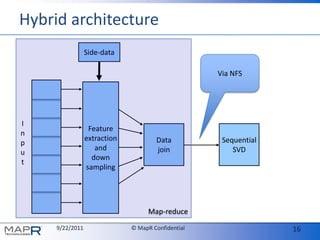
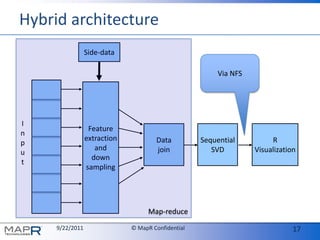
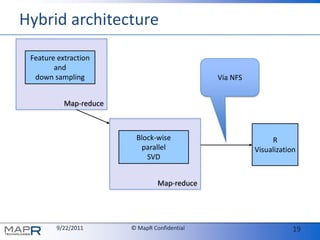
The document discusses the limitations of traditional Hadoop and the innovative solutions offered by MapR, including features such as snapshots and cluster-wide file access through NFS. It emphasizes the benefits of using Singular Value Decomposition (SVD) in combination with a hybrid architecture for efficient feature extraction and visualization in R. Overall, it highlights the potential for scalability and interoperability in data processing, particularly for large datasets.













![In Rlsa = function(a, k, p) { n = dim(a)[1] m = dim(a)[2] y = a %*% matrix(rnorm(m*(k+p)), nrow=m)y.qr = qr(y) b = t(qr.Q(y.qr)) %*% ab.qr = qr(t(b))svd = svd(t(qr.R(b.qr))) list(u=qr.Q(y.qr) %*% svd$u[,1:k], d=svd$d[1:k], v=qr.Q(b.qr) %*% svd$v[,1:k])}](https://image.slidesharecdn.com/r-user-group-2011-09-110922215823-phpapp02/85/R-user-group-2011-09-14-320.jpg)















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















