Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
955 views
[DL輪読会]Adversarial Learning for Zero-shot Domain Adaptation
2020/09/25 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 16
2
/ 16
3
/ 16
4
/ 16
5
/ 16
6
/ 16
7
/ 16
8
/ 16
9
/ 16
10
/ 16
11
/ 16
12
/ 16
13
/ 16
14
/ 16
15
/ 16
16
/ 16
More Related Content
PPTX
【DL輪読会】EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Pointsfor...
by
Deep Learning JP
PPTX
[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...
by
Deep Learning JP
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
PDF
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
PDF
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
PDF
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
PDF
[DL輪読会]Estimating Predictive Uncertainty via Prior Networks
by
Deep Learning JP
【DL輪読会】EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Pointsfor...
by
Deep Learning JP
[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...
by
Deep Learning JP
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
[DL輪読会]Estimating Predictive Uncertainty via Prior Networks
by
Deep Learning JP
What's hot
PDF
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
PPTX
【DL輪読会】DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Dri...
by
Deep Learning JP
PDF
動作認識の最前線:手法,タスク,データセット
by
Toru Tamaki
PPTX
SfM Learner系単眼深度推定手法について
by
Ryutaro Yamauchi
PDF
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
PDF
ICLR2019 読み会in京都 ICLRから読み取るFeature Disentangleの研究動向
by
Yamato OKAMOTO
PPTX
[DL輪読会]Objects as Points
by
Deep Learning JP
PDF
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
PDF
【DL輪読会】Hierarchical Text-Conditional Image Generation with CLIP Latents
by
Deep Learning JP
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
【CVPR 2019】DeepSDF: Learning Continuous Signed Distance Functions for Shape R...
by
cvpaper. challenge
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
PDF
【DL輪読会】"Masked Siamese Networks for Label-Efficient Learning"
by
Deep Learning JP
PPTX
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
PDF
「解説資料」Toward Fast and Stabilized GAN Training for High-fidelity Few-shot Imag...
by
Takumi Ohkuma
PPTX
SSII2020SS: 微分可能レンダリングの最新動向 〜「見比べる」ことによる3次元理解 〜
by
SSII
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
【DL輪読会】DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Dri...
by
Deep Learning JP
動作認識の最前線:手法,タスク,データセット
by
Toru Tamaki
SfM Learner系単眼深度推定手法について
by
Ryutaro Yamauchi
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
ICLR2019 読み会in京都 ICLRから読み取るFeature Disentangleの研究動向
by
Yamato OKAMOTO
[DL輪読会]Objects as Points
by
Deep Learning JP
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
【DL輪読会】Hierarchical Text-Conditional Image Generation with CLIP Latents
by
Deep Learning JP
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
【CVPR 2019】DeepSDF: Learning Continuous Signed Distance Functions for Shape R...
by
cvpaper. challenge
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
【DL輪読会】"Masked Siamese Networks for Label-Efficient Learning"
by
Deep Learning JP
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
「解説資料」Toward Fast and Stabilized GAN Training for High-fidelity Few-shot Imag...
by
Takumi Ohkuma
SSII2020SS: 微分可能レンダリングの最新動向 〜「見比べる」ことによる3次元理解 〜
by
SSII
Similar to [DL輪読会]Adversarial Learning for Zero-shot Domain Adaptation
PDF
【ECCV 2018】Zero-Shot Deep Domain Adaptation
by
cvpaper. challenge
PDF
ICLR'19 研究動向まとめ 『Domain Adaptation』『Feature Disentangle』
by
Yamato OKAMOTO
PPTX
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
by
Yusuke Iwasawa
PDF
Learning Semantic Representations for Unsupervised Domain Adaptation 論文紹介
by
Tsukasa Takagi
PDF
Domain Adaptive Faster R-CNN for Object Detection in the Wild 論文紹介
by
Tsukasa Takagi
PDF
【DL輪読会】Domain Generalization by Learning and Removing Domainspecific Features
by
Deep Learning JP
PPTX
機械学習を民主化する取り組み
by
Yoshitaka Ushiku
PDF
[DL Hacks]Self-Attention Generative Adversarial Networks
by
Deep Learning JP
PDF
Adversarial Examples 分野の動向 (敵対的サンプル発表資料)
by
cvpaper. challenge
PDF
第4回 NIPS+読み会・関西 発表資料 山本
by
Yahoo!デベロッパーネットワーク
PPTX
[DL輪読会]Unsupervised Cross-Domain Image Generation
by
Deep Learning JP
PDF
【DL輪読会】One-Shot Domain Adaptive and Generalizable Semantic Segmentation with ...
