Download as PDF, PPTX
































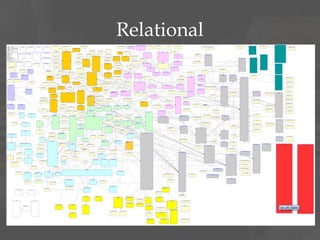


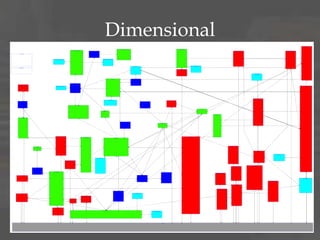





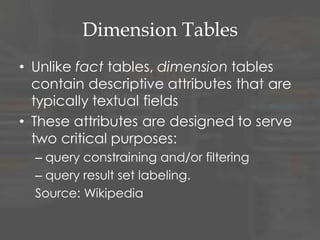











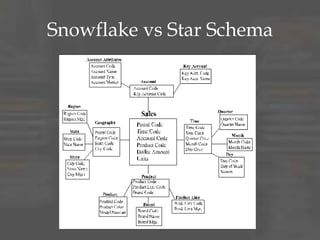



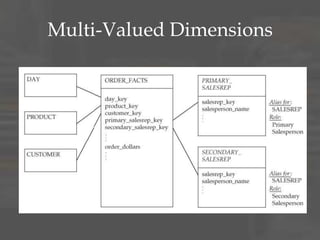
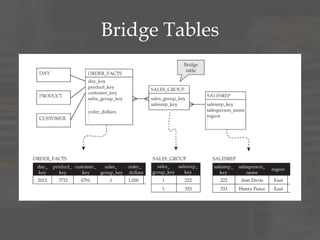













The document discusses dimensional data modeling concepts. It begins with definitions of data modeling and dimensional modeling. It then covers dimensional concepts like facts, dimensions, and star schemas. It discusses challenges like slowly changing dimensions, bridge tables, and recursive hierarchies. It provides advice on how to approach dimensional modeling, including starting simple and iterating as understanding improves. It emphasizes letting the data define the optimal solution rather than rigidly applying patterns. Finally, it suggests data modeling and migration skills will grow in importance as databases are increasingly used for analysis.























































































