Downloaded 76 times

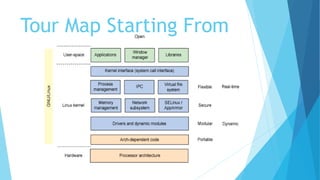

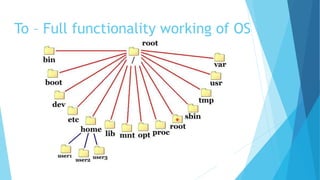

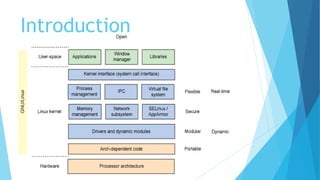












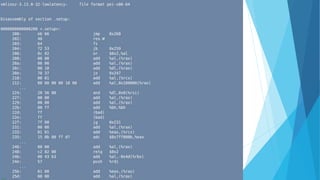


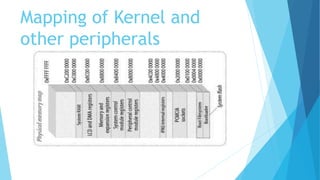







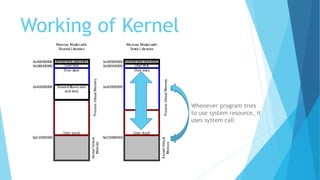












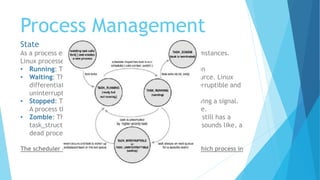



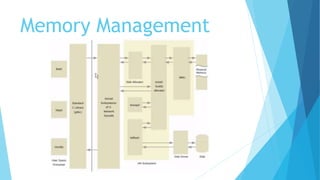

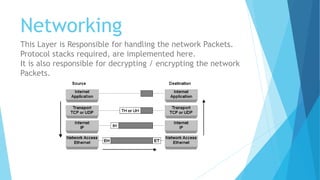








The document provides a comprehensive overview of the Linux kernel, covering its architecture, compilation, booting process, and the role of various subsystems. Key topics include kernel source organization, initialization processes, system calls, and memory management. It also addresses the methods for contributing to the kernel, such as creating patches and engaging with the community.






















































































