Download as PDF, PPTX








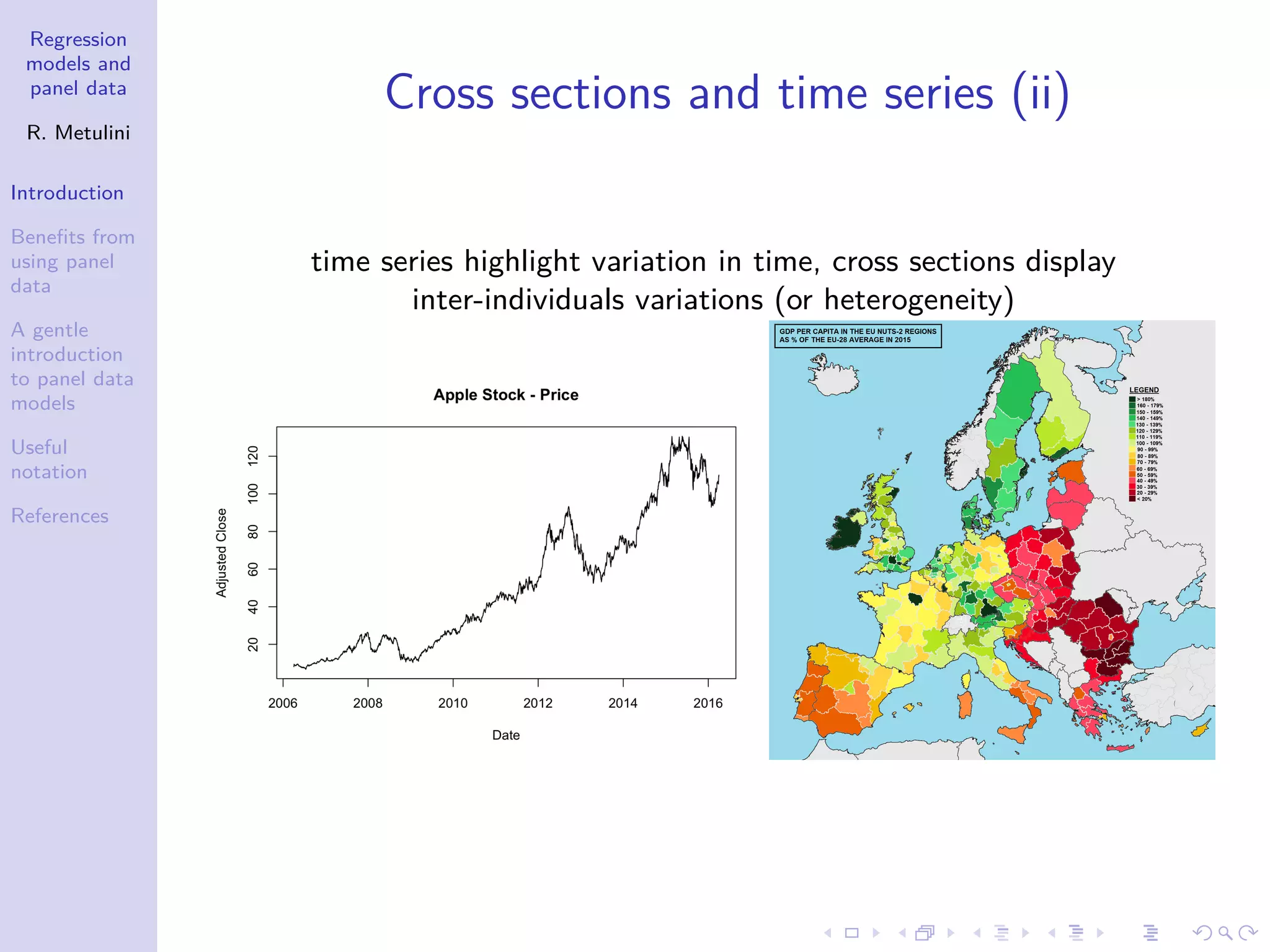

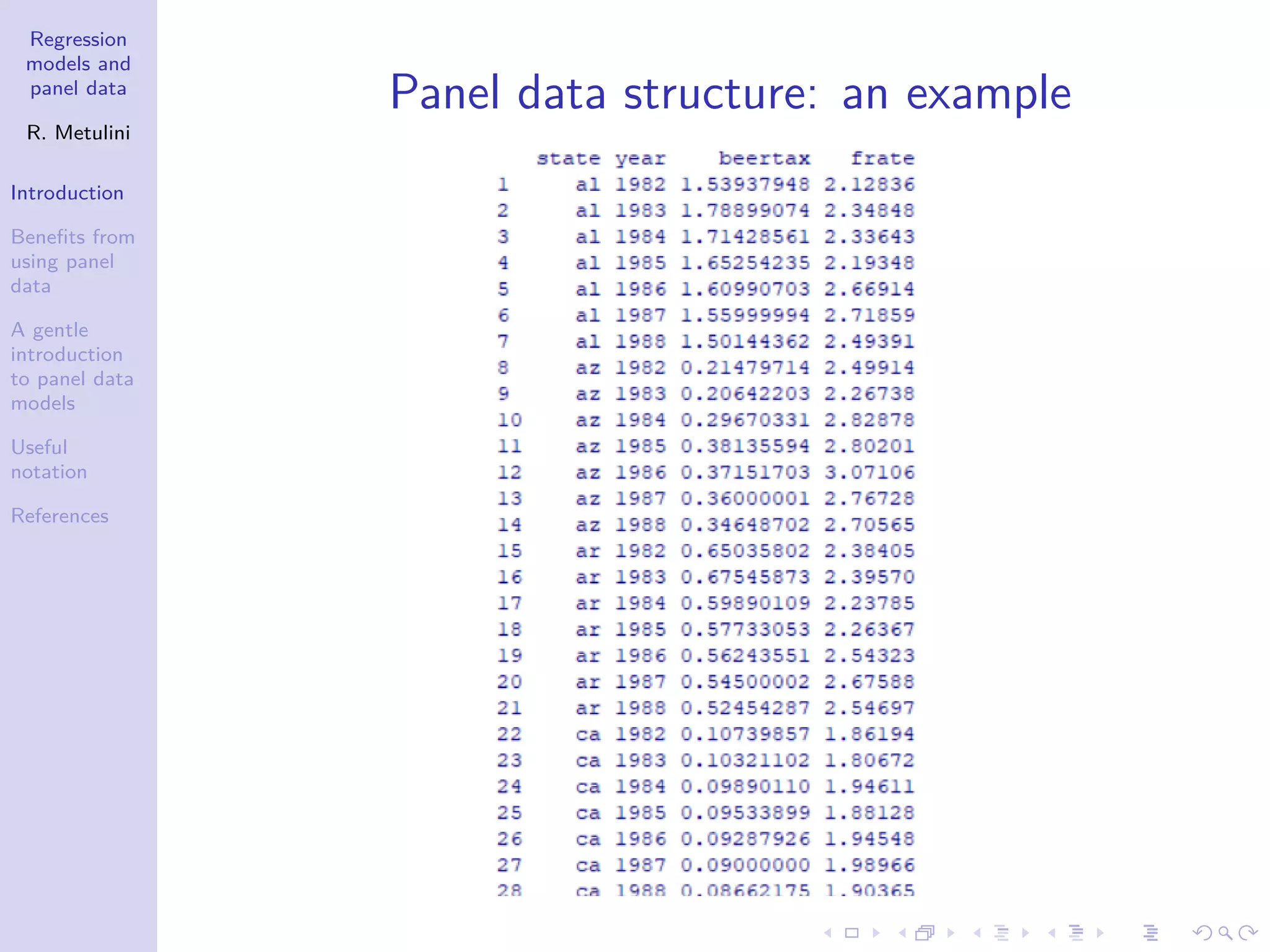
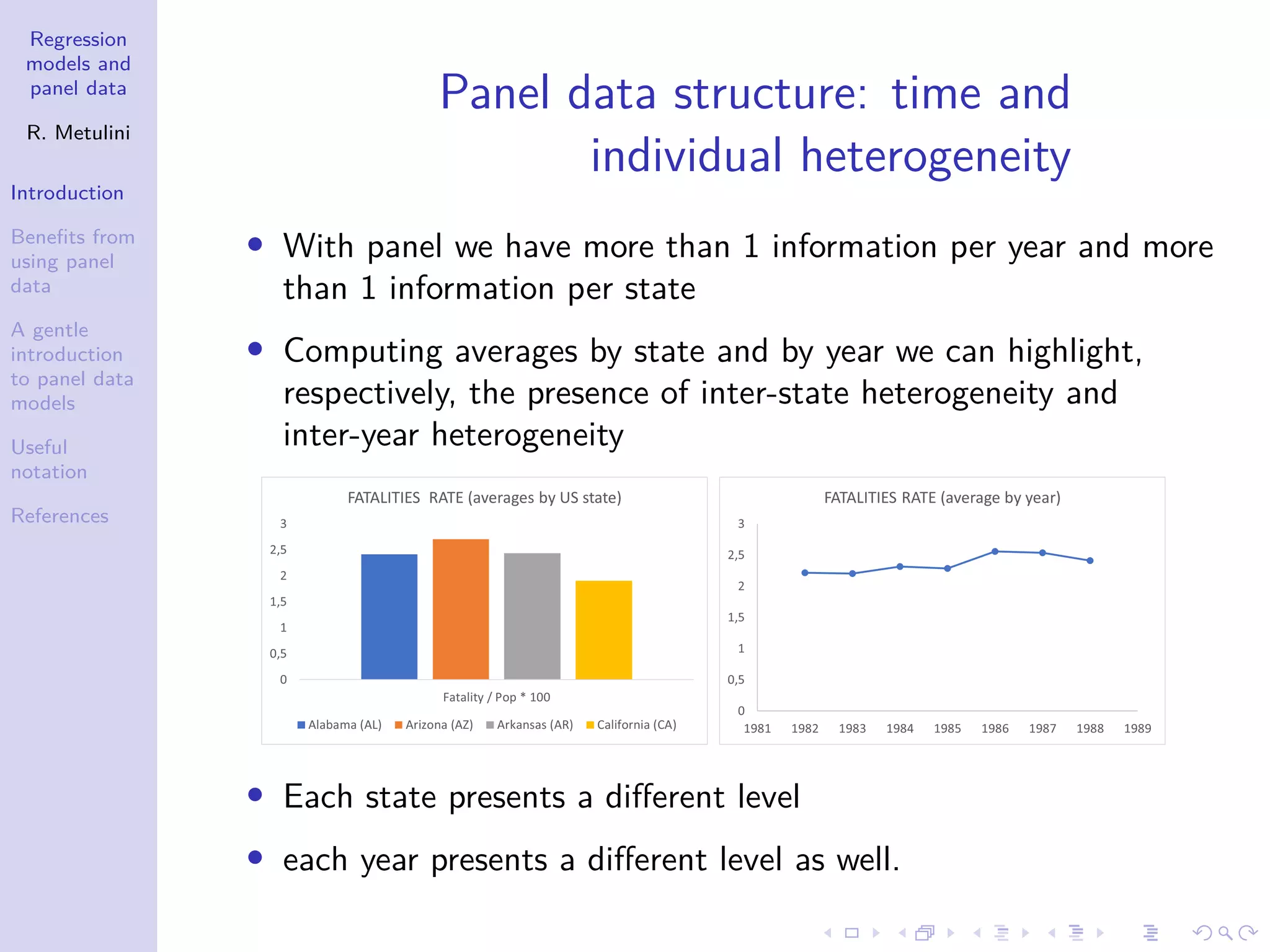




























1. The document provides an introduction to regression models and panel data, outlining key concepts such as the definition of panel data, benefits of using panel data including controlling for individual heterogeneity, and limitations of panel data including problems with data collection. 2. Panel data involves observing the same cross-section of individuals, countries, firms etc. over multiple time periods, allowing analysis of both time and individual variability. 3. Using panel data offers advantages over cross-sectional or time series data alone, such as better accounting for unobserved heterogeneity and enabling analysis of dynamic adjustments over time.























































