by
Deep Learning JP
PDF
論文紹介 DANN
by
Komkom4
PPTX
[DL輪読会]High-Fidelity Image Generation with Fewer Labels
by
Deep Learning JP
PDF
ICLR'19 読み会 in 京都 [LT枠] Domain Adaptationの研究動向
by
Yamato OKAMOTO
PDF
Adversarial Networks の画像生成に迫る @WBAFLカジュアルトーク#3
by
Daiki Shimada
PDF
[DL輪読会]Causality Inspired Representation Learning for Domain Generalization
by
Deep Learning JP
PPTX
[DL輪読会]Adversarial Text Generation via Feature-Mover's Distance (NIPS 2018)
by
Deep Learning JP
PDF
CVPR2019@ロングビーチ参加速報(後編 ~本会議~)
by
Yamato OKAMOTO
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【ECCV 2018】Zero-Shot Deep Domain Adaptation
by
cvpaper. challenge
ICLR'19 研究動向まとめ 『Domain Adaptation』『Feature Disentangle』
by
Yamato OKAMOTO
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
by
Yusuke Iwasawa
Learning Semantic Representations for Unsupervised Domain Adaptation 論文紹介
by
Tsukasa Takagi
Domain Adaptive Faster R-CNN for Object Detection in the Wild 論文紹介
by
Tsukasa Takagi
【DL輪読会】Domain Generalization by Learning and Removing Domainspecific Features
by
Deep Learning JP
機械学習を民主化する取り組み
by
Yoshitaka Ushiku
[DL Hacks]Self-Attention Generative Adversarial Networks
by
Deep Learning JP
Adversarial Examples 分野の動向 (敵対的サンプル発表資料)
by
cvpaper. challenge
第4回 NIPS+読み会・関西 発表資料 山本
by
Yahoo!デベロッパーネットワーク
[DL輪読会]Unsupervised Cross-Domain Image Generation
by
Deep Learning JP
【DL輪読会】One-Shot Domain Adaptive and Generalizable Semantic Segmentation with ...
by
Deep Learning JP
論文紹介 DANN
by
Komkom4
[DL輪読会]High-Fidelity Image Generation with Fewer Labels
by
Deep Learning JP
ICLR'19 読み会 in 京都 [LT枠] Domain Adaptationの研究動向
by
Yamato OKAMOTO
Adversarial Networks の画像生成に迫る @WBAFLカジュアルトーク#3
by
Daiki Shimada
[DL輪読会]Causality Inspired Representation Learning for Domain Generalization
by
Deep Learning JP
[DL輪読会]Adversarial Text Generation via Feature-Mover's Distance (NIPS 2018)
by
Deep Learning JP
CVPR2019@ロングビーチ参加速報(後編 ~本会議~)
by
Yamato OKAMOTO
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PPTX
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
[DL輪読会]Adversarial Learning for Zero-shot Domain Adaptation
1.
DEEP LEARNING JP [DL
Papers] Adversarial Learning for Zero-shot Domain Adaptation Yuting Lin, Kokusai Kogyo Co., Ltd.(国際航業) http://deeplearning.jp/ 1
2.
書籍情報 • タイトル Adversarial Learning
for Zero-shot Domain Adaptation • 著者 Jinghua Wang and Jianmin Jiang Shenzhen University • ECCV2020(poster)に採択 • ICCV2019にも、Zero-Shot Domain Adaptation(ZSDA)の論文を投稿した (Conditional Coupled Generative Adversarial Networks for Zero-Shot Domain Adaptation) 2
3.
概要 • 手法の概要: target domainがないzero-shot
domain adaptationタスクにおいて、 domainと同じだが、他種別のデータで学習したdomain shiftを適用して target domainのデータを生成する手法 • 提案手法のポイント target/source domainと同じdomainの別の画像データから、domain shift を学習 domain shiftを用いてtarget domainの画像を生成する Co-training方策で、性能を向上する 3
4.
