Downloaded 27 times














![© 2014 MapR Technologies 21
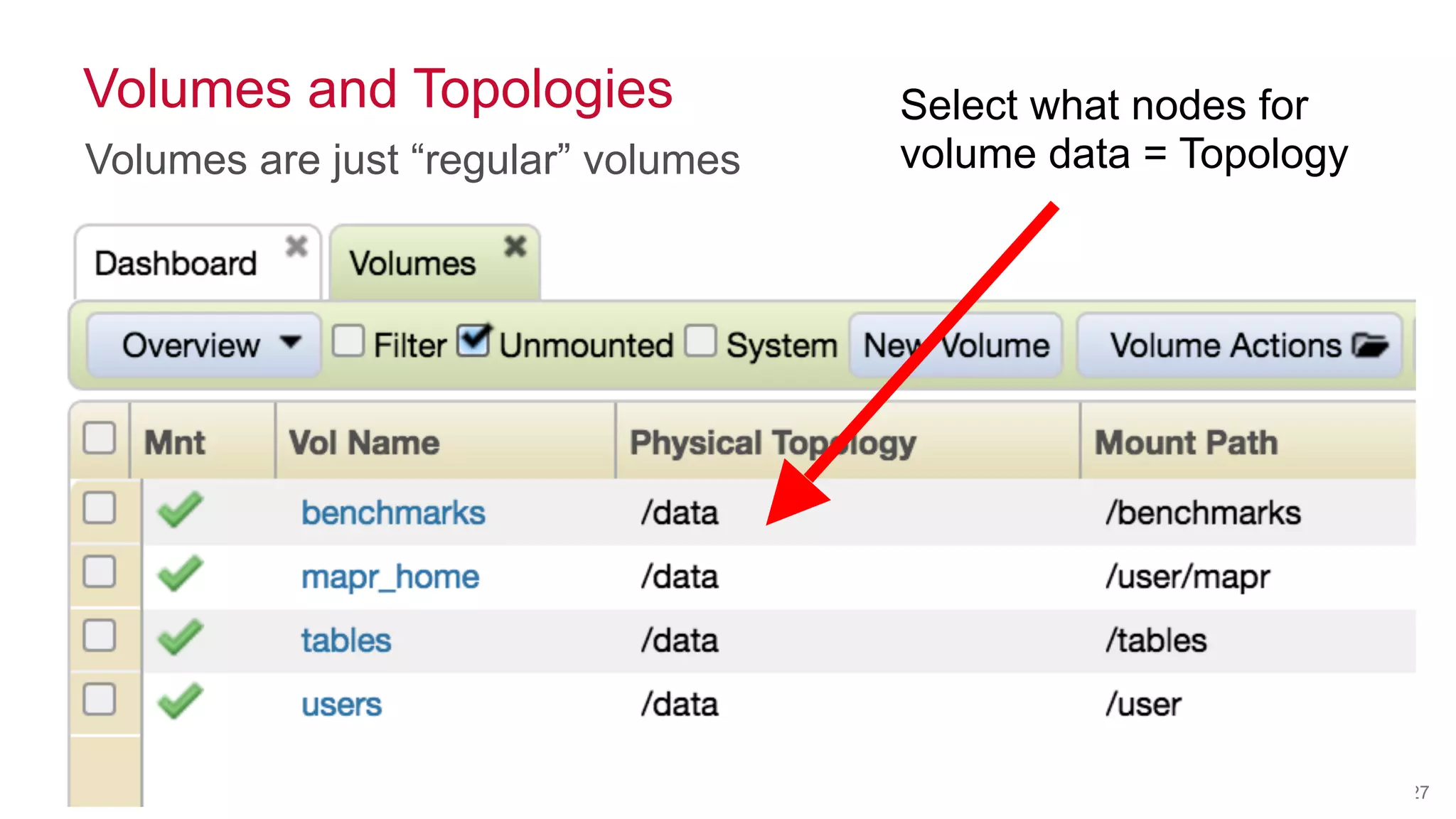
MapR NFS and Volumes
[mapr@ip-10-0-0-110 mapr]$ pwd
/mapr/hadoopsummit/user/mapr](https://image.slidesharecdn.com/hadoopsummittokyo2016-161028021146/75/Real-World-Machine-Learning-Leverage