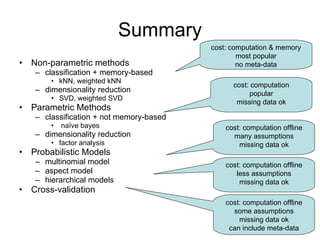
The document discusses several collaborative filtering techniques for making recommendations:
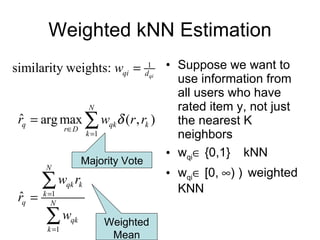
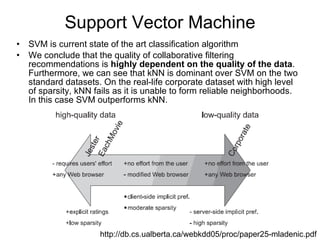
1) Nearest neighbor techniques like k-NN make predictions based on the ratings of similar users. They require storing all user data but can be fast with appropriate data structures.
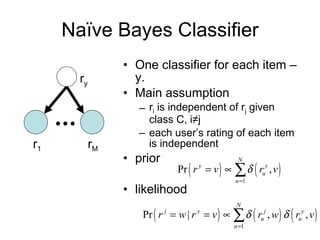
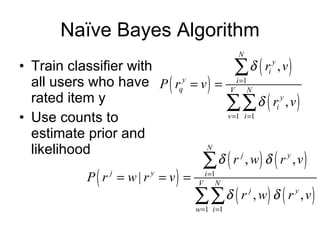
2) Naive Bayes classifiers treat each item's ratings independently; they make strong assumptions but require less data.
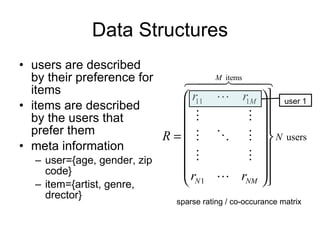
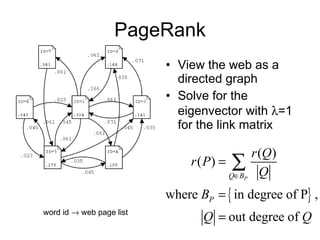
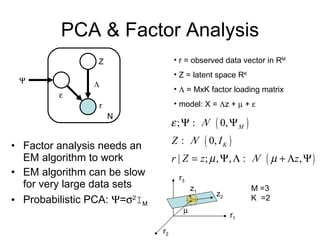
3) Dimensionality reduction techniques like SVD decompose the user-item rating matrix to find latent factors. Weighted SVD handles missing data.
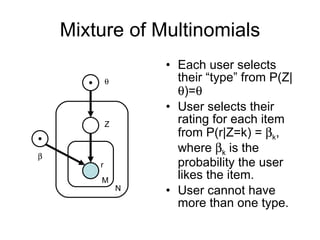
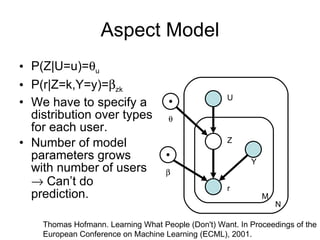
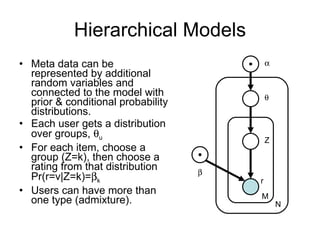
4) Probabilistic models like mixtures of multinomials and aspect models represent additional user metadata but have more parameters.
![Collaborative Filtering CS294 Practical Machine Learning Week 14 Pat Flaherty [email_address]](https://image.slidesharecdn.com/download2682/85/Download-1-320.jpg)






























![[WI 2014]Context Recommendation Using Multi-label Classification](https://cdn.slidesharecdn.com/ss_thumbnails/slidewic2014context-140805210546-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









![[SOCRS2013]Differential Context Modeling in Collaborative Filtering](https://cdn.slidesharecdn.com/ss_thumbnails/slide2013socrs2013differentialcontextmodelingincollaborativefiltering-130519153030-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[UMAP2013] Recommendation with Differential Context Weighting](https://cdn.slidesharecdn.com/ss_thumbnails/slide2013umap2013differentialcontextweighting-130611091905-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















































