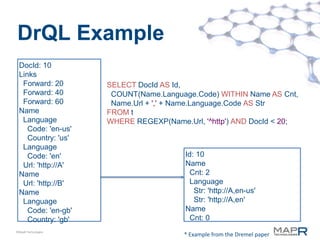
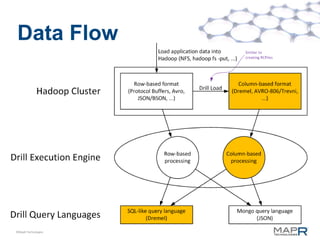
The document discusses the performance benchmarks of MapR technologies, comparing speed and throughput with traditional Hadoop implementations, particularly highlighting improvements in interactive and real-time query capabilities. It outlines the functionalities of tools like Apache Drill and Storm, emphasizing their extensibility, fault tolerance, and integration with various data sources. The presentation also includes insights into system architecture, query language support, and user community engagement around these technologies.







![Google BigQuery
• Hosted Dremel (Dremel as a Service)
• CLI (bq) and Web UI
• Import data from Google Cloud Storage or local files
• Files must be in CSV format
• Nested data not supported [yet] except built-in datasets
• Schema definition required
©MapR Technologies](https://image.slidesharecdn.com/phillydb-2013-01-15-130115165932-phpapp01/85/PhillyDB-Talk-Beyond-Batch-10-320.jpg)





























































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)









