Download as PDF, PPTX





















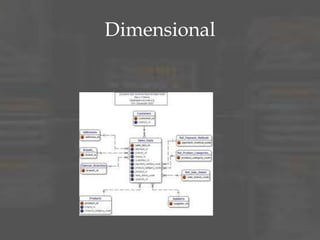














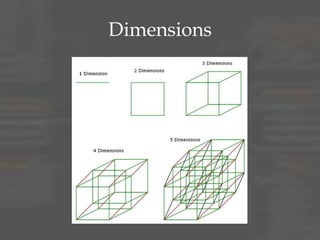
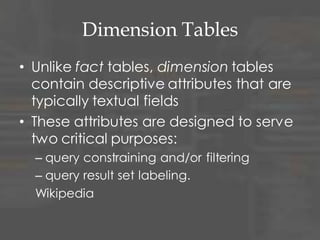

























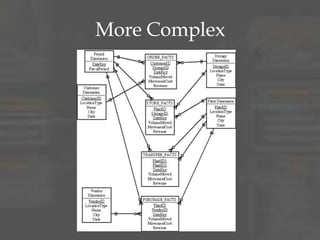



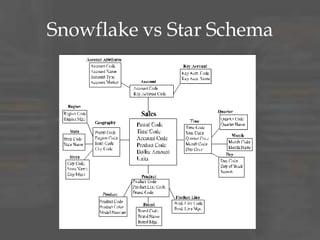



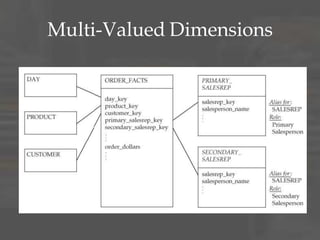
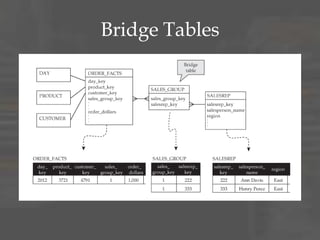




















The document provides an overview of dimensional data modeling. It defines key concepts such as facts, dimensions, and star schemas. It discusses the differences between relational and dimensional modeling and how dimensional modeling organizes data into facts and dimensions. The document also covers more complex dimensional modeling topics such as slowly changing dimensions, bridge tables, and hierarchies. It emphasizes the importance of understanding the data and iterating on the design. Finally, it provides 10 recommendations for dimensional modeling including using surrogate keys and type 2 slowly changing dimensions.








































































































