Download to read offline















![Page 25
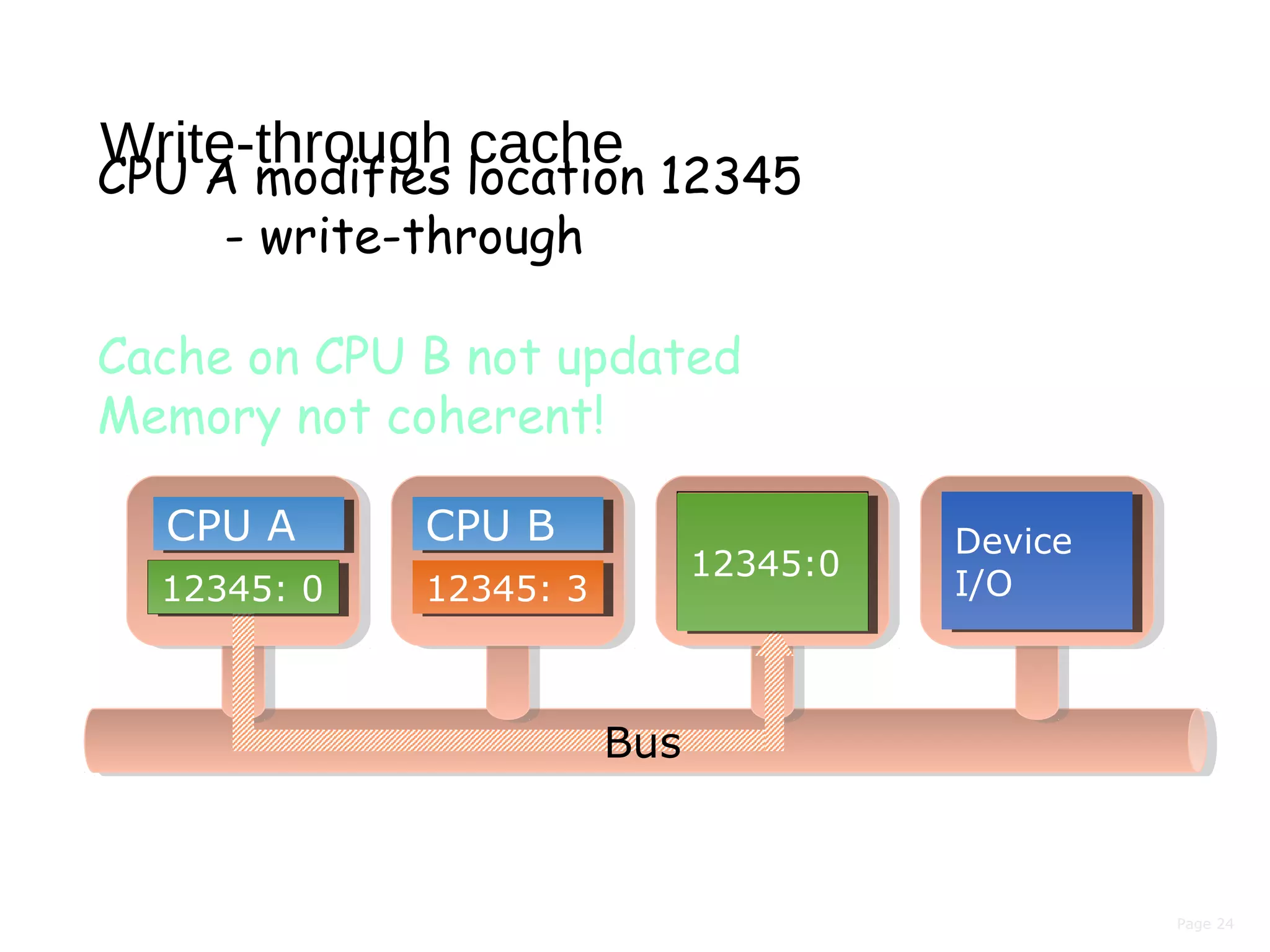
Snoopy cache
Add logic to each cache controller:
monitor the bus
12345: 3
Device
