Download as PDF, PPTX






![Google BigQuery
• Hosted Dremel (Dremel as a Service)
• CLI (bq) and Web UI
• Import data from Google Cloud Storage or local files
– Files must be in CSV format
• Nested data not supported [yet] except built-in datasets
– Schema definition required](https://image.slidesharecdn.com/drillbayareahug9-19-12-120923124825-phpapp01/75/Sep-2012-HUG-Apache-Drill-for-Interactive-Analysis-8-2048.jpg)


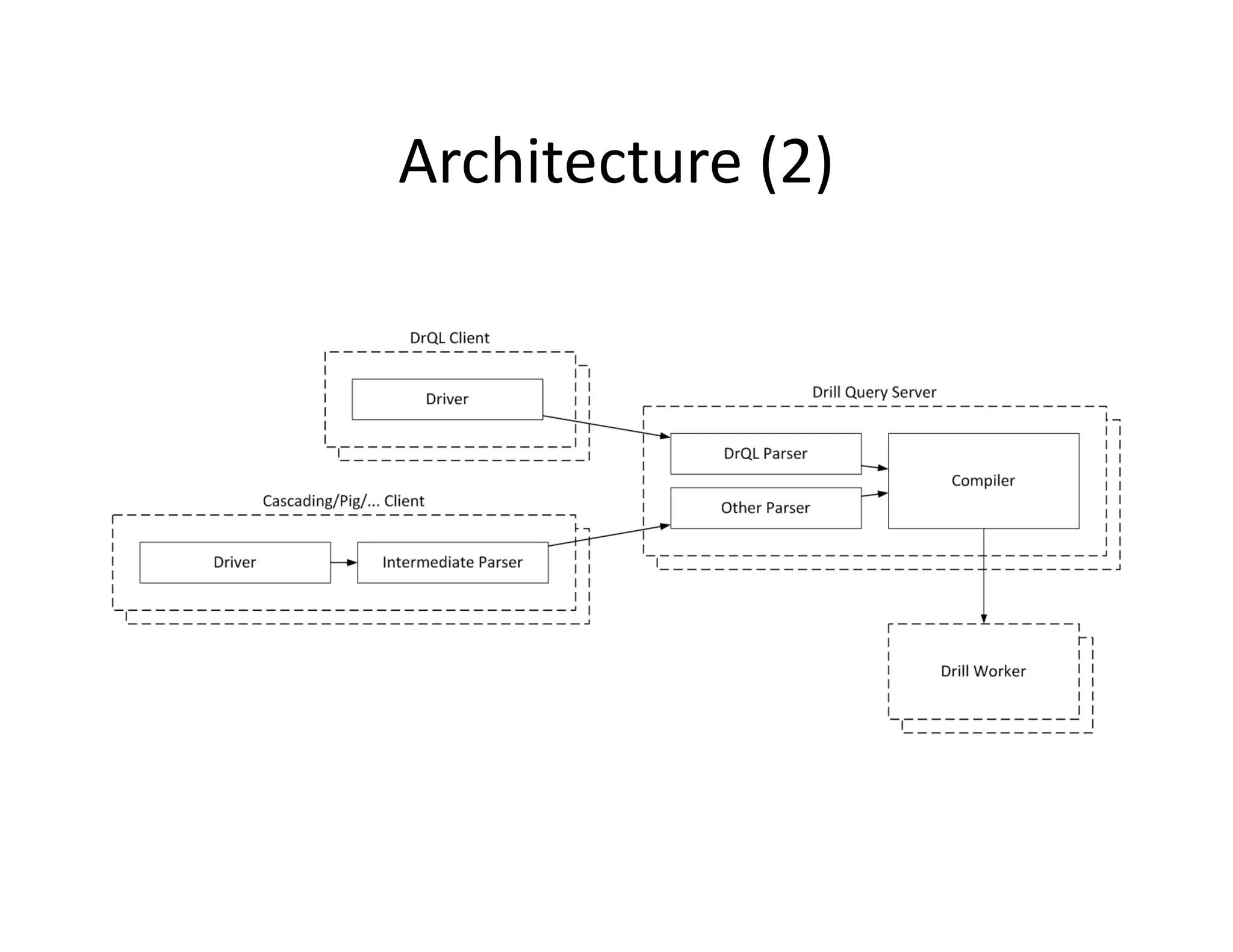

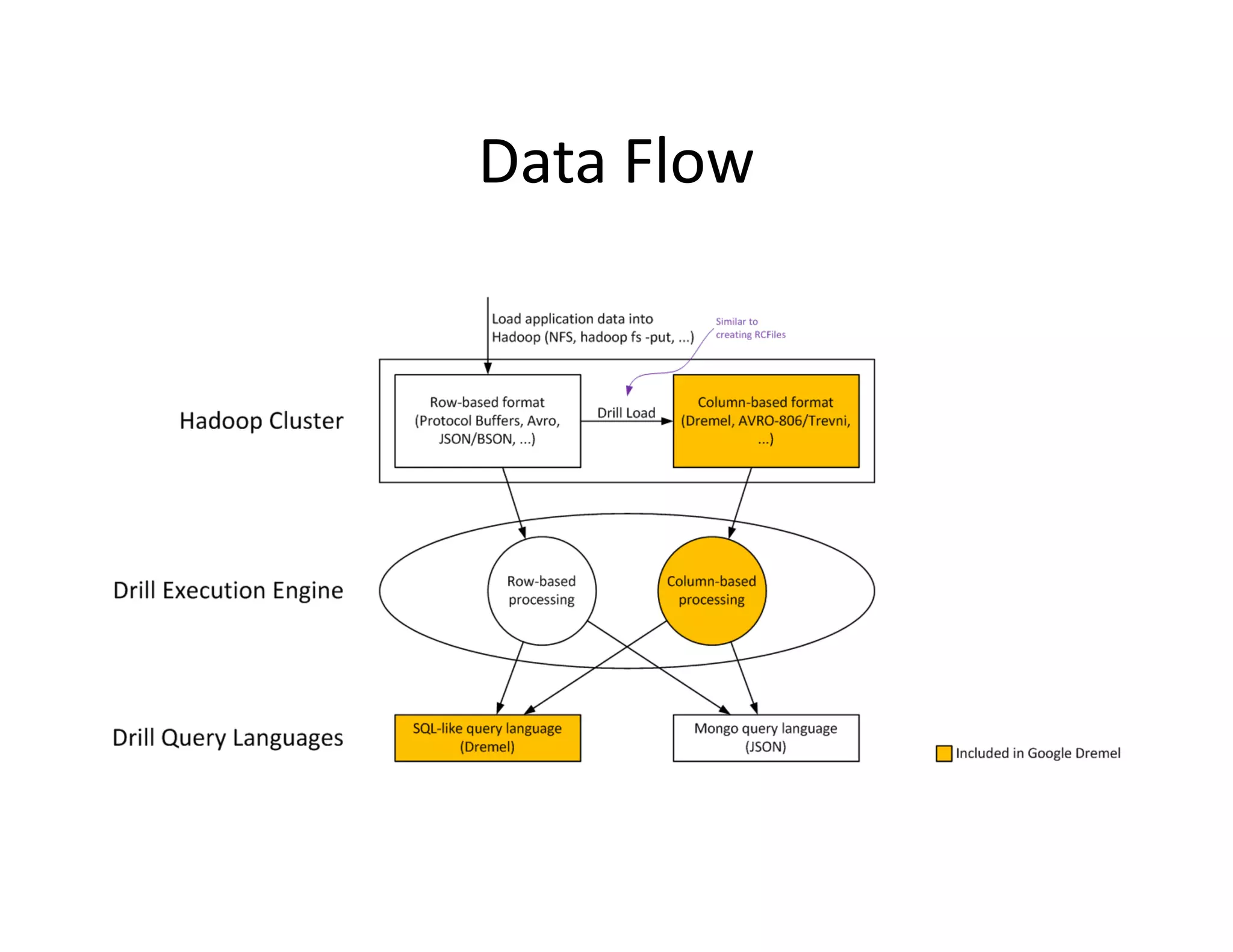










Apache Drill is designed for interactive analysis of large-scale datasets, offering capabilities to process trillions of records at high speeds while supporting multiple data models. It features a flexible architecture that allows extensibility for different query languages and data formats, enabling efficient performance with both nested and flat records. The integration with Hadoop enhances its ability to handle massive data sources and formats, making it suitable for diverse applications across various industries.



































































