• ToI(Task of
Interest)において、target domainのデータが存在しない ToIのdomainと同じかつ、取得できる画像から、IrT(irrelevant task)の学習より、domain shiftを取得する データの表記: ToI source: 𝑋𝑠 𝛼 ToI target: 𝑿 𝒕 𝜶 (生成対象) IrT source: 𝑋𝑠 𝛽 IrT target: 𝑋𝑡 𝛽 問題定義 4
5.
既往研究 • Zero-Shot Domain
Adaptationは3つの流派がある ① domain-invariant featuresを抽出することで、domainが異なっても認識できるモデルを 学習する Domain-invariant component analysis (DICA)[1]、 multi-task autoencoder (MTAE)[2]、 Conditional invariant deep domain generalization (CIDDG)[3]、 deep domain generalization framework (DDG) [4] ② domain情報は、潜在空間上のdomainに依存しないcommon factorとdomain specific factorにより決定されると仮定する。 common factorが分かれば、unseen domainに適 応できる[5], [6], [7], [8] ③ target/source domainの関係性を、別のタスクにより学習し、データに適応する Zero-shot deep domain adaptation (ZDDA) [9]、 CoCoGAN[10] 5 [1] Muandet, K., Balduzzi, D., Sch¨olkopf, B.: Domain generalization via invariant feature representation. In: ICML (2013) [2] Ghifary, M., Kleijn, W.B., Zhang, M., Balduzzi, D.: Domain generalization for object recognition with multi-task autoencoders. In: ICCV (2015) [3] Li, Y., Tian, X., Gong, M., Liu, Y., Liu, T., Zhang, K., Tao, D.: Deep domain generalization via conditional invariant adversarial networks. In: ECCV (2018) [4] Ding, Z., Fu, Y.: Deep domain generalization with structured low-rank constraint. IEEE Transactions on Image Processing 27(1), 304–313 (2018) [5] Khosla, A., Zhou, T., Malisiewicz, T., Efros, A.A., Torralba, A.: Undoing the damage of dataset bias. In: ECCV (2012) [6] Li, D., Yang, Y., Song, Y.Z., Hospedales, T.M.: Deeper, broader and artier domain generalization. In: ICCV (2017) [7] Yang, Y., Hospedales, T.: Zero-shot domain adaptation via kernel regression on the grassmannian (2015). https://doi.org/10.5244/C.29.DIFFCV.1 [8] Kodirov, E., Xiang, T., Fu, Z., Gong, S.: Unsupervised domain adaptation for zero-shot learning. In: ICCV (2015) [9] Peng, K.C., Wu, Z., Ernst, J.: Zero-shot deep domain adaptation. In: ECCV (2018) [10] Wang, J., Jiang, J.: Conditional coupled generative adversarial networks for zero- shot domain adaptation. In: ICCV (2019)
6.
既往研究 • Coupled Generative
Adversarial Networks (CoGAN)[11] 生成器と識別器の一部分のパラメータを共有する2つのGANを持つ 異なるドメインの画像を同時に生成する 提案手法は、CoGANの構造に基づく 6[11] Liu, M.Y.,Tuzel, O.: Coupled generative adversarial networks. In: NIPS (2016)
7.
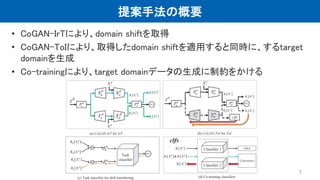
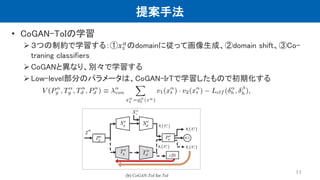
提案手法の概要 • CoGAN-IrTにより、domain shiftを取得 •
CoGAN-ToIにより、取得したdomain shiftを適用すると同時に、するtarget domainを生成 • Co-trainingにより、target domainデータの生成に制約をかける 7
8.
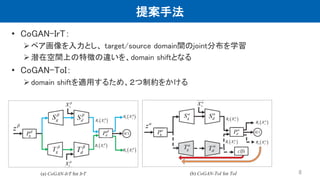
提案手法 • CoGAN-IrT: ペア画像を入力とし、 target/source
domain間のjoint分布を学習 潜在空間上の特徴の違いを、domain shiftとなる • CoGAN-ToI: domain shiftを適用するため、2つ制約をかける 8
9.