I/O
Device
I/O
CPU ACPU A
12345: 3
CPU BCPU B
12345: 3
write [12345]← 0
12345: 3
Virtually all bus-based architectures
use a snoopy cache
Bus
12345: 012345: 0
12345: 012345: 0
12345: 012345: 0](https://image.slidesharecdn.com/distributedsystems-170203111133/75/Distributed-systems-25-2048.jpg)

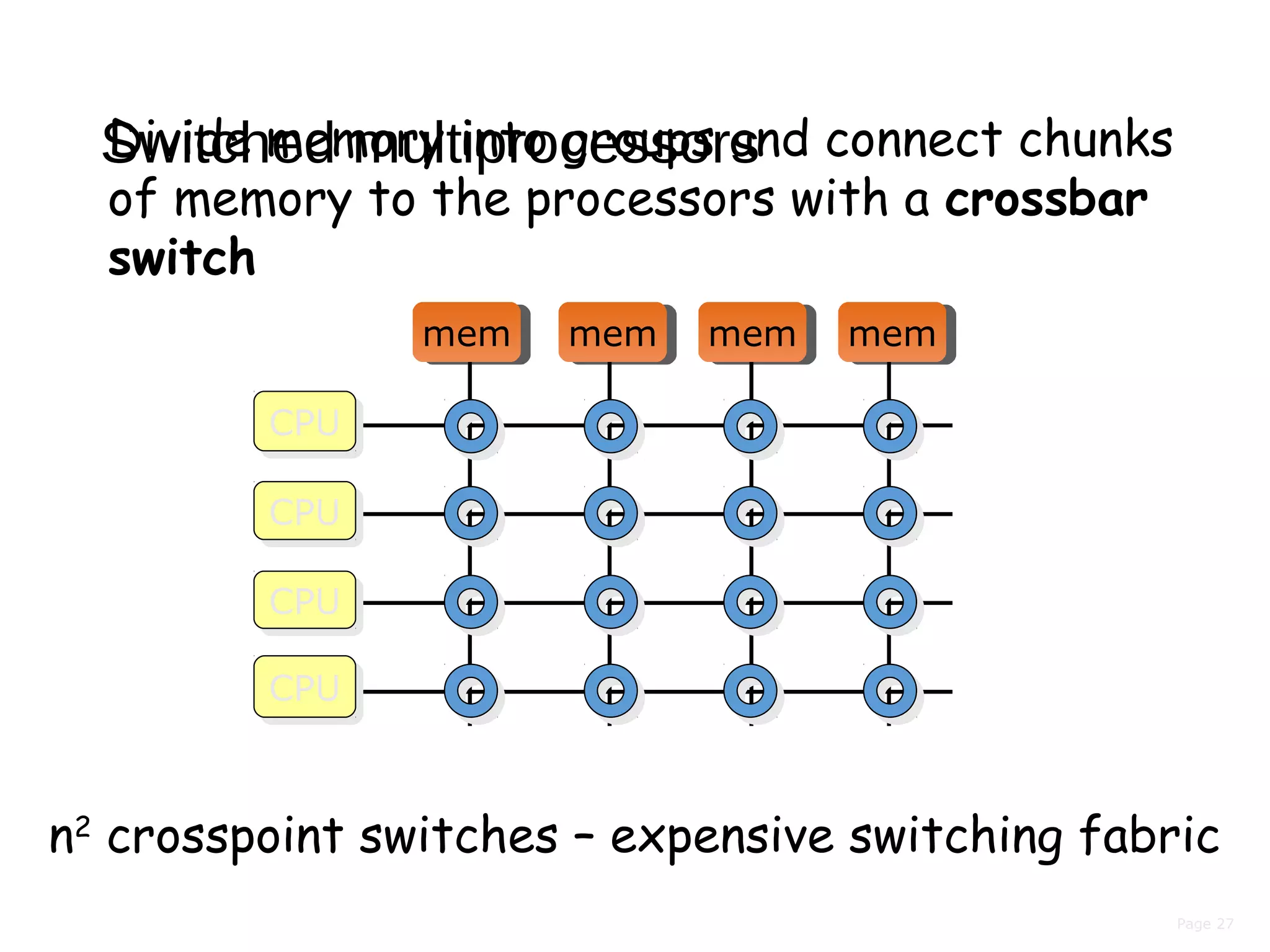
