The document summarizes lessons learned from building a real-time network traffic analyzer in C/C++. Key points include:
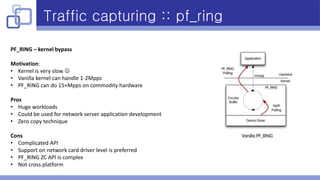
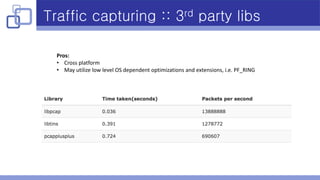
- Libpcap was used for traffic capturing as it is cross-platform, supports PF_RING, and has a relatively easy API.
- SQLite was used for data storage due to its small footprint, fast performance, embeddability, SQL support, and B-tree indexing.
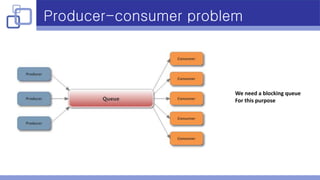
- A producer-consumer model with a blocking queue was implemented to handle packet processing in multiple threads.
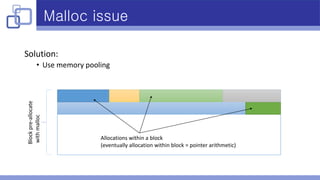
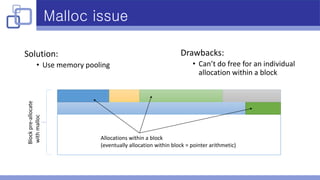
- Memory pooling helped address performance issues caused by excessive malloc calls during packet aggregation.
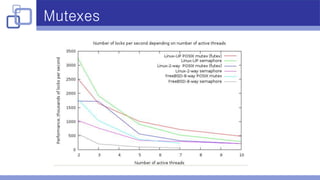
- Custom spin locks based on atomic operations improved performance over mutexes on FreeBSD/