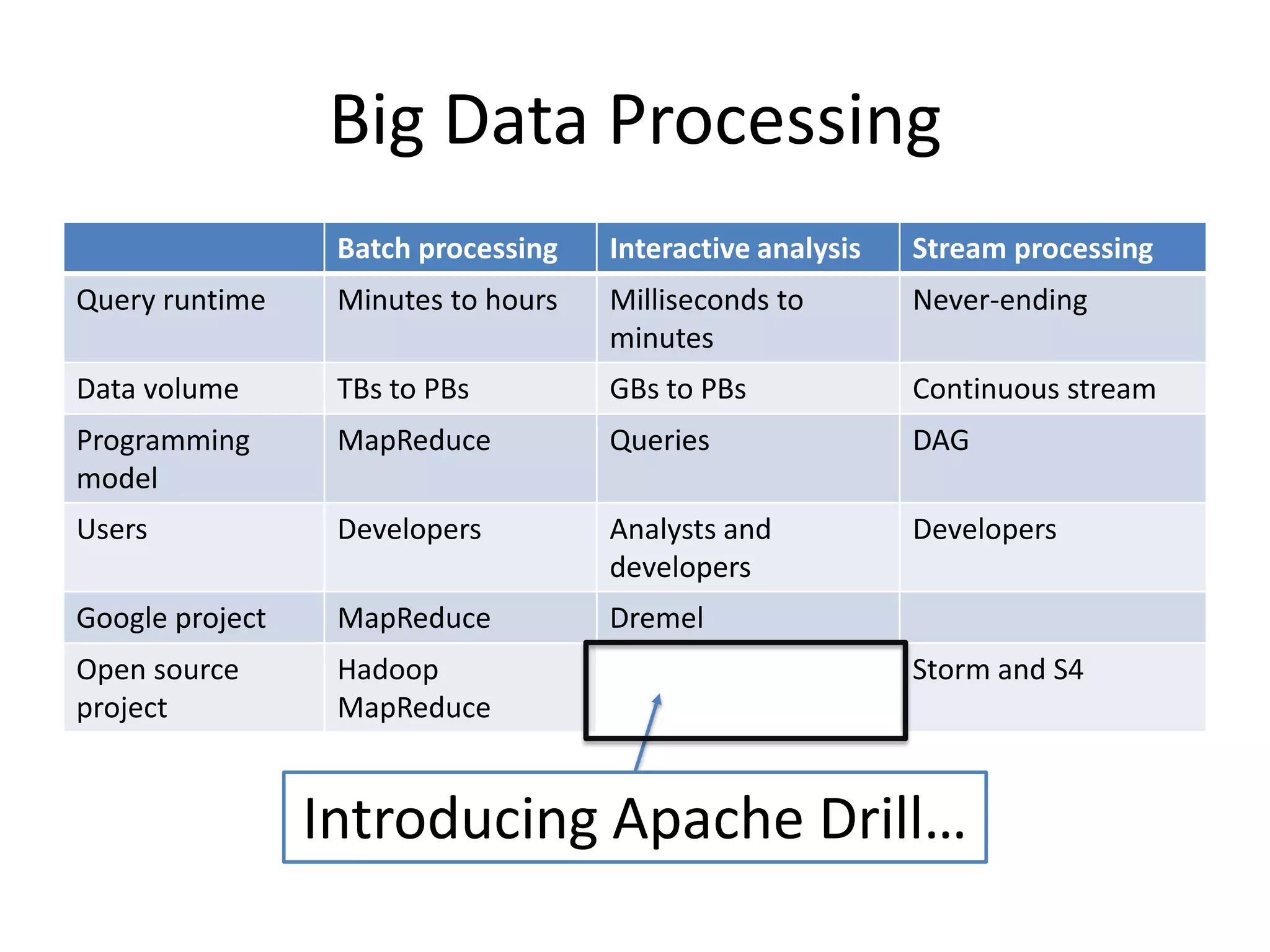
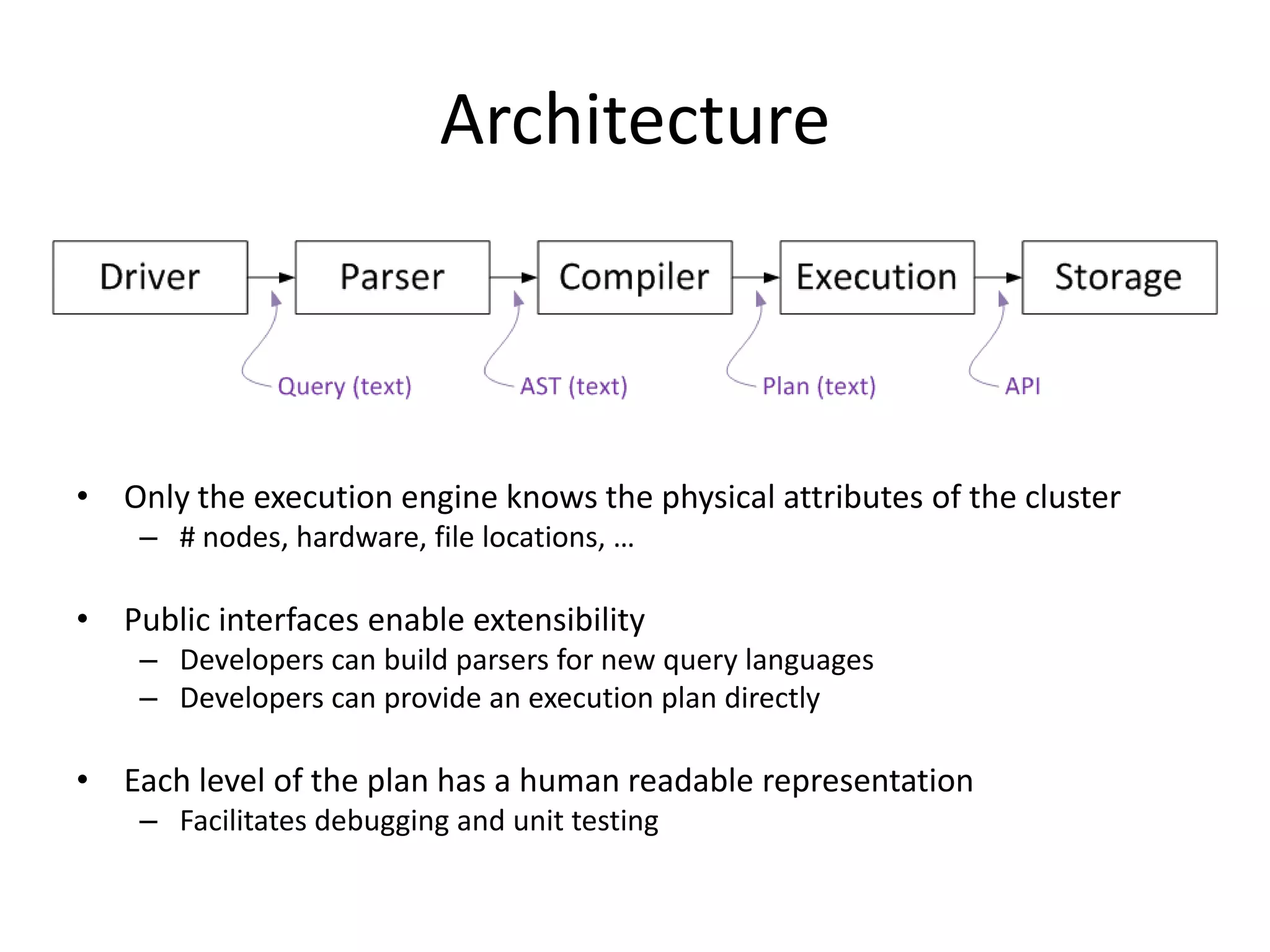
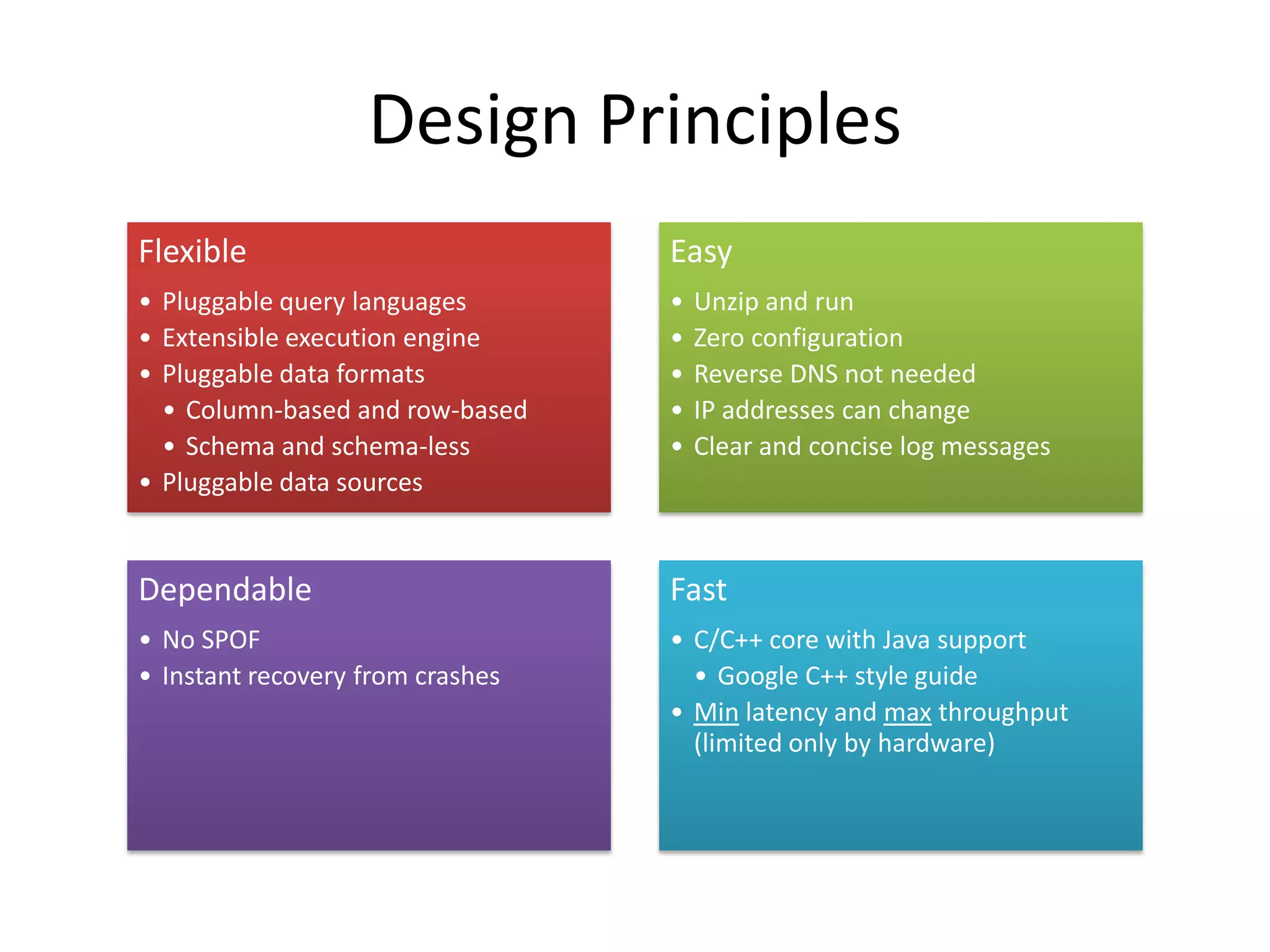
Apache Drill is an open source engine for interactive analysis of large-scale datasets. It was inspired by Google's Dremel, which allows interactive querying of trillions of records at fast speeds. Drill uses a SQL-like language called DrQL to query nested data in a column-based manner. It has a flexible architecture that allows pluggable query languages, execution engines, data formats and sources. Drill aims to be fast, flexible, dependable and easy to use for interactive analysis of big data.