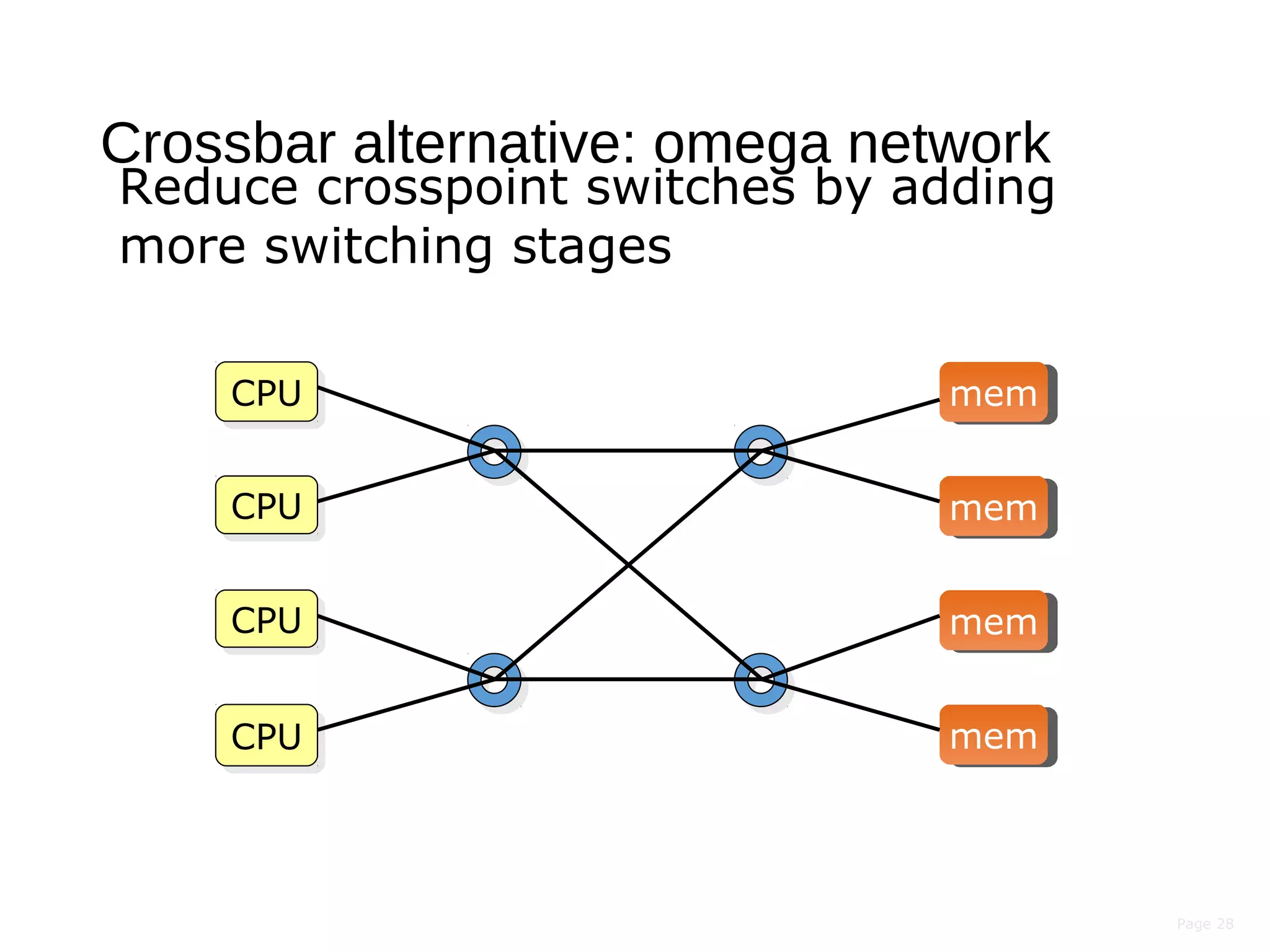




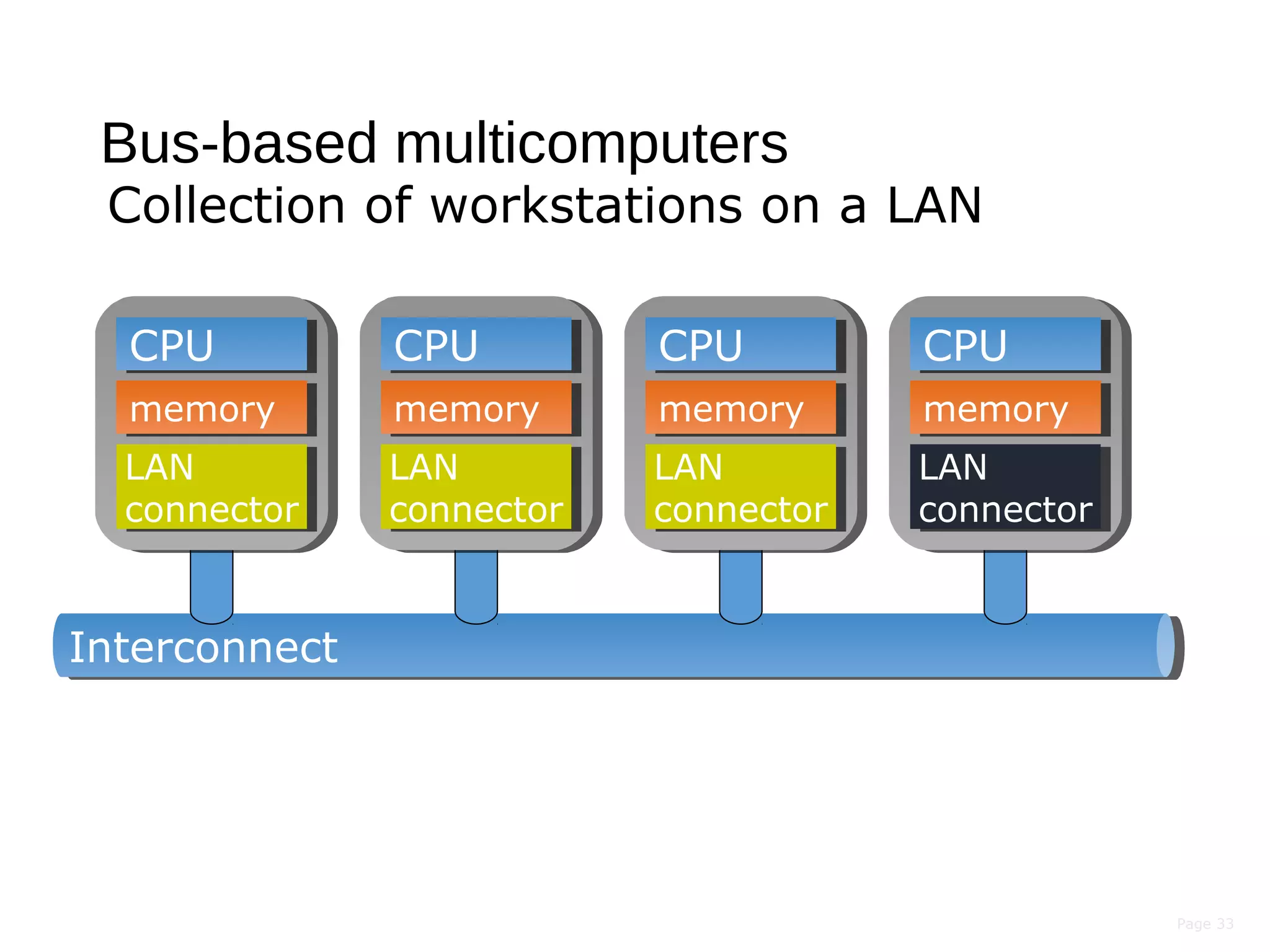
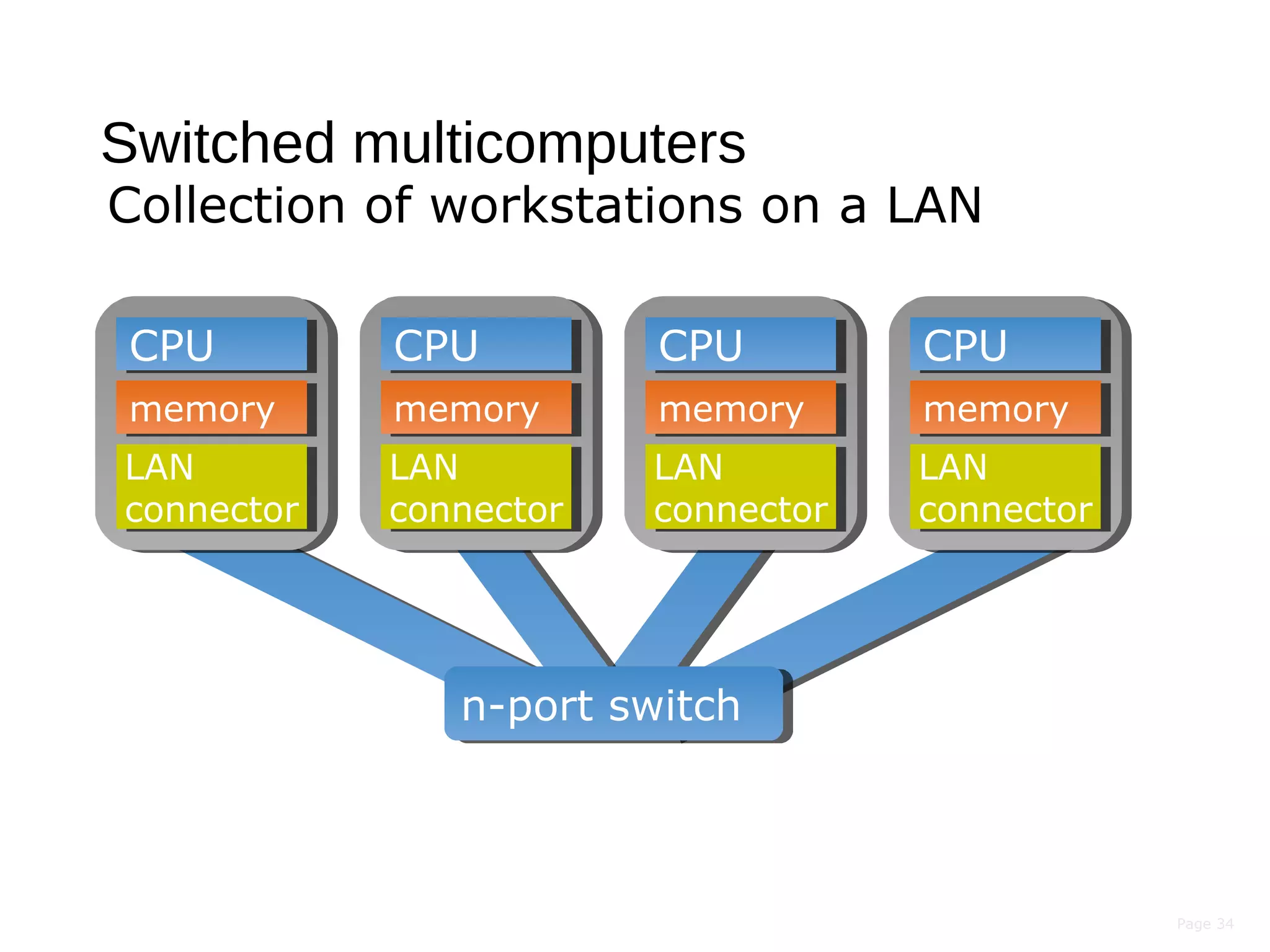







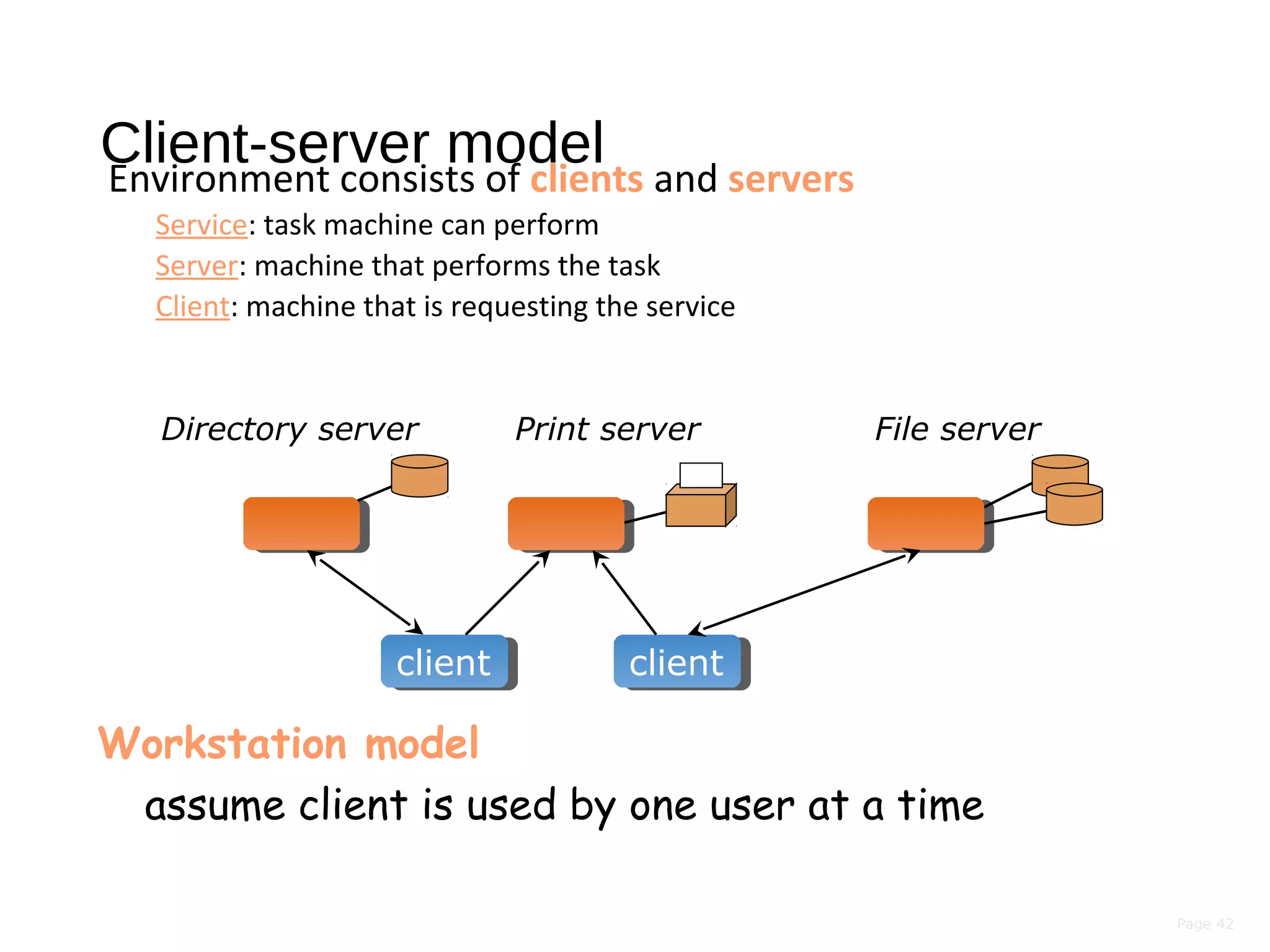





