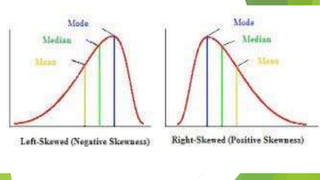
The document discusses key concepts related to the normal distribution, including its properties, formula, and uses. Some key points:
- The normal distribution is a bell-shaped curve that is symmetric around the mean. Many natural phenomena approximate it.
- It is defined by two parameters: the mean and standard deviation. Approximately 68% of values fall within one standard deviation of the mean, 95% within two standard deviations, and 99.7% within three standard deviations.
- The normal distribution follows a specific formula involving the mean, standard deviation, and z-scores.
- Other concepts discussed include skewness, kurtosis, the t-distribution and how it resembles the normal distribution, and