-the-Features-of-MapR-Converged-Data-Platform-21-2048.jpg)
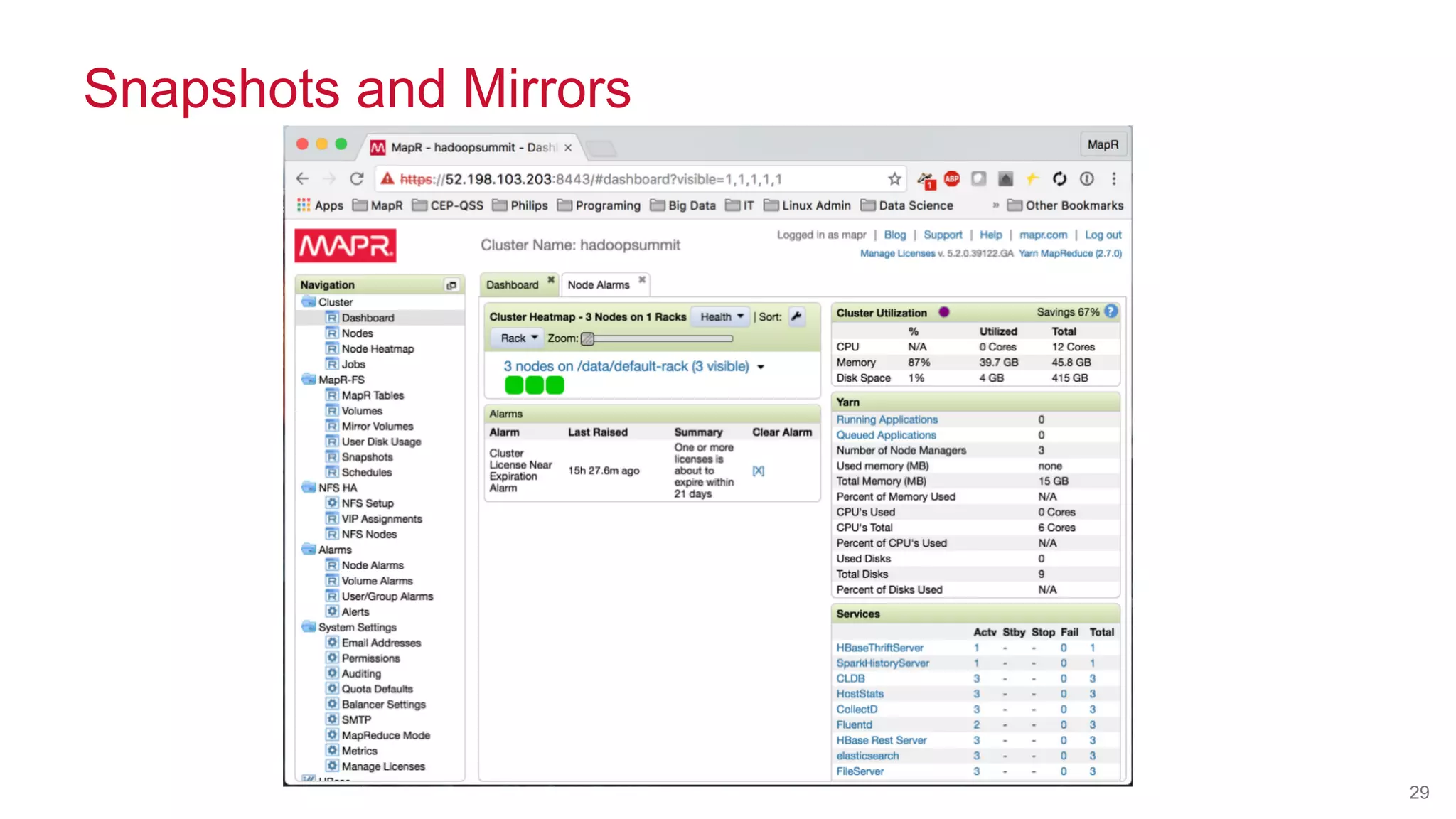
![© 2014 MapR Technologies 22
MapR NFS and Volumes
[mapr@ip-10-0-0-110 mapr]$ pwd
/mapr/hadoopsummit/user/mapr](https://image.slidesharecdn.com/hadoopsummittokyo2016-161028021146/75/Real-World