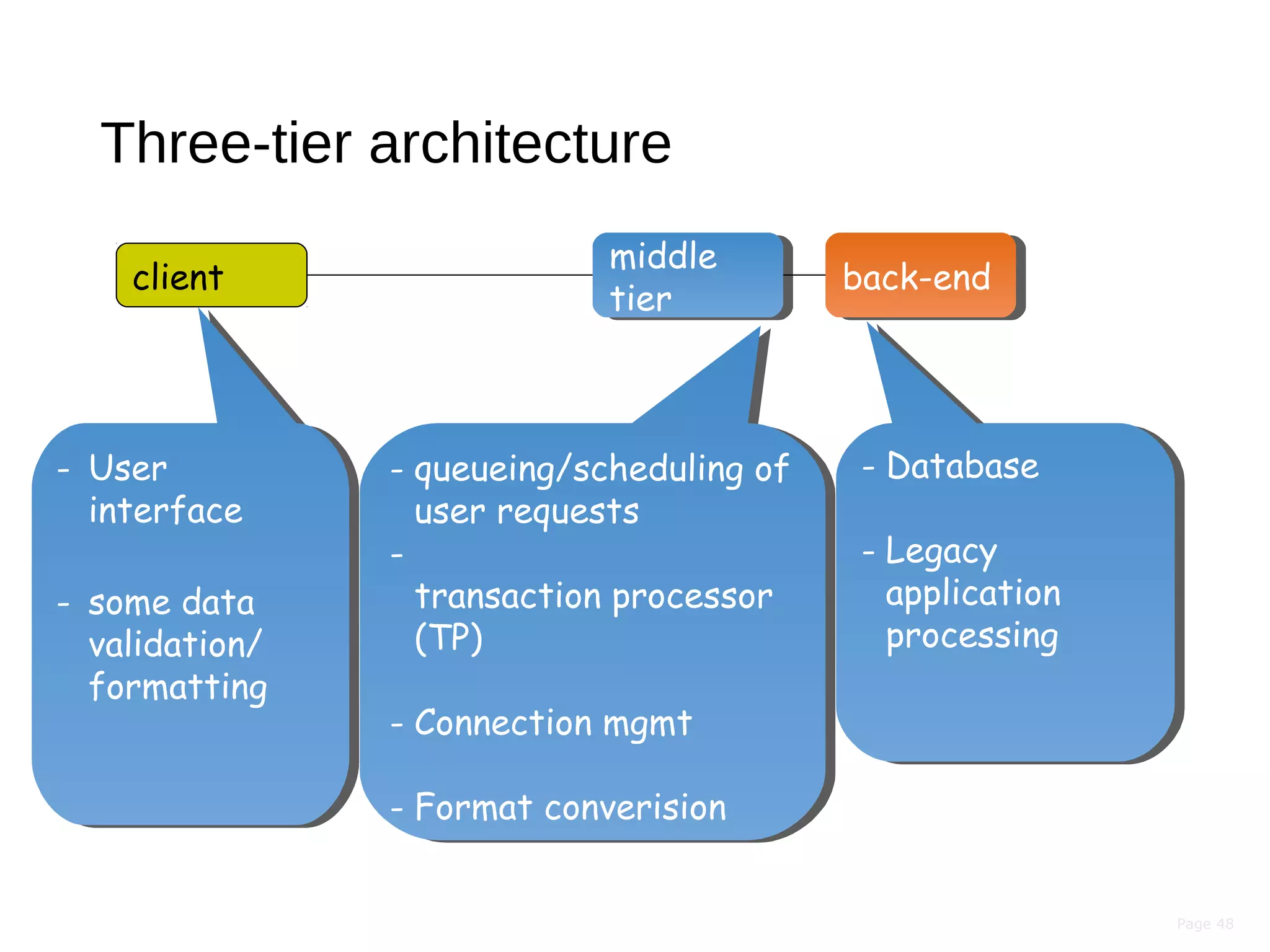
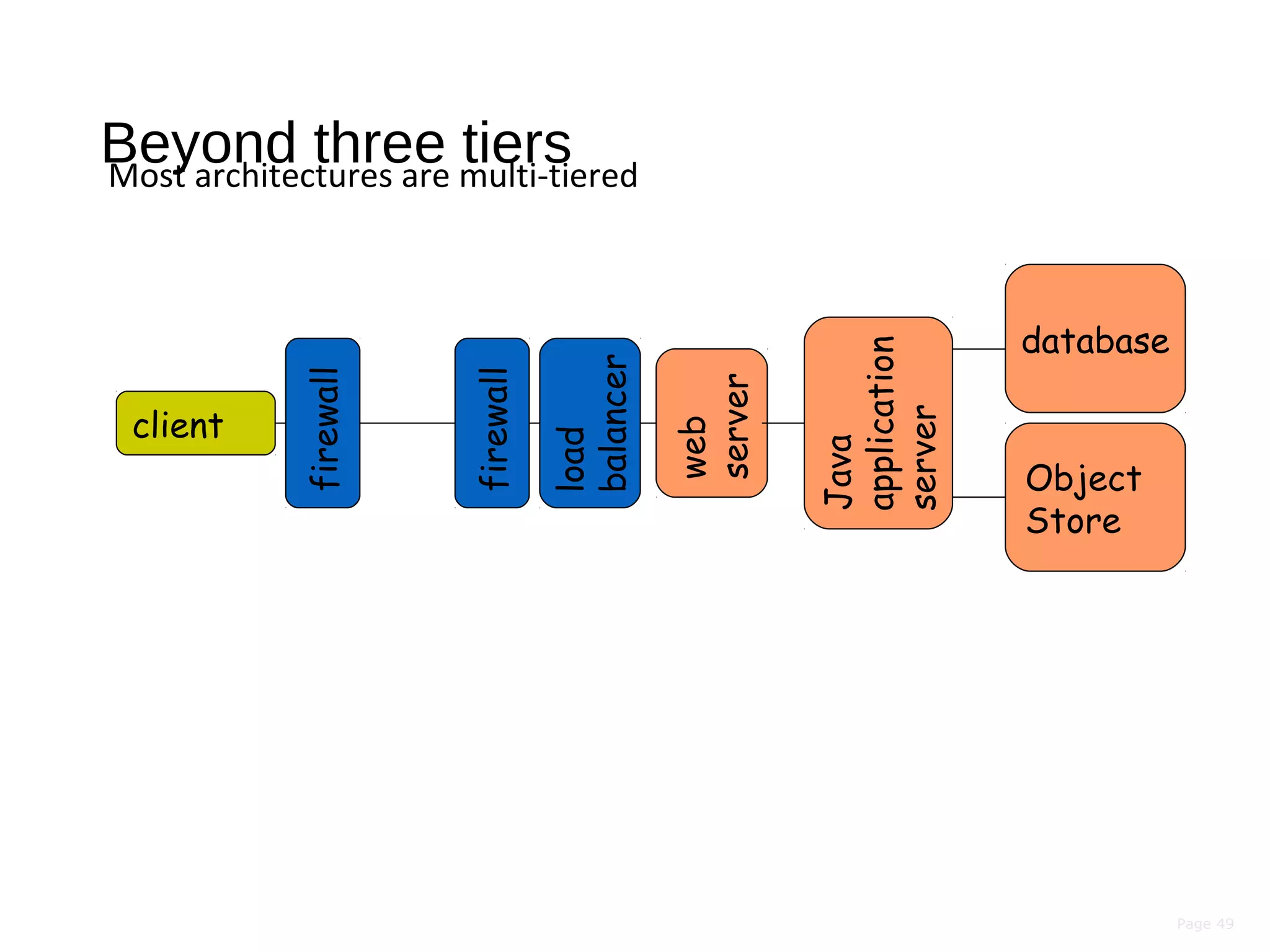


This document discusses the evolution of distributed systems over time. It describes how advances in networking, computing power, storage, and protocols have enabled new capabilities. Specifically, it notes that networking speeds increased 348,000x from 1973 to 2005, storage capacity increased 30,000x and became 131,000x cheaper from 1977 to 2008, and computing power became smaller, cheaper, and faster over time. This allowed distributed systems to become more feasible and widespread.






























































































