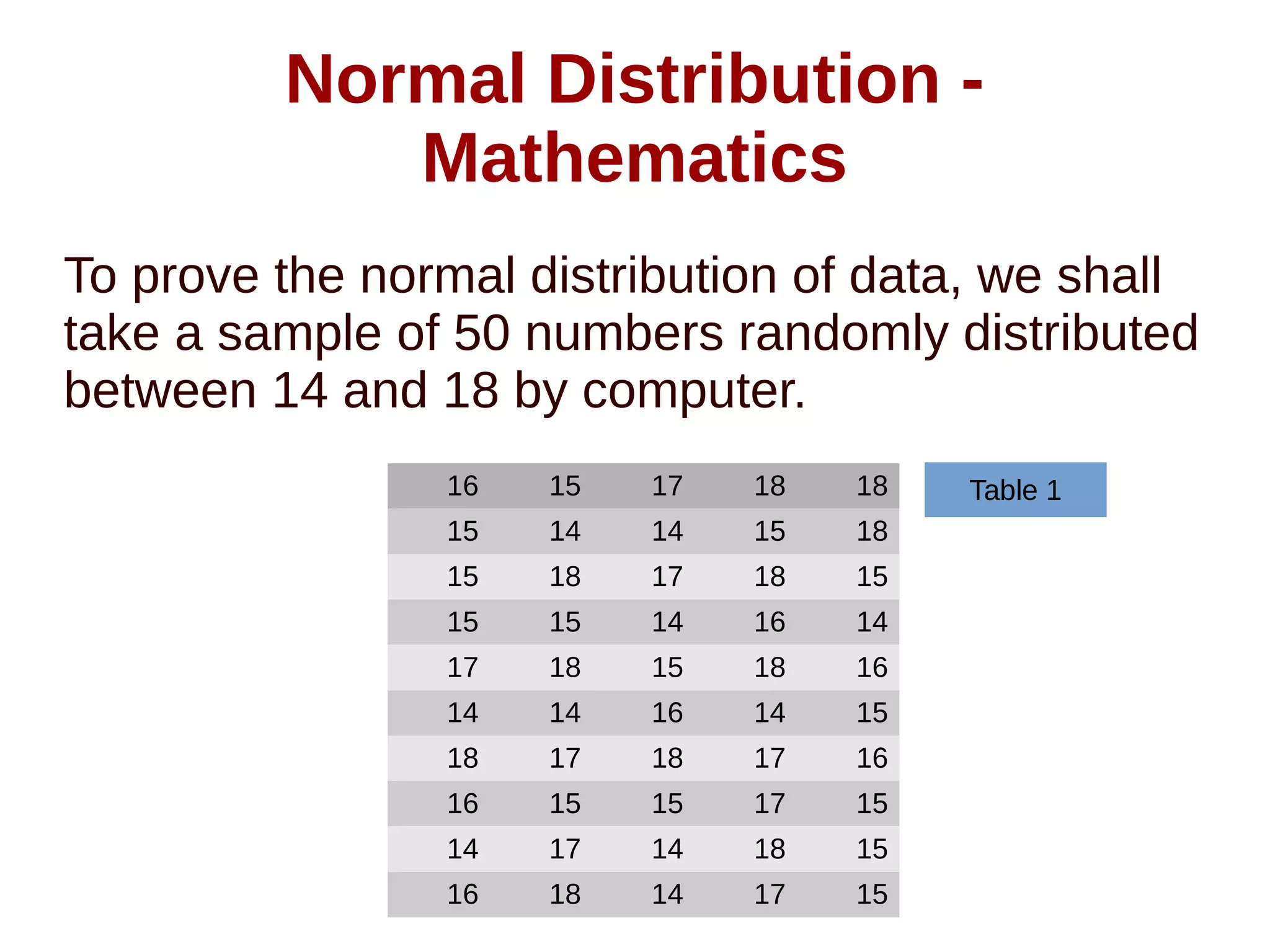
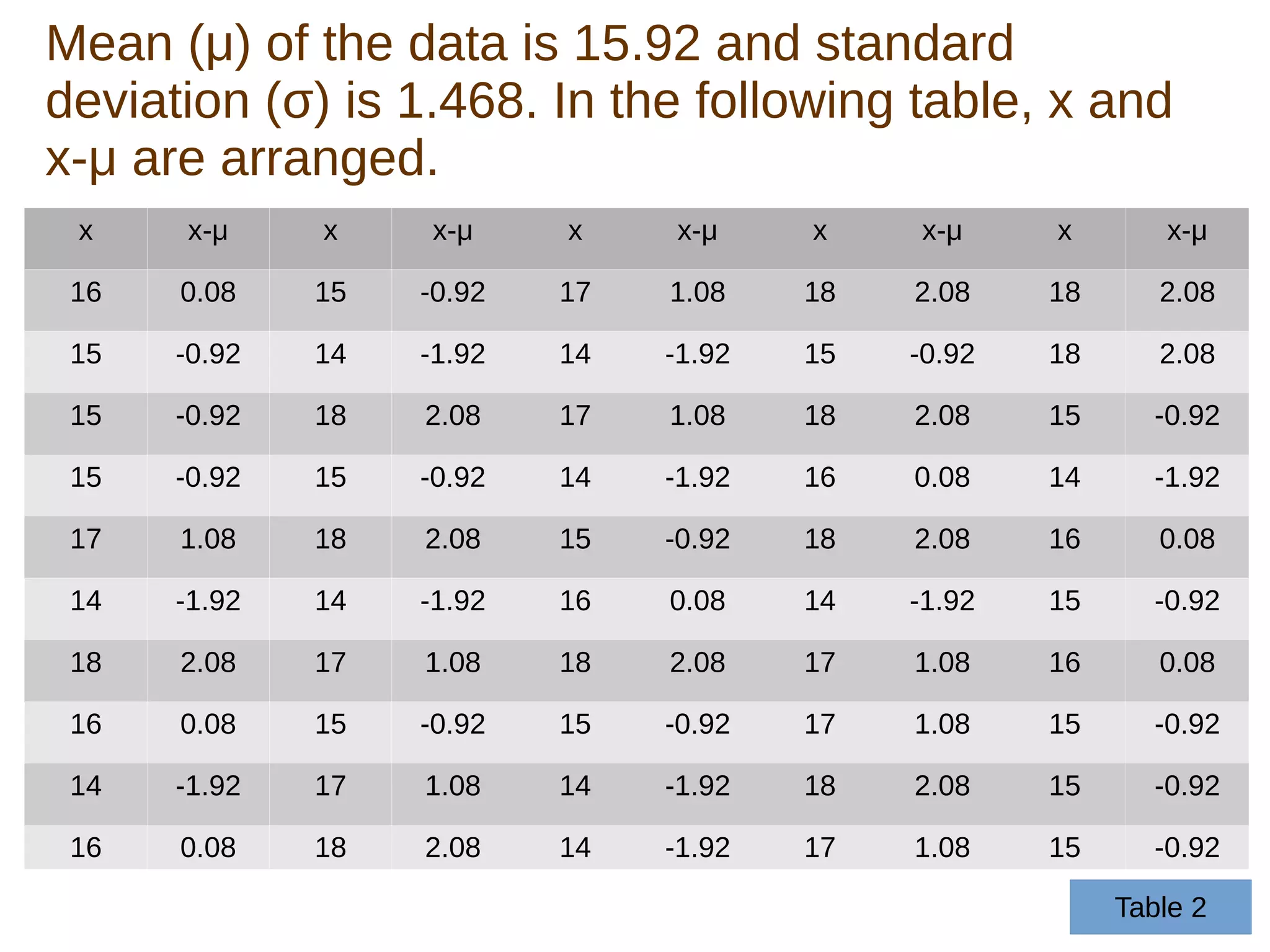
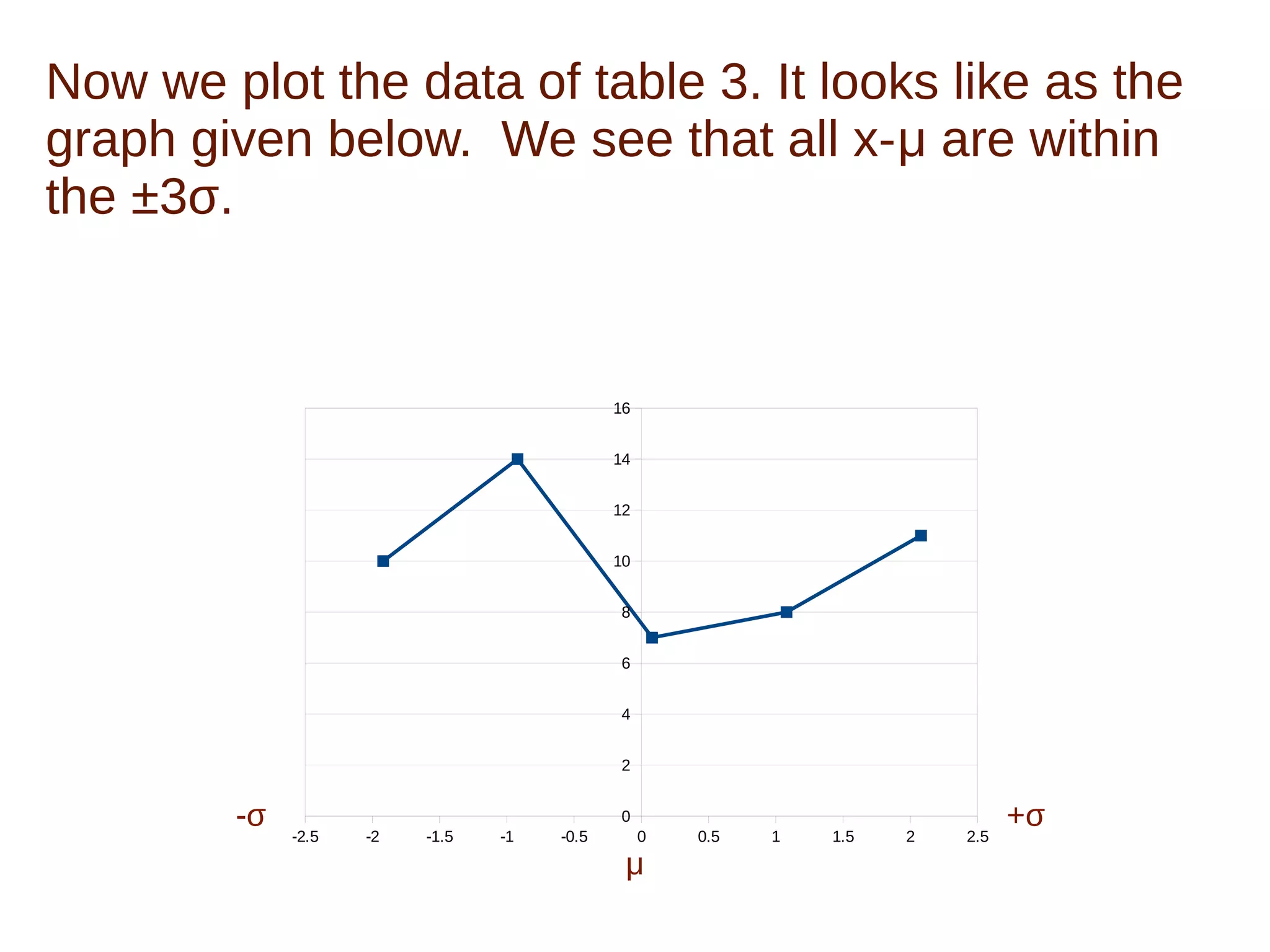
The document discusses the characteristics of normal data distribution, emphasizing its symmetry around the mean and the 99.7% of data within three standard deviations. It defines population and sample data, explaining the statistical properties that can be derived from each, particularly when sample sizes exceed 30. The text illustrates the normal distribution through mathematical examples and data plotting, concluding that real data typically produces an inverted bell shape in the distribution graph.