-Machine-Learning-Leverage-the-Features-of-MapR-Converged-Data-Platform-22-2048.jpg)
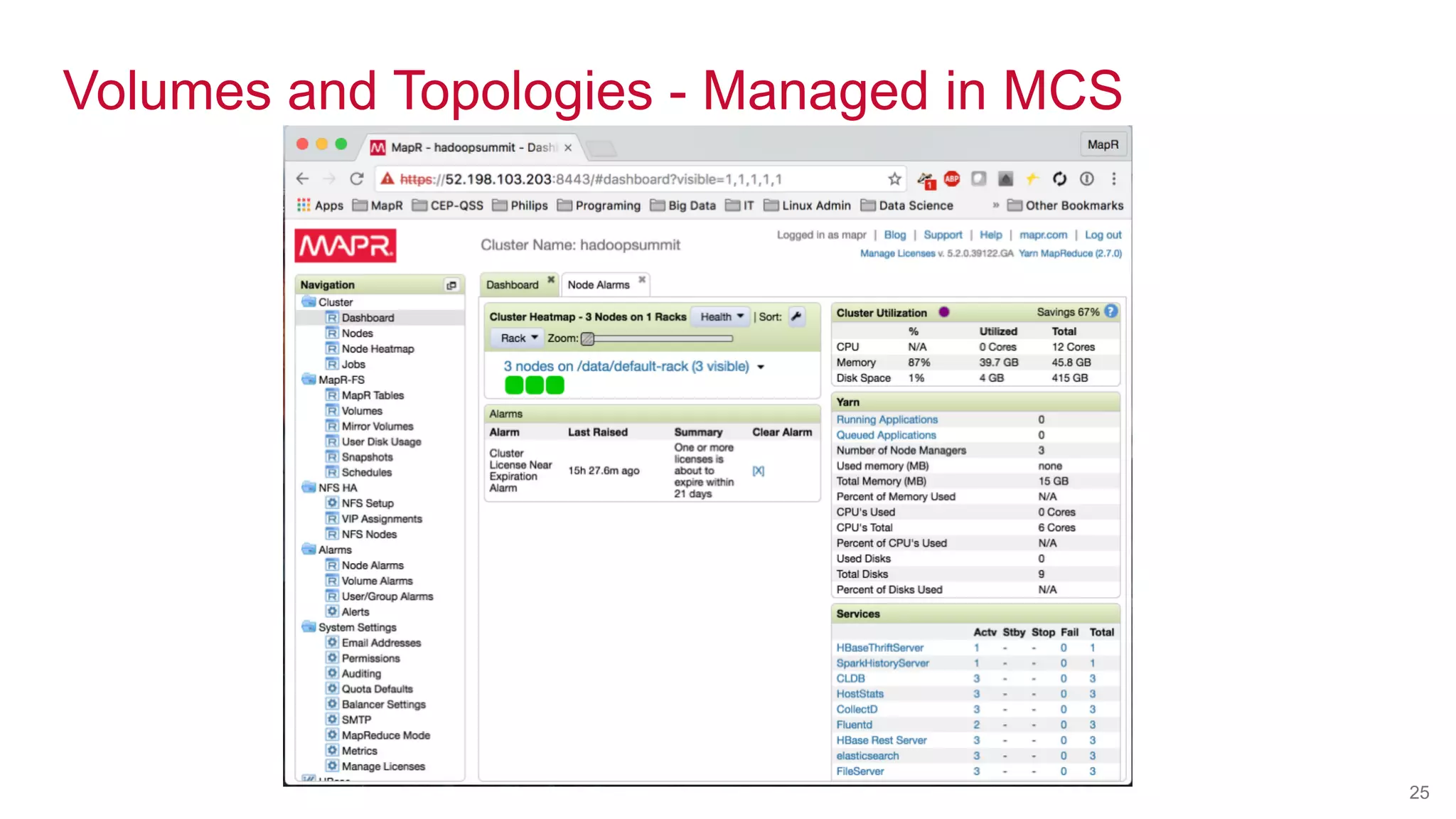
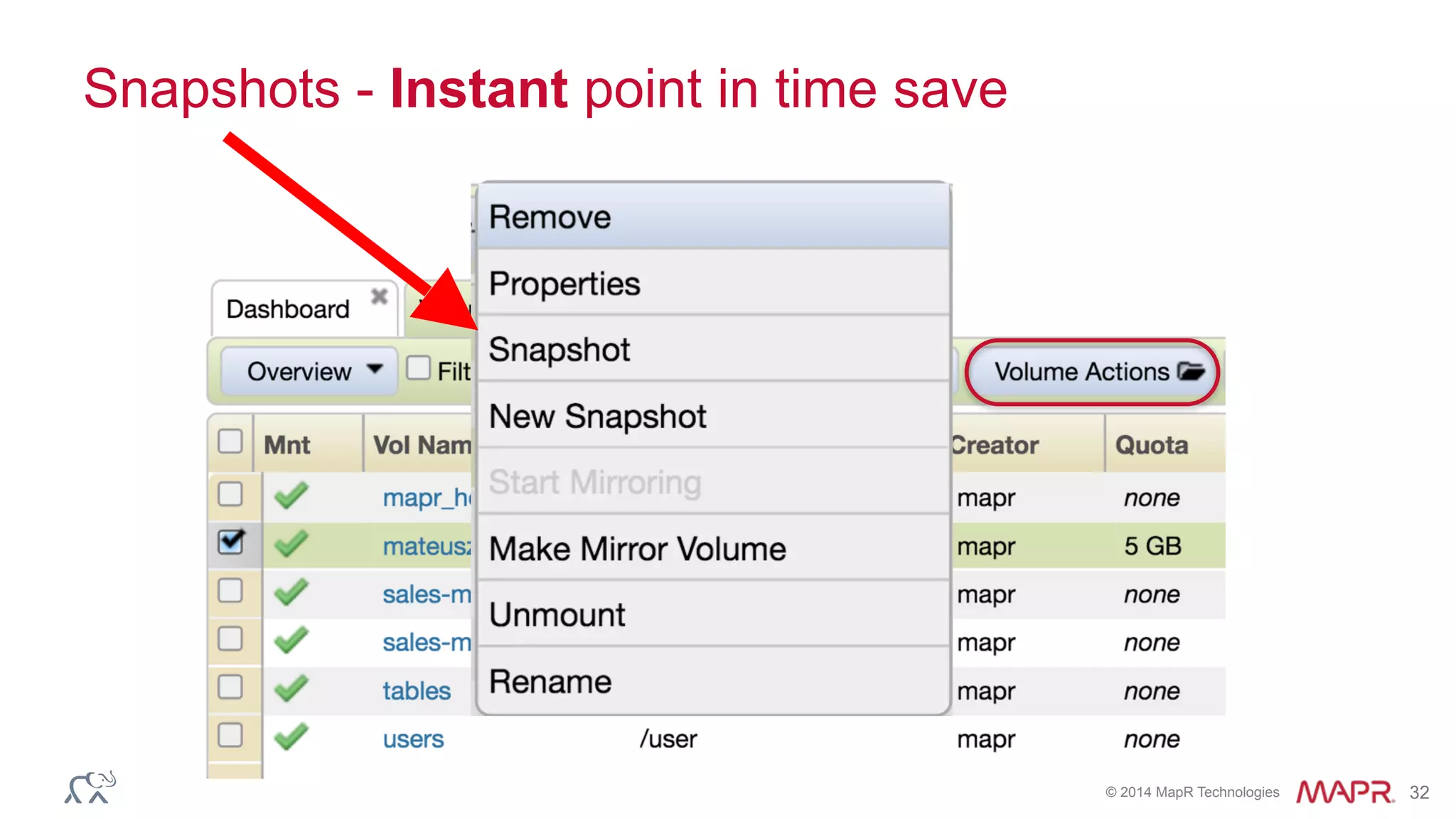
![© 2014 MapR Technologies 23
MapR NFS and Volumes
[mapr@ip-10-0-0-110 mapr]$ pwd
