Download as PDF, PPTX





















VLIW and EPIC are processor architectures that aim to improve performance through instruction level parallelism. VLIW processors use very long instruction words containing multiple operations that can execute in parallel. EPIC evolved from VLIW and uses compiler scheduling to explicitly specify parallel instructions. The Intel Itanium architecture implemented the EPIC model using the IA-64 instruction set, featuring long instruction bundles, predication, and a large register file to facilitate parallel execution.
Discusses VLIW architecture that allows simultaneous instruction execution, its advantages like higher performance, and its limitation in reacting to dynamic events. Introduces EPIC, its evolution from VLIW, the static parallelism it supports, and performance scalability advantages compared to traditional architectures.
Highlights the synthesis of VLIW and superscalar methods, addressing static and dynamic parallelization needs and improving general computing performance.
Details the shortcomings of early VLIW systems and the challenges faced by EPIC architectures in achieving efficiency and scalability.
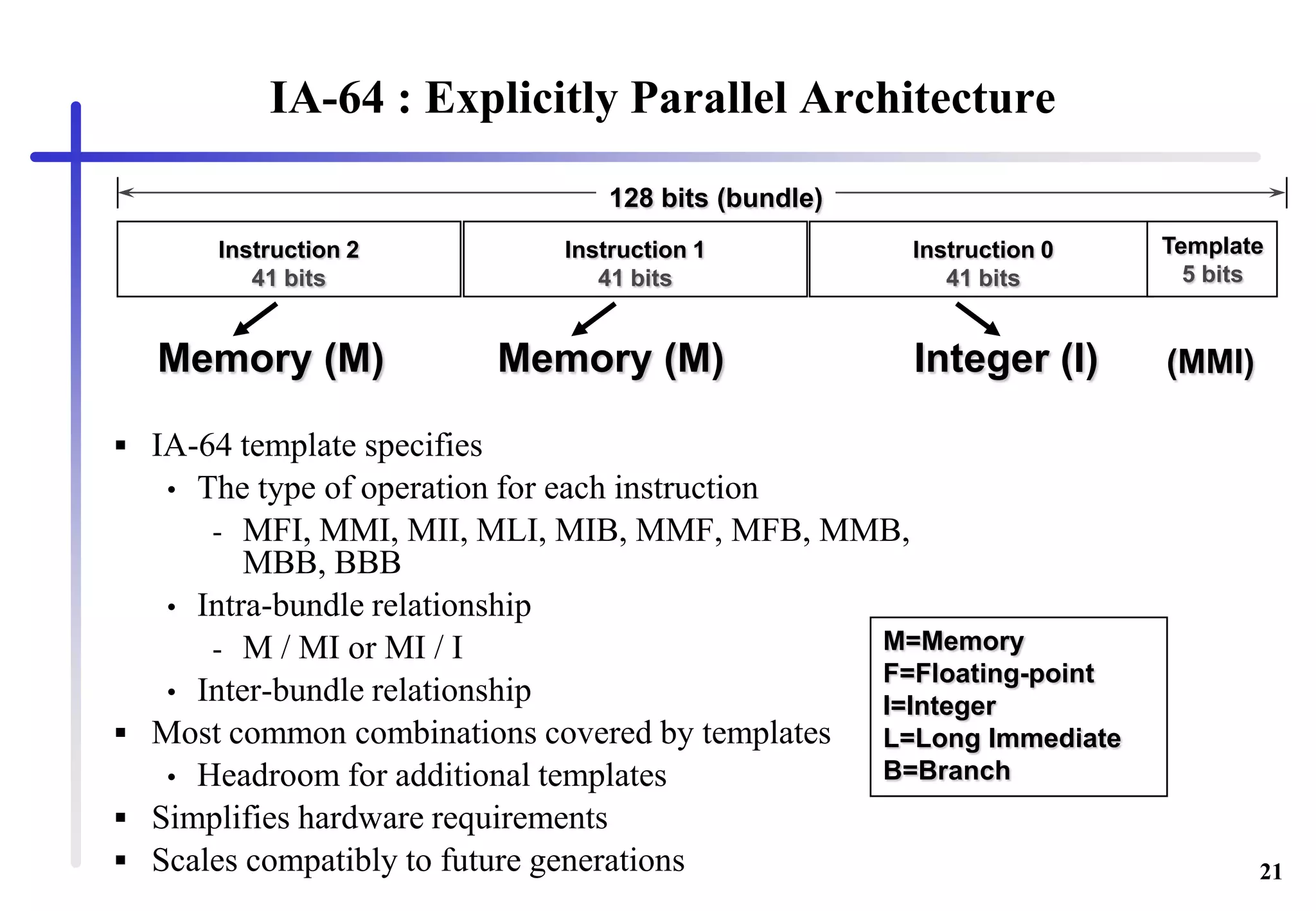
Describes Intel’s IA-64 ISA features including explicit ILP support, large register availability, and instruction structuring for enhanced performance.
Explains the IA-64 instruction bundles, their organization, and how the template facilitates instruction execution across different paths.























































