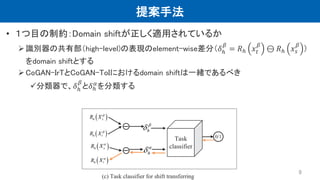
提案手法 • 1つ目の制約:Domain shiftが正しく適用されているか 識別器の共有部(high-level)の表現のelement-wise差分(𝛿ℎ 𝛽 =
𝑅ℎ 𝑥𝑡 𝛽 ⊖ 𝑅ℎ 𝑥 𝑠 𝛽 ) をdomain shiftとする CoGAN-IrTとCoGAN-ToIにおけるdomain shiftは一緒であるべき 分類器で、𝛿ℎ 𝛽 と𝛿ℎ 𝛼 を分類する 9
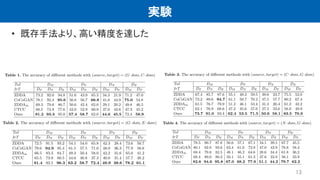
10.
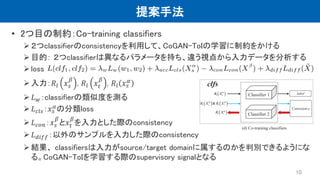
提案手法 • 2つ目の制約:Co-training classifiers 2つclassifierのconsistencyを利用して、CoGAN-ToIの学習に制約をかける 目的:
2つclassifierは異なるパラメータを持ち、違う視点から入力データを分析する loss 入力:𝑅𝑙 𝑥 𝑠 𝛽 , 𝑅𝑙 𝑥𝑡 𝛽 , 𝑅𝑙 𝑥 𝑠 𝛼 𝐿 𝑤:classifierの類似度を測る 𝐿 𝑐𝑙𝑠:𝑥 𝑠 𝛼 の分類loss 𝐿 𝑐𝑜𝑛:𝑥 𝑠 𝛽 と𝑥𝑡 𝛽 を入力とした際のconsistency 𝐿 𝑑𝑖𝑓𝑓:以外のサンプルを入力した際のconsistency 結果、 classifiersは入力がsource/target domainに属するのかを判別できるようにな る。CoGAN-ToIを学習する際のsupervisory signalとなる 10
11.
提案手法 • CoGAN-ToIの学習 3つの制約で学習する:①𝑥 𝑠 𝛼のdomainに従って画像生成、②domain
shift、③Co- traning classifiers CoGANと異なり、別々で学習する Low-level部分のパラメータは、CoGAN-IrTで学習したもので初期化する 11
12.
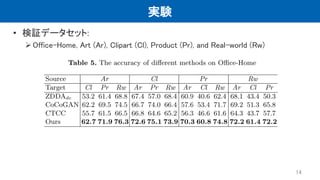
実験 • 検証データセット: MNIST (DM),
Fashion-MNIST (DF), NIST (DN), EMNIST (DE) • 検証domain: gray domain (G–dom), colored domain (C–dom), edge domain (E–dom), negative domain (N–dom) 12
13.
実験 • 既存手法より、高い精度を達した 13
14.
実験 • 検証データセット: Office-Home, Art
(Ar), Clipart (Cl), Product (Pr), and Real-world (Rw) 14
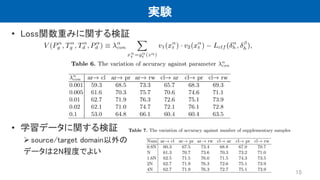
15.
実験 • Loss関数重みに関する検証 • 学習データに関する検証 source/target
domain以外の データは2N程度でよい 15
16.