/mapr/hadoopsummit/user/mapr](https://image.slidesharecdn.com/hadoopsummittokyo2016-161028021146/75/Real-World-Machine-Learning-Leverage-the-Features-of-MapR-Converged-Data-Platform-23-2048.jpg)

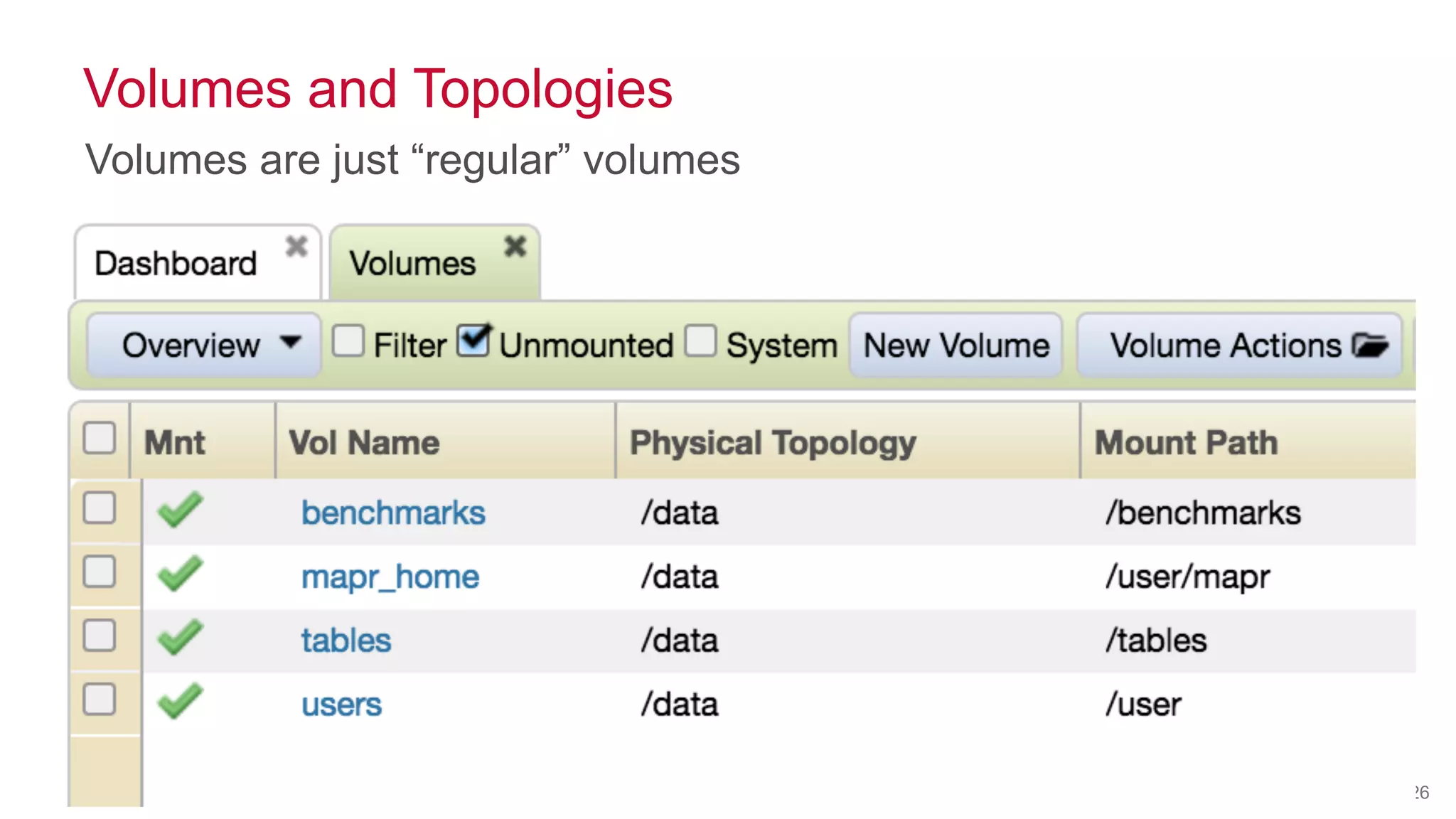



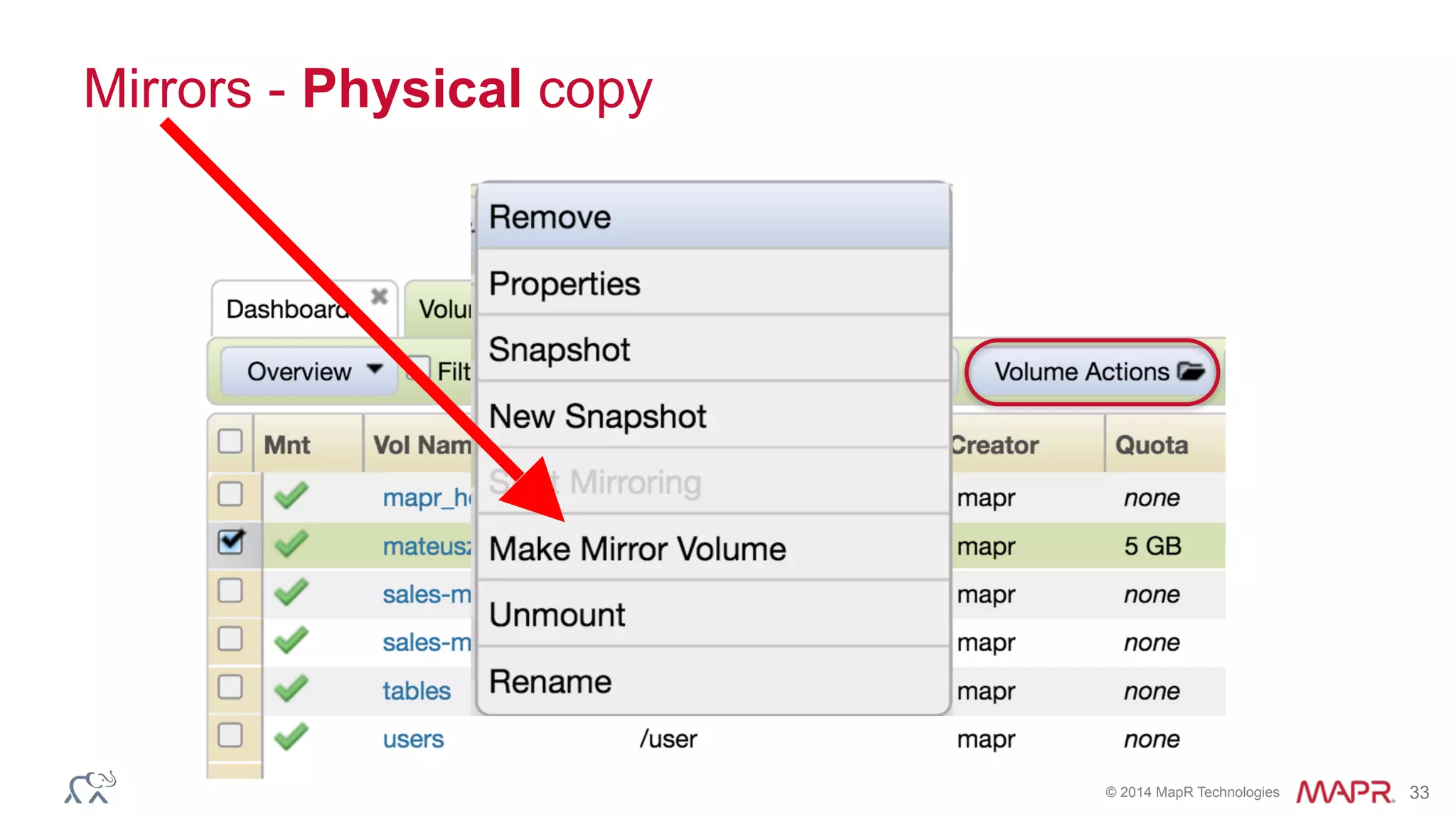
![© 2014 MapR Technologies 34
Snapshots