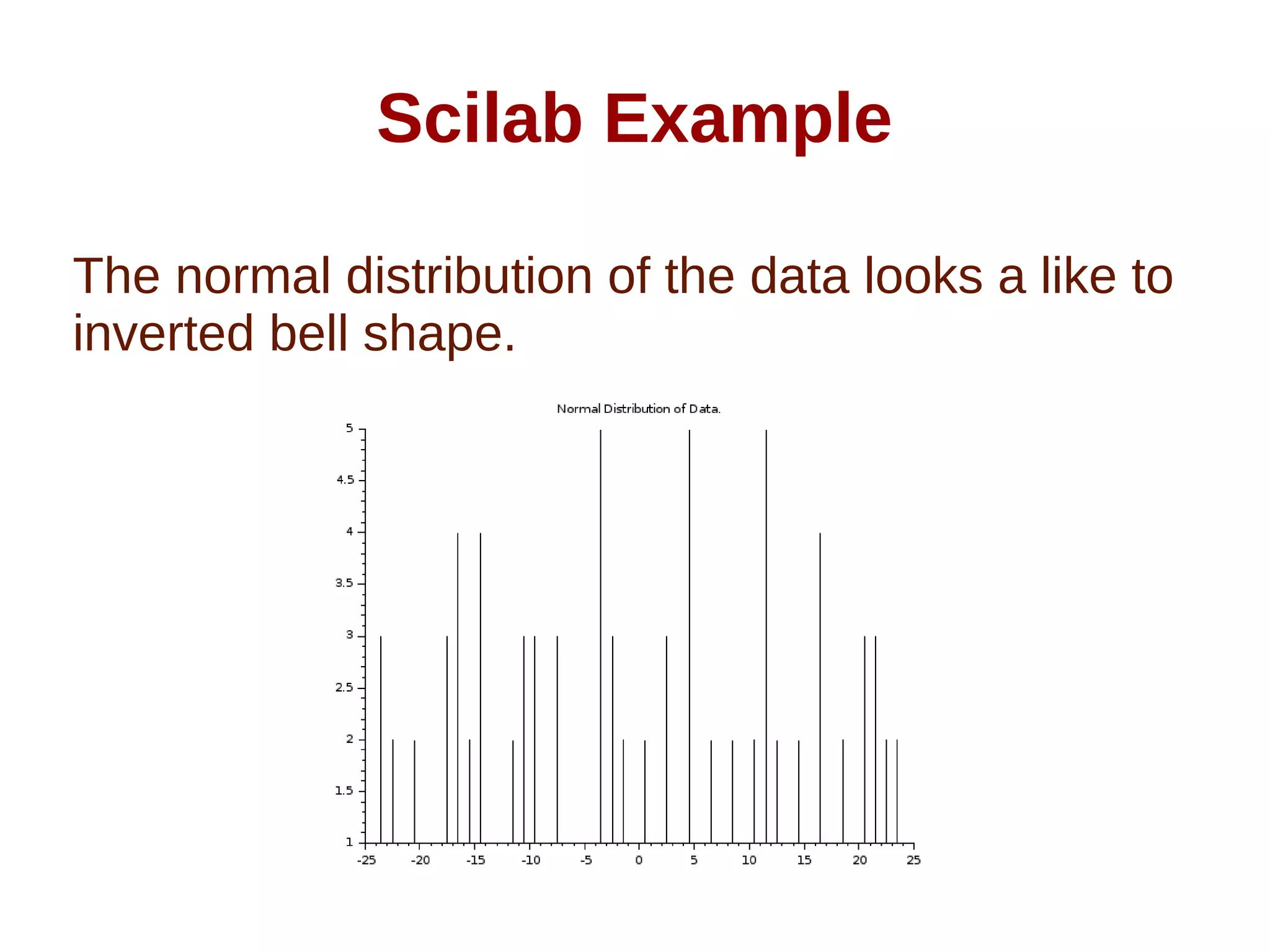
![Scilab Example
● x=[442 401 412 416 437 406 428 447 439 408 411 403 448 415 438 410
440 414 446 434 408 443 419 426 447 425 429 442 441 428 436 449 423
431 434 409 424 402 445 430 402 407 418 450 422 409 448 428 414 437
437 411 411 446 430 415 422 447 410 415 404 430 426 433 446 422 437
444 440 430 418 436 420 421 432 409 423 444 424 423 449 405 422 411
442 422 432 417 402 403 409 430 416 408 437 405 416 438 418 442]
● m=mean(x);
● d=x-m
● f = tabul(d,"i");
● clf()
● plot2d3(f(:,1), f(:,2))
● xtitle("Normal Distribution of Data.")](https://image.slidesharecdn.com/distributionofnormaldata-understandingitnumericalwaybyarunumrao-211023091951/75/Distribution-of-Normal-Data-12-2048.jpg)
























![PM [B03] Complex Coordinate](https://cdn.slidesharecdn.com/ss_thumbnails/pmb03complexcoordinate-151009051941-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





























