まとめ • zero-shot domain
adaptationタスクについて、target domain画像を生成す る手法を提案した • 学習したdomain shiftを生成に適用すること、Co-training classifierにより、 target domain画像の生成に制約をかけることで、性能を向上する • Co-training classifierでは、consistency lossを活用し、supervisory signalを 作り出すことで、学習に制約をかけた • 本提案手法は、物体認識やセグメンテーションにも適用可能 • target domainのデータがないことは、実利用する際によくある課題のため、 参加になった 16
Download
![DEEP LEARNING JP
[DL Papers]
Adversarial Learning for Zero-shot Domain Adaptation
Yuting Lin, Kokusai Kogyo Co., Ltd.(国際航業)
http://deeplearning.jp/
1](https://image.slidesharecdn.com/20200925lin-200925035639/85/DL-Adversarial-Learning-for-Zero-shot-Domain-Adaptation-1-320.jpg)



![既往研究
• Zero-Shot Domain Adaptationは3つの流派がある
① domain-invariant featuresを抽出することで、domainが異なっても認識できるモデルを
学習する
Domain-invariant component analysis (DICA)[1]、 multi-task autoencoder (MTAE)[2]、 Conditional
invariant deep domain generalization (CIDDG)[3]、 deep domain generalization framework (DDG) [4]
② domain情報は、潜在空間上のdomainに依存しないcommon factorとdomain specific
factorにより決定されると仮定する。 common factorが分かれば、unseen domainに適
応できる[5], [6], [7], [8]
③ target/source domainの関係性を、別のタスクにより学習し、データに適応する
Zero-shot deep domain adaptation (ZDDA) [9]、 CoCoGAN[10]
5
[1] Muandet, K., Balduzzi, D., Sch¨olkopf, B.: Domain generalization via invariant feature representation. In: ICML (2013)
[2] Ghifary, M., Kleijn, W.B., Zhang, M., Balduzzi, D.: Domain generalization for object recognition with multi-task autoencoders. In: ICCV (2015)
[3] Li, Y., Tian, X., Gong, M., Liu, Y., Liu, T., Zhang, K., Tao, D.: Deep domain generalization via conditional invariant adversarial networks. In: ECCV (2018)
[4] Ding, Z., Fu, Y.: Deep domain generalization with structured low-rank constraint. IEEE Transactions on Image Processing 27(1), 304–313 (2018)
[5] Khosla, A., Zhou, T., Malisiewicz, T., Efros, A.A., Torralba, A.: Undoing the damage of dataset bias. In: ECCV (2012)
[6] Li, D., Yang, Y., Song, Y.Z., Hospedales, T.M.: Deeper, broader and artier domain generalization. In: ICCV (2017)
[7] Yang, Y., Hospedales, T.: Zero-shot domain adaptation via kernel regression on the grassmannian (2015). https://doi.org/10.5244/C.29.DIFFCV.1
[8] Kodirov, E., Xiang, T., Fu, Z., Gong, S.: Unsupervised domain adaptation for zero-shot learning. In: ICCV (2015)
[9] Peng, K.C., Wu, Z., Ernst, J.: Zero-shot deep domain adaptation. In: ECCV (2018)
[10] Wang, J., Jiang, J.: Conditional coupled generative adversarial networks for zero- shot domain adaptation. In: ICCV (2019)](https://image.slidesharecdn.com/20200925lin-200925035639/85/DL-Adversarial-Learning-for-Zero-shot-Domain-Adaptation-5-320.jpg)
![既往研究
• Coupled Generative Adversarial Networks (CoGAN)[11]
生成器と識別器の一部分のパラメータを共有する2つのGANを持つ
異なるドメインの画像を同時に生成する
提案手法は、CoGANの構造に基づく
6[11] Liu, M.Y.,Tuzel, O.: Coupled generative adversarial networks. In: NIPS (2016)](https://image.slidesharecdn.com/20200925lin-200925035639/85/DL-Adversarial-Learning-for-Zero-shot-Domain-Adaptation-6-320.jpg)




![[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...](https://cdn.slidesharecdn.com/ss_thumbnails/181214dlpointnet-181214053349-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Estimating Predictive Uncertainty via Prior Networks](https://cdn.slidesharecdn.com/ss_thumbnails/estimatingpredictiveuncertaintyviapriornetworks-190628002736-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL Hacks]Self-Attention Generative Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/self-attentiongenerativeadversarialnetworks-180730075733-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Unsupervised Cross-Domain Image Generation](https://cdn.slidesharecdn.com/ss_thumbnails/readingpaper20170310-170310051823-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)
![ICLR'19 読み会 in 京都 [LT枠] Domain Adaptationの研究動向](https://cdn.slidesharecdn.com/ss_thumbnails/iclr19inkyotolt-190528091335-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Causality Inspired Representation Learning for Domain Generalization](https://cdn.slidesharecdn.com/ss_thumbnails/20220422lin-220422031920-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Adversarial Text Generation via Feature-Mover's Distance (NIPS 2018)](https://cdn.slidesharecdn.com/ss_thumbnails/dl20181102-181102003608-thumbnail.jpg?width=640&height=640&fit=bounds)





