[... mateusz]$ cd .snapshot
[... .snapshot]$ ll
total 1
drwxr-xr-x. 2 mapr mapr 1 Oct 14 10:56
mateusz.snap1](https://image.slidesharecdn.com/hadoopsummittokyo2016-161028021146/75/Real-World-Machine-Learning-Leverage-the-Features-of-MapR-Converged-Data-Platform-34-2048.jpg)


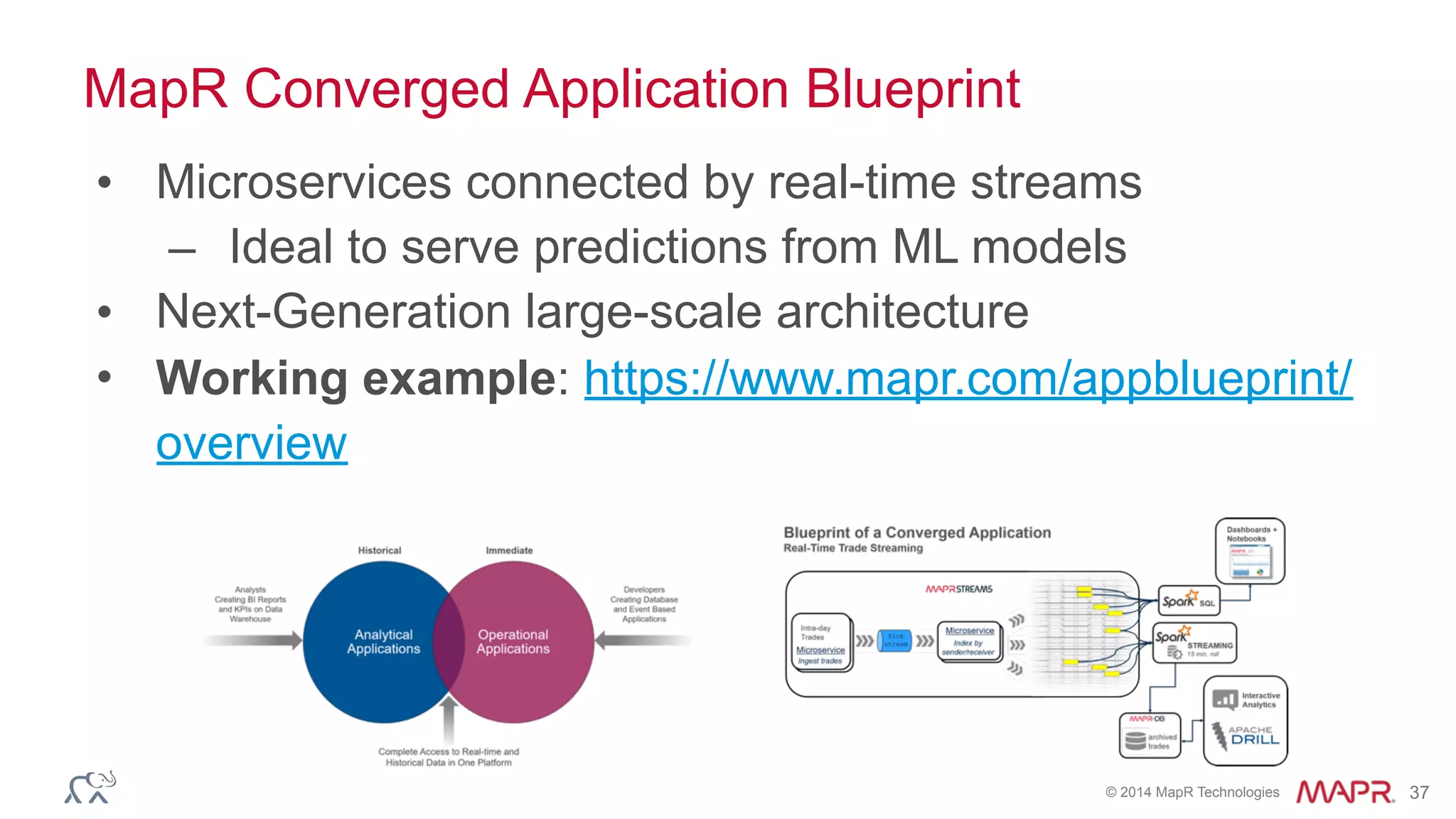



