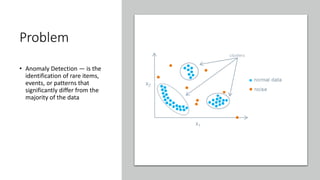
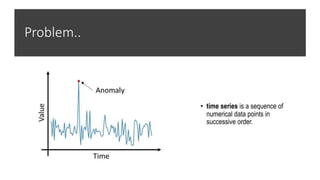
Download to read offline





![PTAD
formulation
• The state includes two parts:
• Sequence of previous actions Sa = (at-
m+1,at-m+2….at)
• Current time series St = (St-m+1, St-m+2, St)
• The state space S is infinite due to real time
series with a variety of alterations.
State:
• A = [0,1]
• 0: normal behavior
• 1: anomaly detection
Action:](https://image.slidesharecdn.com/rll-210407064430/85/Policy-Based-reinforcement-Learning-for-time-series-Anomaly-detection-7-320.jpg)



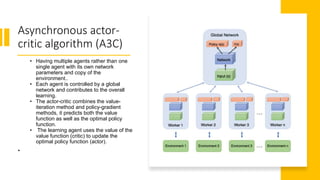
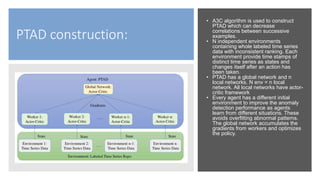
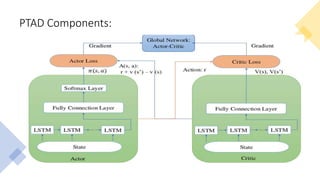
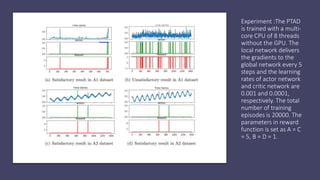
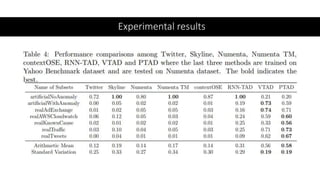




This document discusses a policy-based reinforcement learning approach called PTAD for time series anomaly detection. PTAD formulates anomaly detection as a Markov Decision Process and uses an asynchronous actor-critic algorithm to learn a stochastic policy. The agent takes as input current and previous time series data and actions, and outputs a decision of normal or anomalous. It is rewarded based on a confusion matrix calculation. Experimental results show PTAD achieves best performance both within and across datasets by adjusting to different behaviors. The stochastic policy allows exploring precision-recall tradeoffs. While interesting, it is not compared to neural network based techniques like autoencoders.






















































































