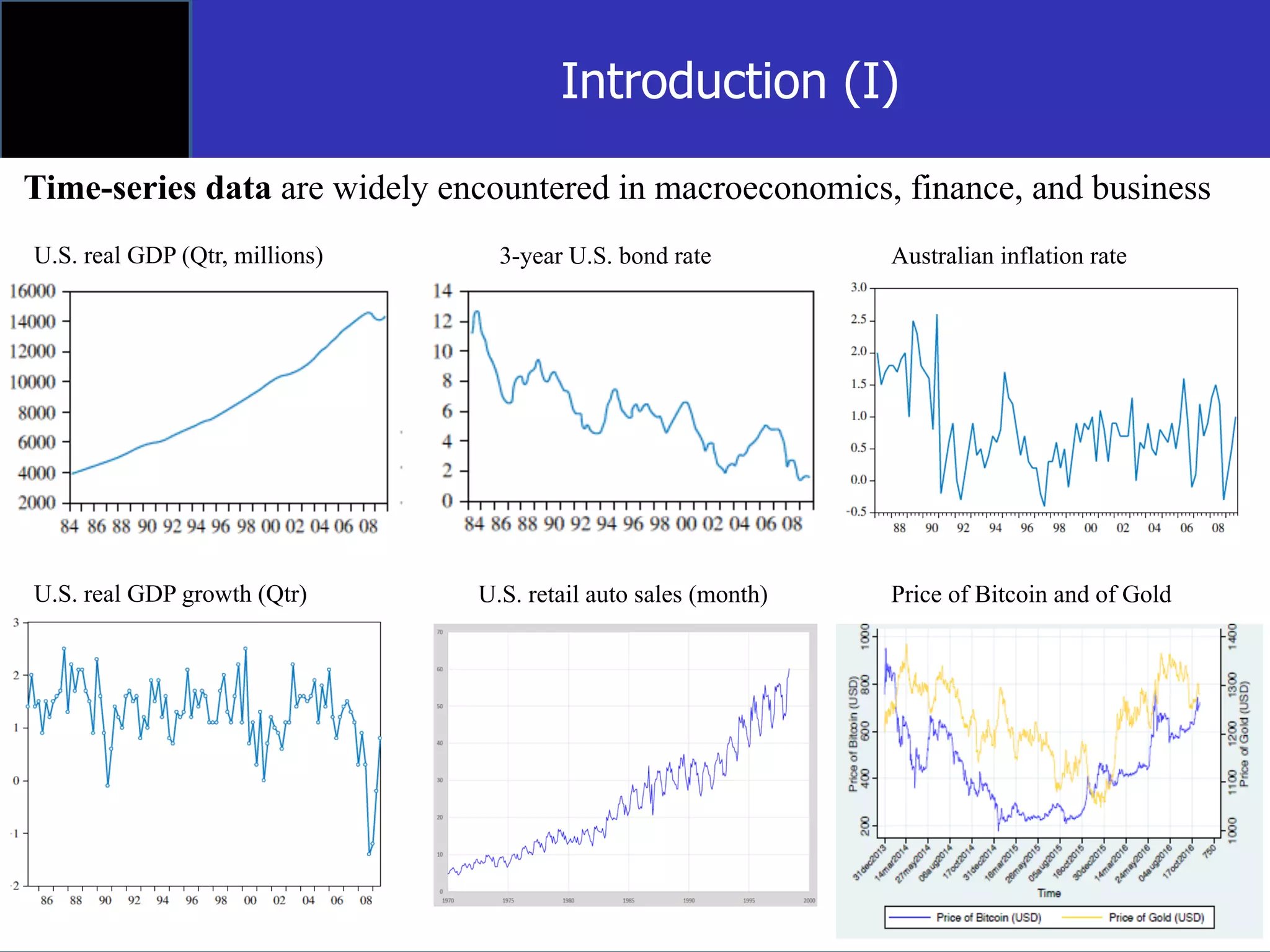

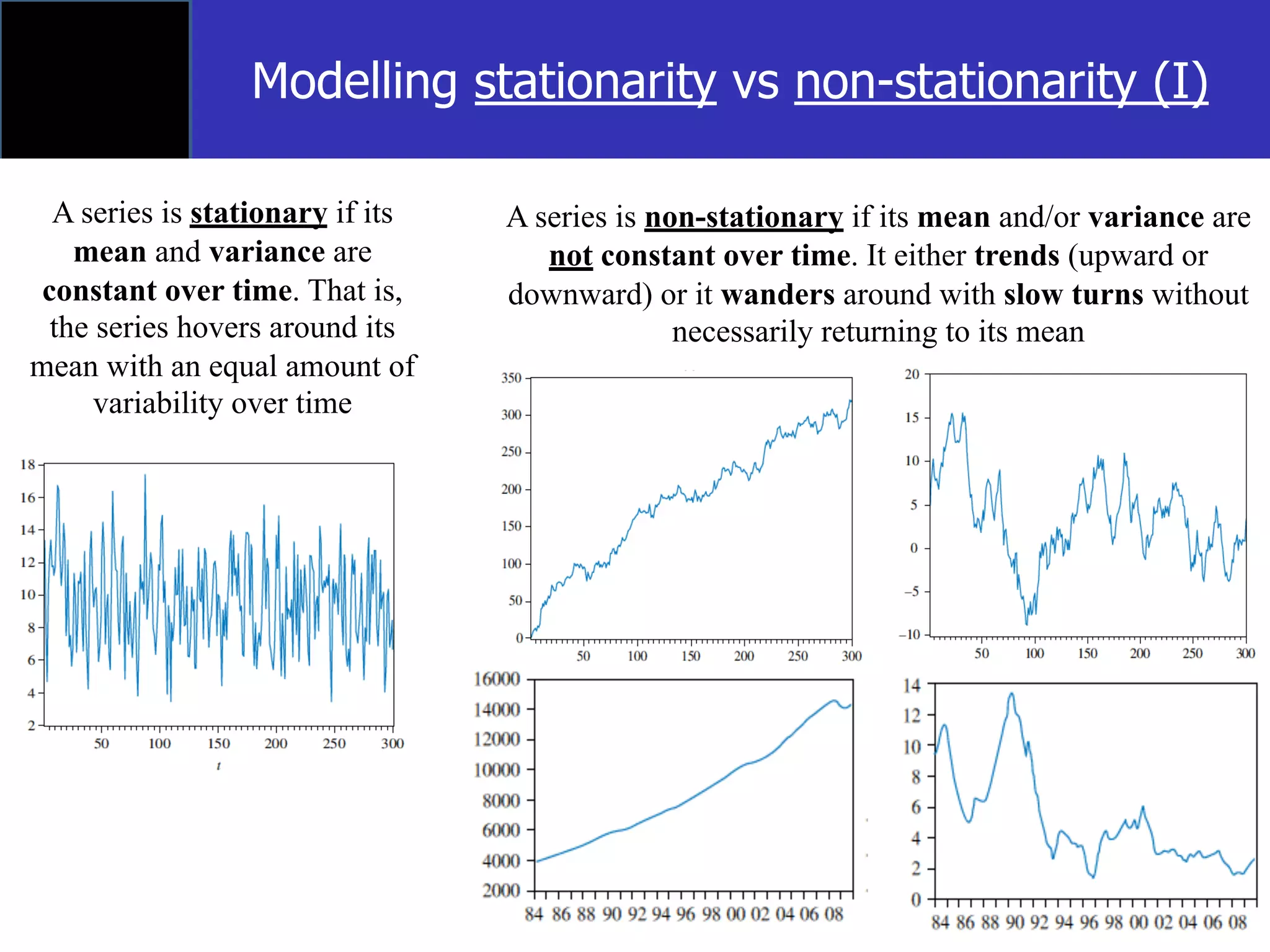

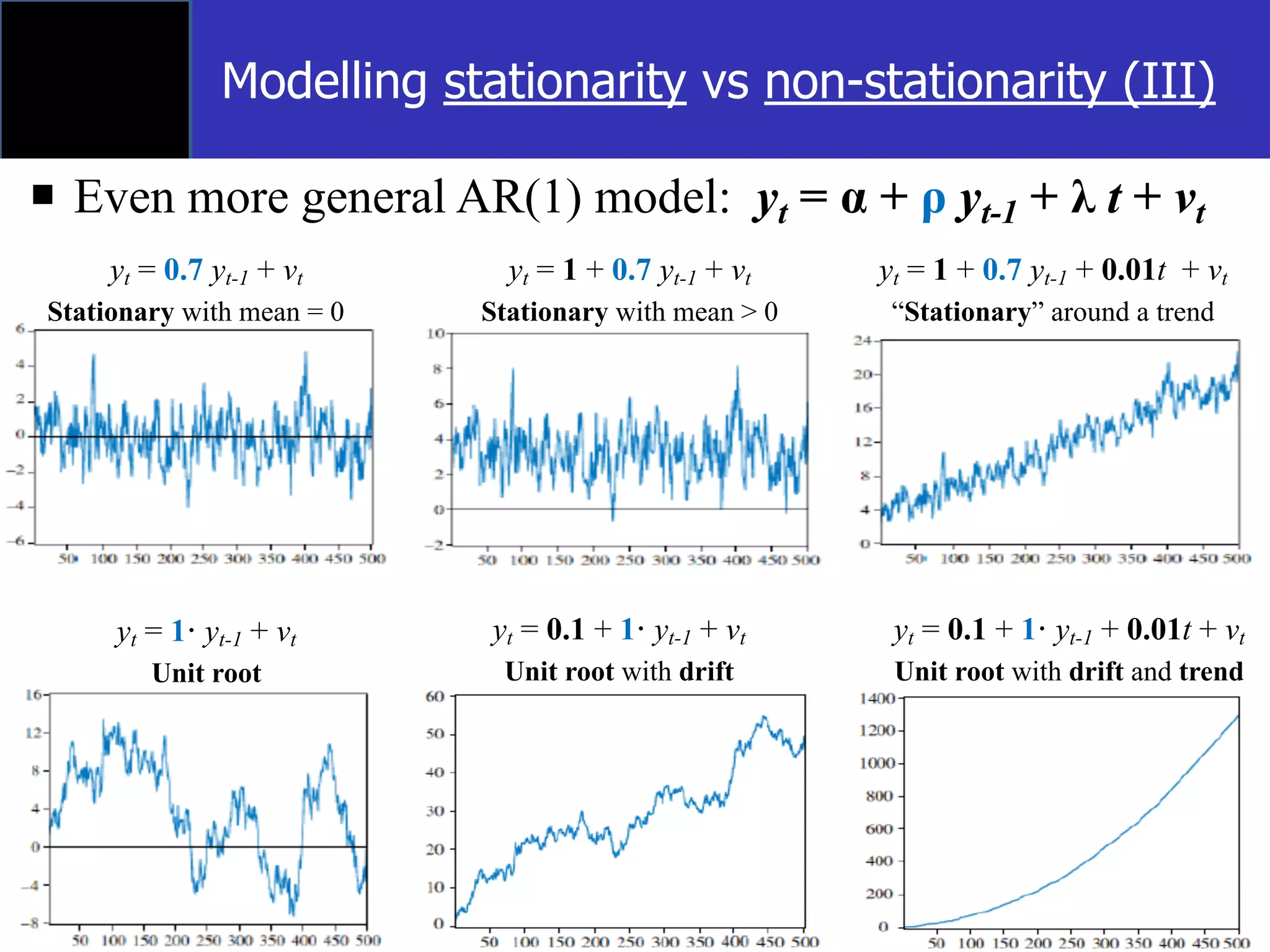
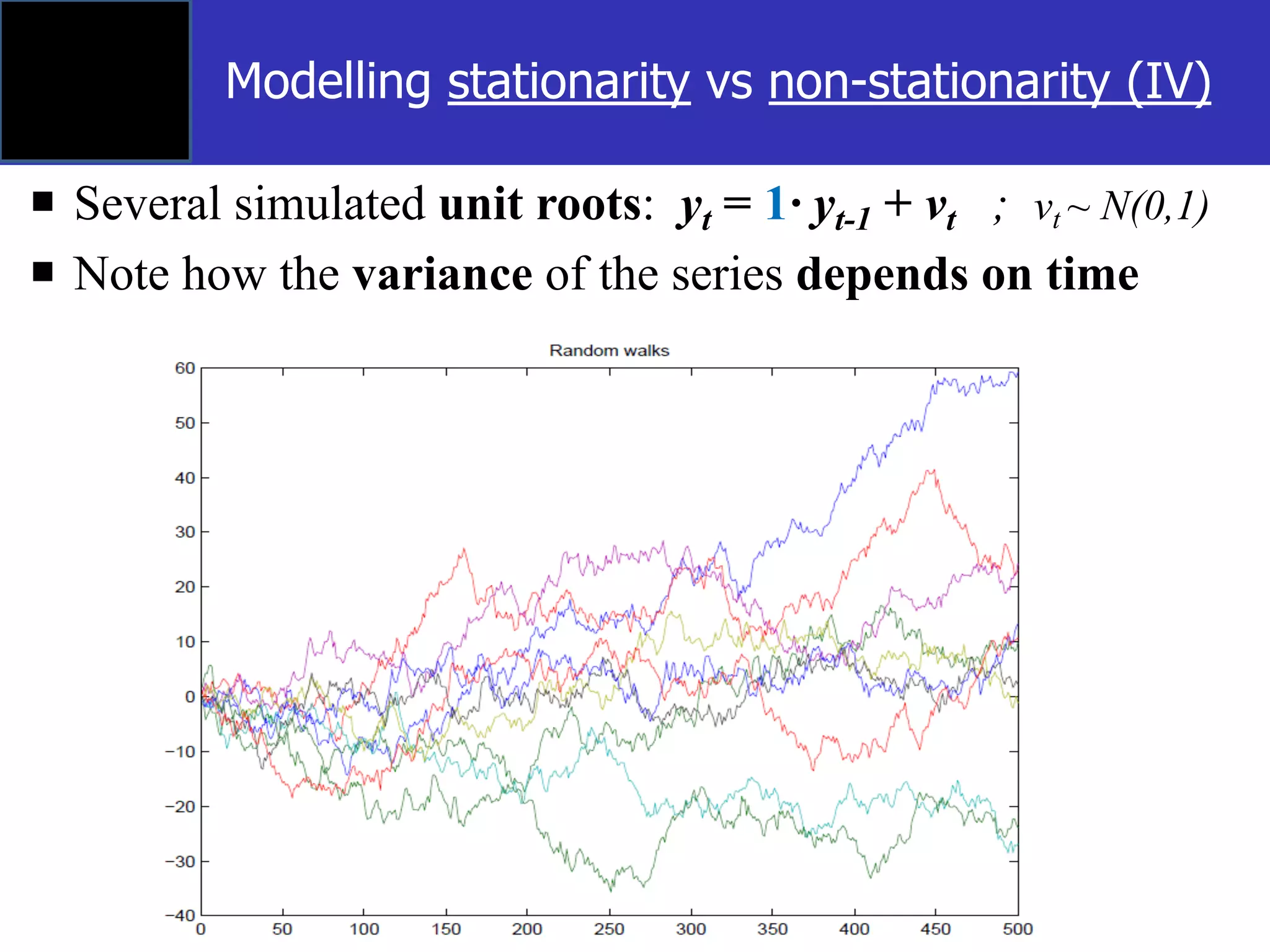













The document discusses time-series econometrics and its applications in forecasting and policy analysis, focusing on the importance of testing for stationarity in data before regression analysis. It details the conditions under which a time-series is considered stationary or non-stationary and introduces models like AR(1) and methods such as the Dickey-Fuller test for assessing these properties. Additionally, it provides examples of how to apply regression techniques for analyzing relationships between economic indicators like GDP growth and interest rates.























































