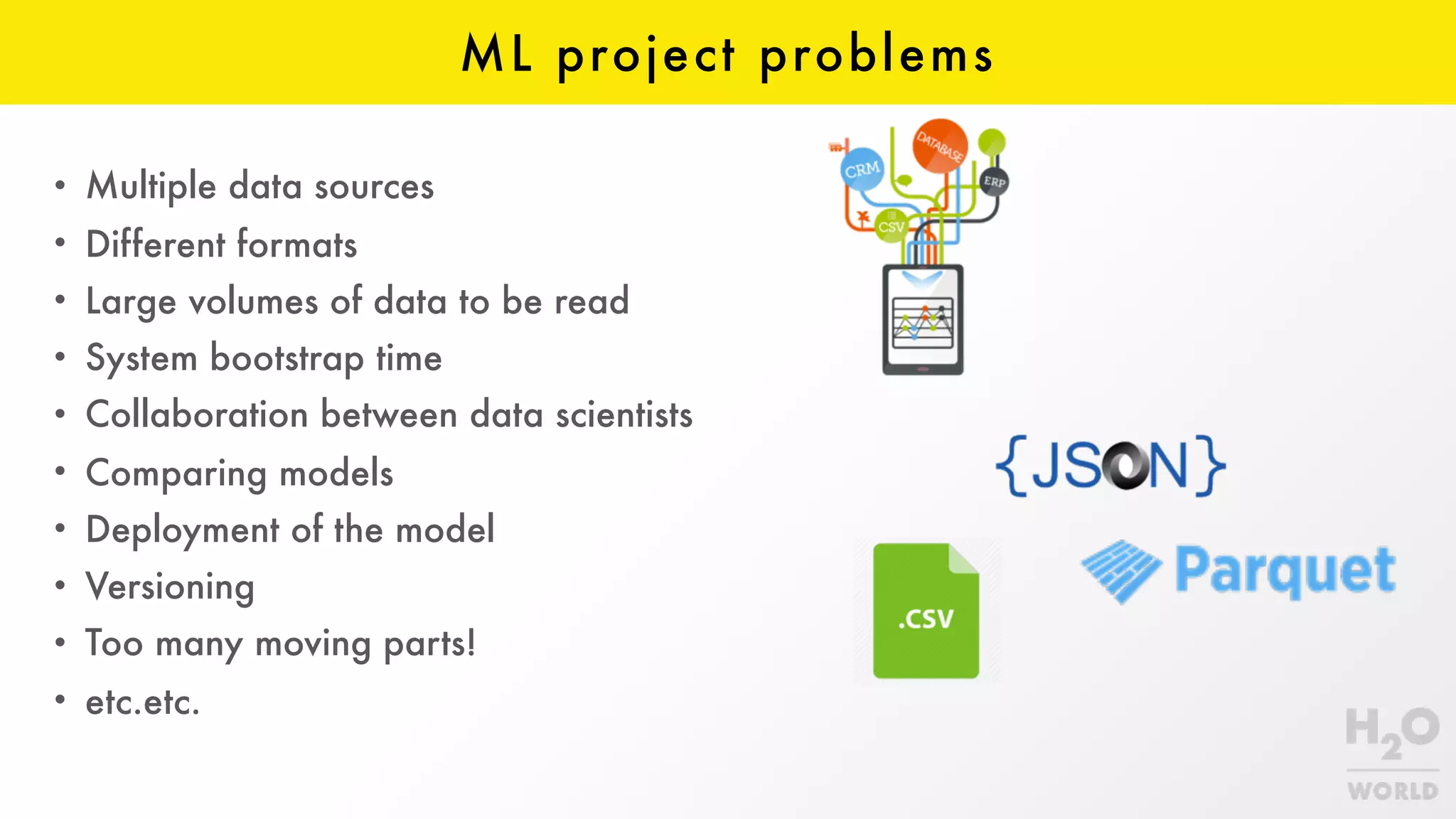







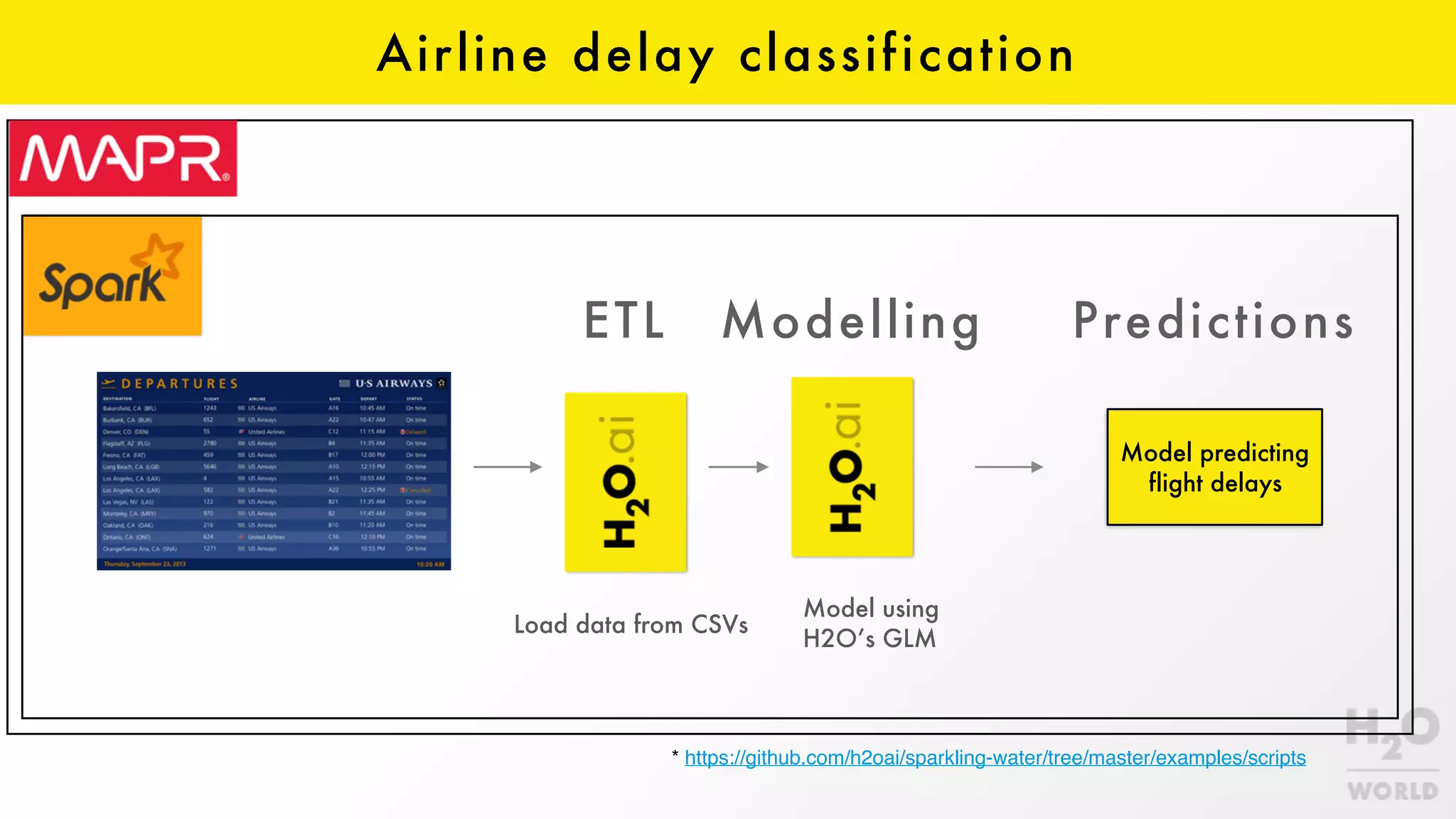


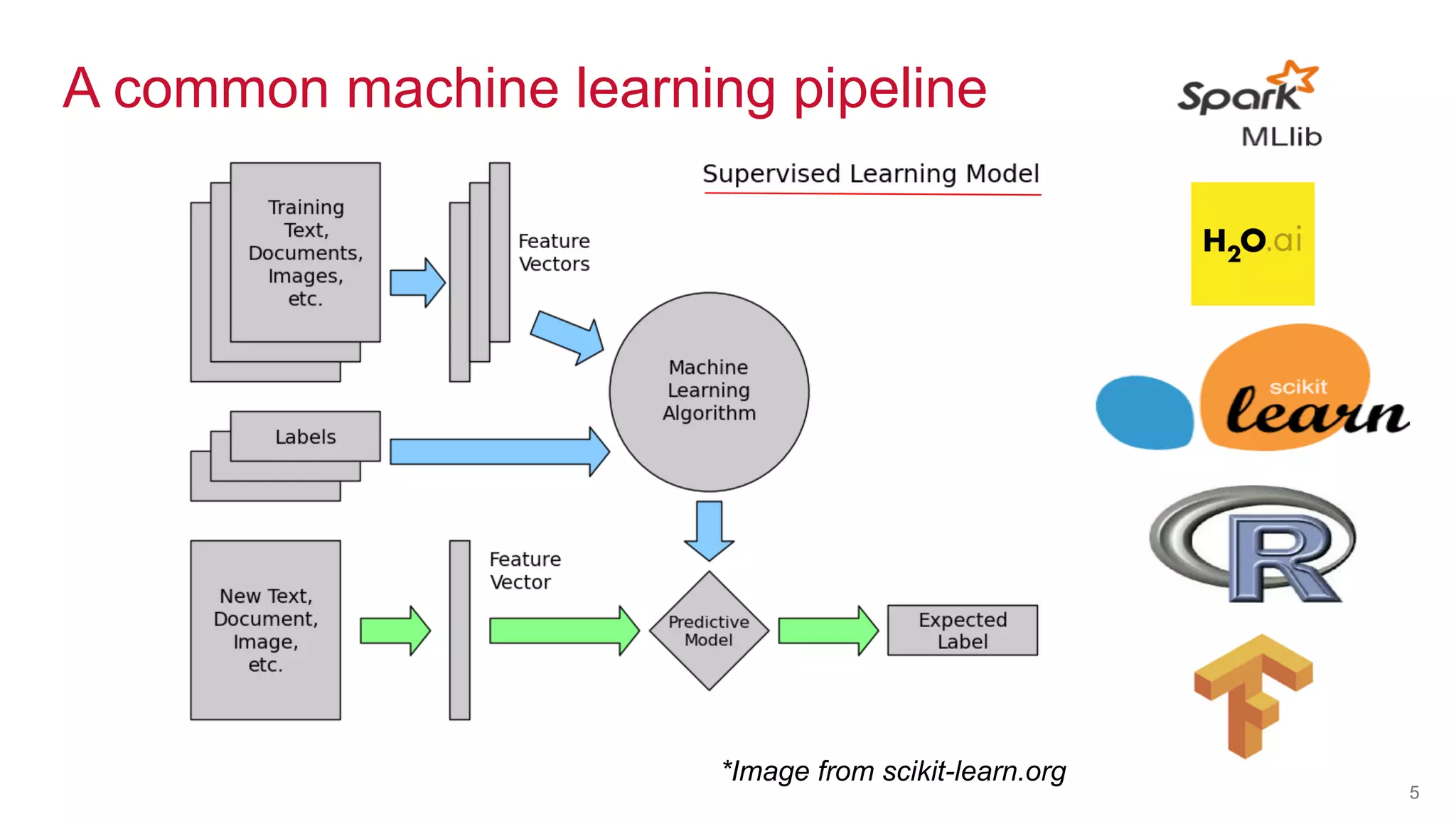
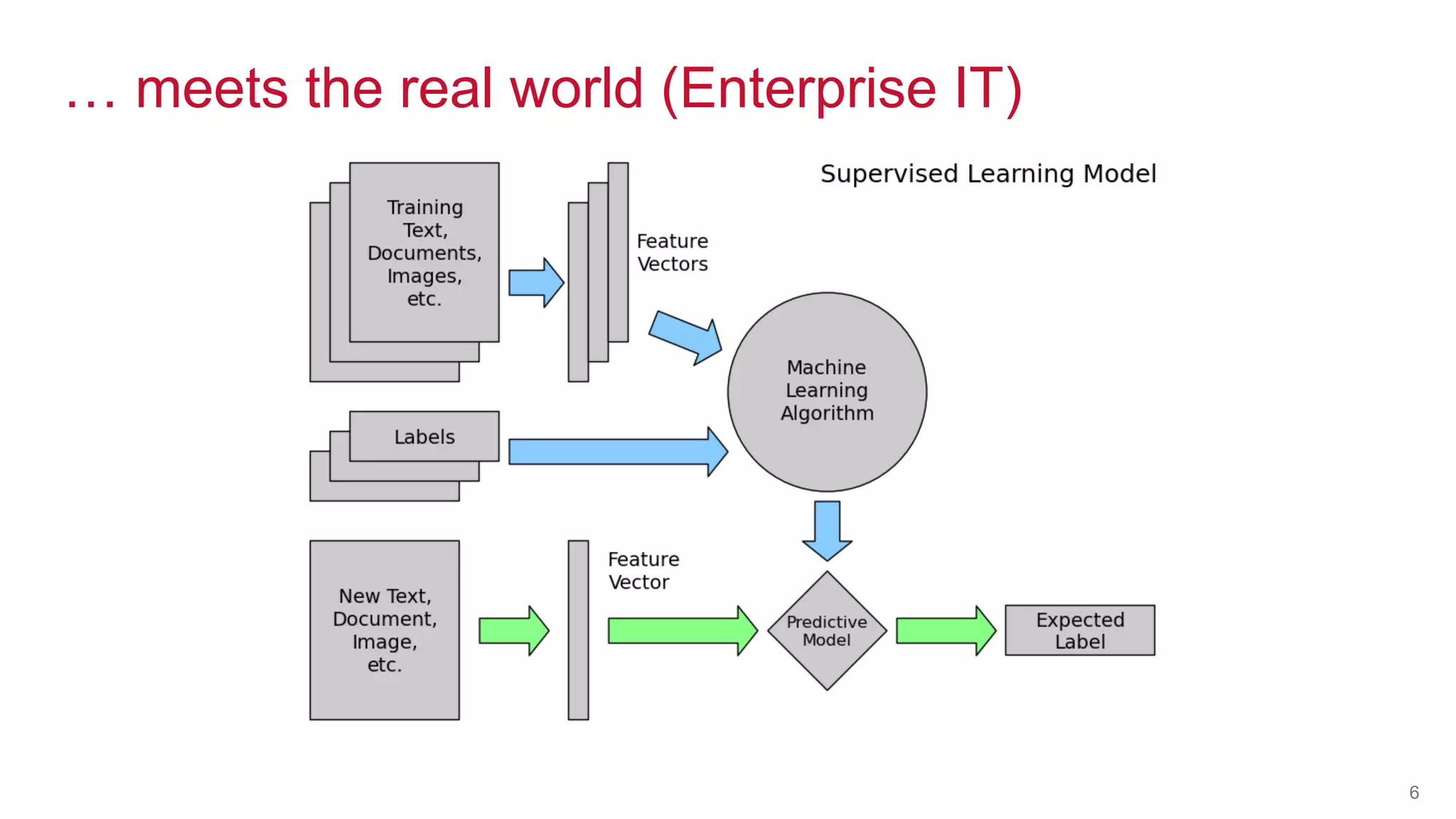
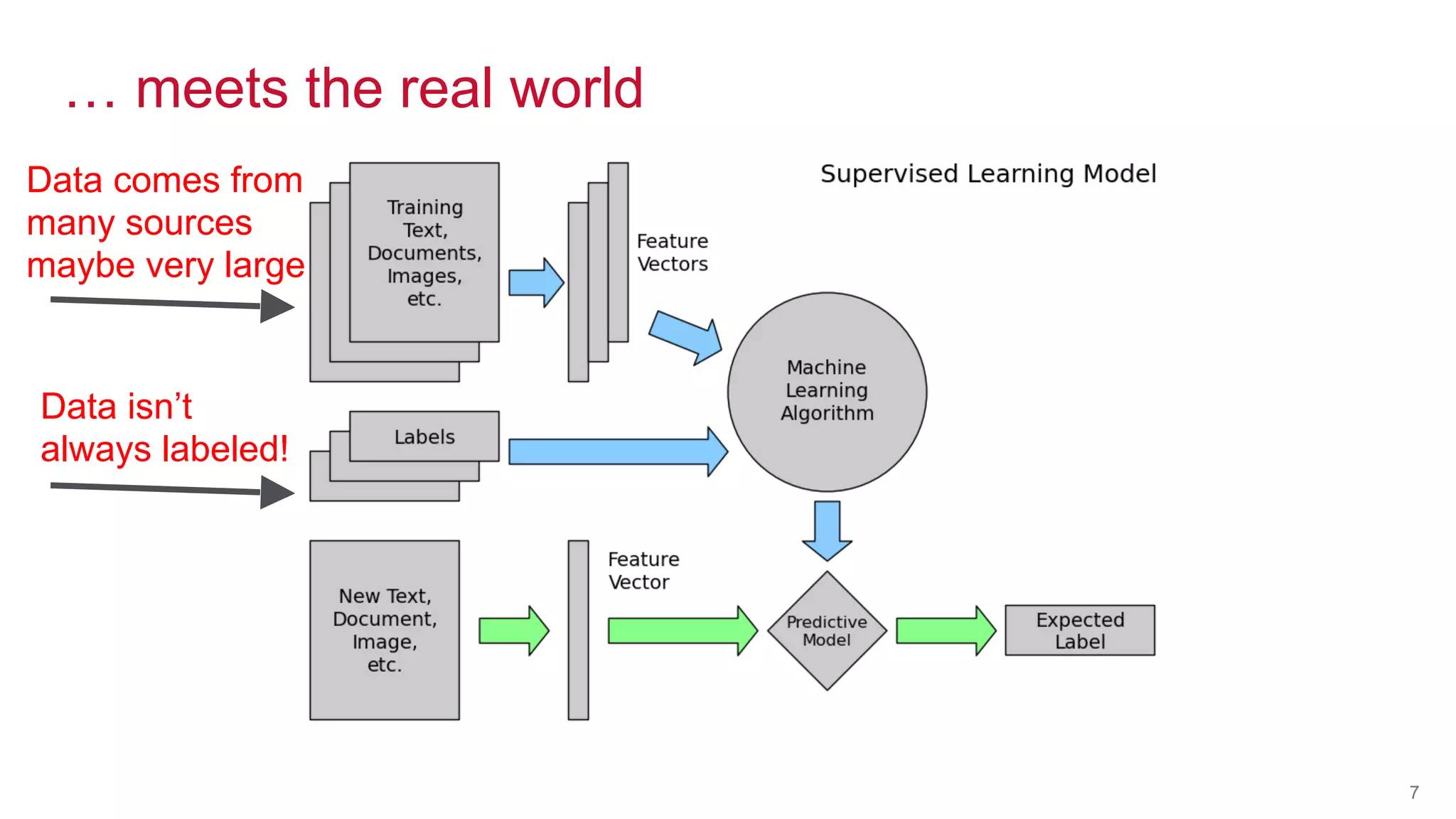
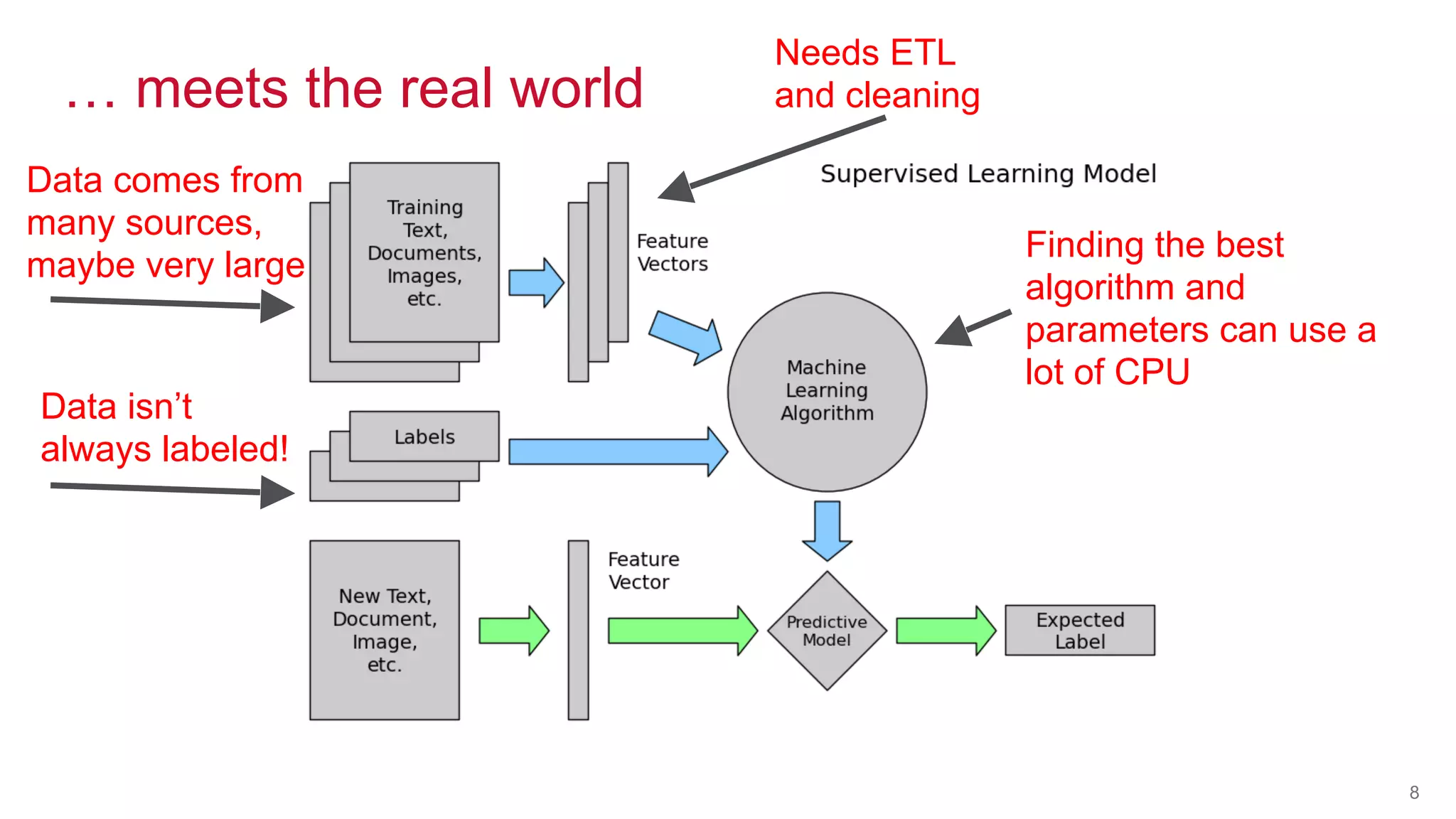
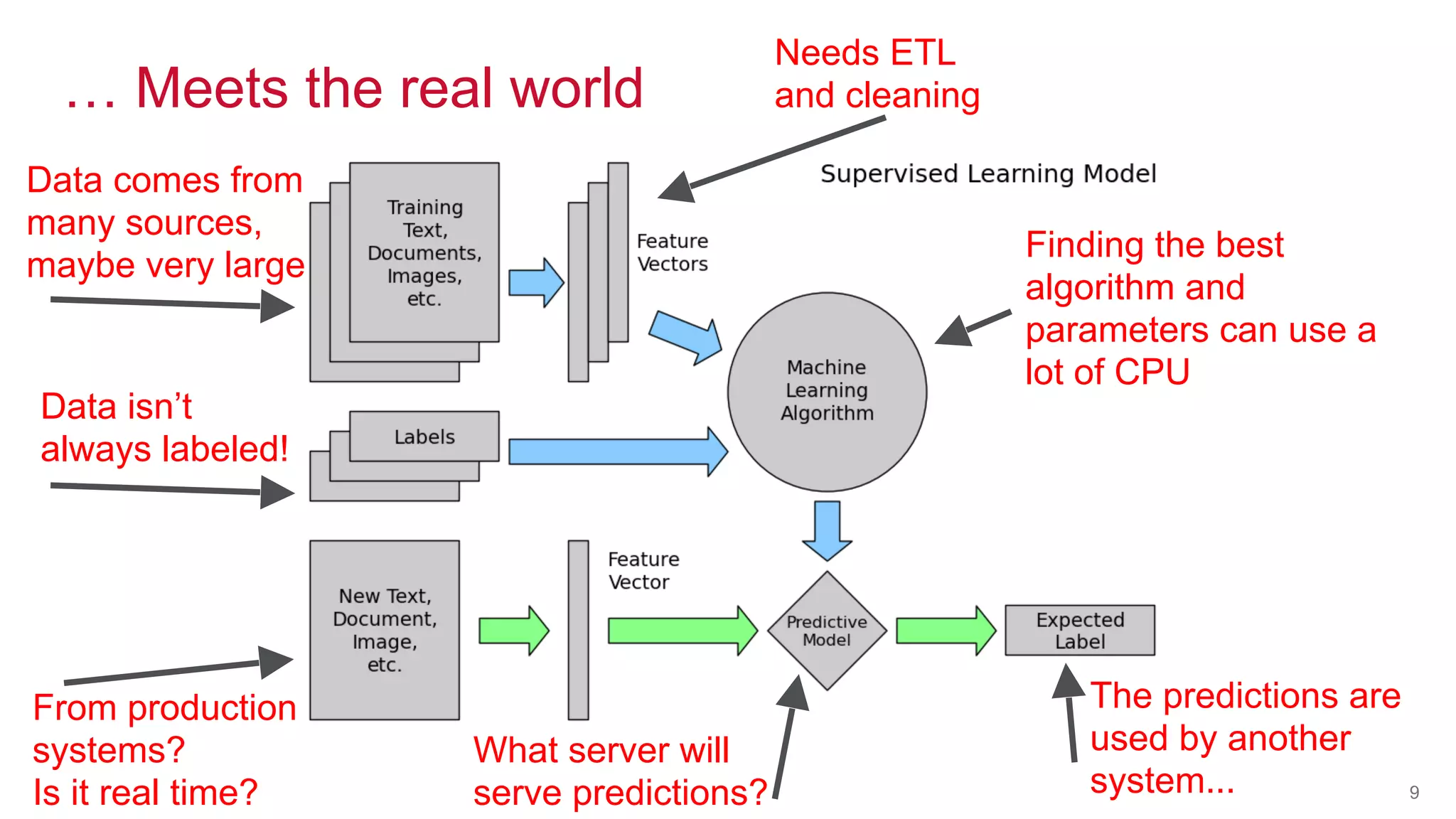
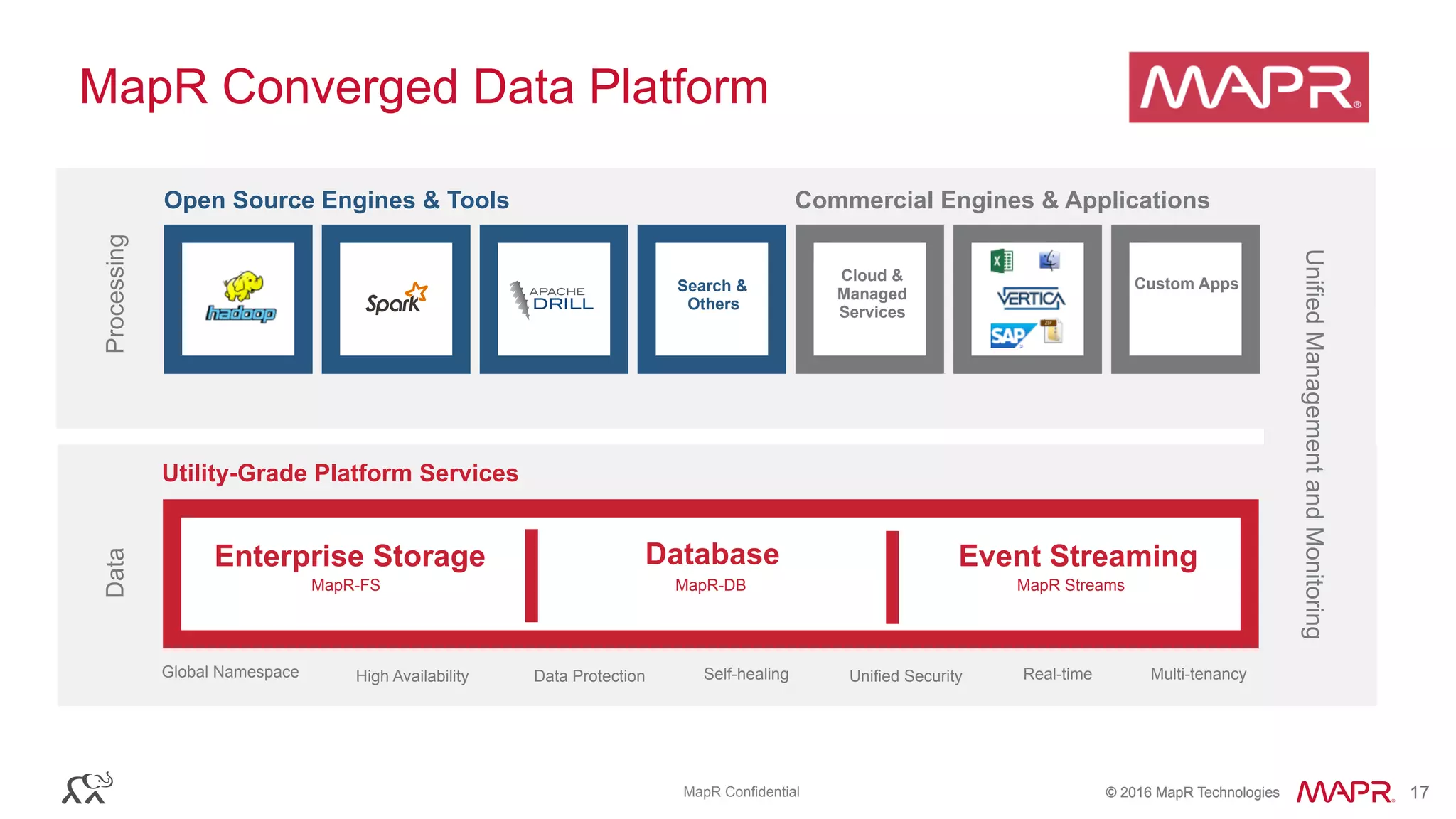
The document discusses the challenges of machine learning in enterprises and presents the MapR Converged Data Platform as a solution. It highlights key features that support machine learning processes, such as efficient data handling, integration capabilities, and real-time processing. The platform is designed to simplify machine learning workflows while maintaining security and robustness for enterprise applications.
































































































