Downloaded 43 times



























![Schema Versioning
• A comprehensive approach to versioning is presented in the
multiversion data warehouse [31], they propose two
metamodels: one for managing a multi-version data mart and
one for detecting changes in the operational sources, along
with “real” versions which are versions used in the
application domain, also “alternative” versions are
introduced which are used for simulating and managing
hypothetical business scenarios within what-if analysis
settings
• Commercially, several database management systems
(DBMSs) offer support for valid and transaction time: Oracle
11g, IBM DB2 10 for z/OS, and Teradata Database 14. Part 2
(SQL Foundation) of SQL:2011 was just released](https://image.slidesharecdn.com/presentationfinal-140111074143-phpapp01/85/Survey-On-Temporal-Data-And-Change-Management-in-Data-Warehouses-30-320.jpg)













![Main References
• [22] Felix Naumann & Stefano Rizzi 2013 – Fusion Cubes
• [30] MaSM: Efficient Online Updates in Data Warehouses
http://www.cs.cmu.edu/~chensm/papers/MaSM-sigmod11.pdf
• [37] Managing Late Measurements In Data Warehouses (Matteo
Golfarelli & Stefano Rizzi 2007)
• [38] A SchemaGuide for Accelerating the View Adaptation Process (Jun
Liu1, Mark Roantree1, and Zohra Bellahsene2 2010)
• [35] Temporal Query Processing in Teradata (Mohammed Al-Kateb,
Ahmad Ghazal, Alain Crolotte 2013)
• [33] Toward Propagating the Evolution of Data Warehouse on Data
Marts (Saïd Taktak and Jamel Feki, 2012)
• [31] Wrembel and Bebel (2007)](https://image.slidesharecdn.com/presentationfinal-140111074143-phpapp01/85/Survey-On-Temporal-Data-And-Change-Management-in-Data-Warehouses-49-320.jpg)
![Supporting References
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
[1] Ramakrishnan (DBMS 3rd ed) Chapter 25
[2] http://en.wikipedia.org/wiki/Data_warehouse
[3] Introduction to Information Systems (Marakas & O'Brien 2009)
[4] Kimball, The Data Warehouse Toolkit 2nd Ed (2002) Chapter 1
[5] http://en.wikipedia.org/wiki/Temporal_database
[6] http://www.olapcouncil.org/research/glossaryly.htm
[7] http://en.wikipedia.org/wiki/OLAP_cube
[8] http://docs.oracle.com/cd/B12037_01/olap.101/b10333/multimodel.htm
[9] Multidimensional Database Technology: Bach Pedersen, Torben; S. Jensen, Christian (December 2001).
[10] TSQL2 Language Specification https://cs.arizona.edu/~rts/initiatives/tsql2/finalspec.pdf
[11] Sybase Infocenter
http://infocenter.sybase.com/help/index.jsp?topic=/com.sybase.infocenter.dc00269.1571/doc/html/bde1279401694270.html
[12] (Roddick, 1995)
[13] (Grandi, 2002)
[15] (Devlin, 1997)
[16] "Information technology -- Database languages -- SQL -- Part 2: Foundation (SQL/Foundation)," International Standards Organization,
December 2011
[18] Gupta Maintenance of Materialized Views: Problems, Techniques, and Applications
[20] De Amo & Halfeld Ferrari Alves (2000)
[21] Avoiding re-computation: View adaptation in data warehouses (1997) M Mohania
[23] http://en.wikipedia.org/wiki/Resource_Description_Framework](https://image.slidesharecdn.com/presentationfinal-140111074143-phpapp01/85/Survey-On-Temporal-Data-And-Change-Management-in-Data-Warehouses-50-320.jpg)



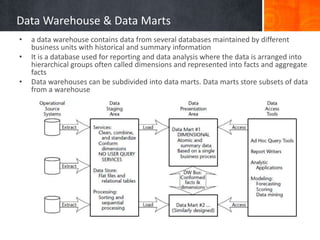
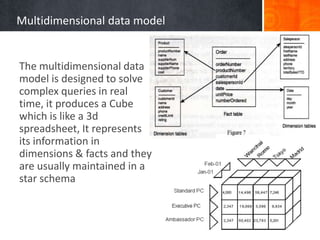
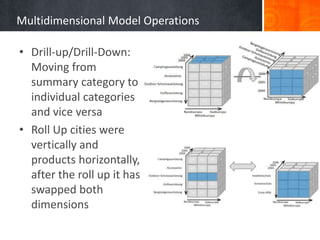
The document provides a comprehensive overview of temporal data management and change handling in data warehouses, focusing on definitions, data models, and methods for adaptation to schema changes. It discusses the evolution and versioning of schemas in data marts, including techniques for online updates and managing late measurements. Additionally, it emphasizes the importance of new methodologies for dynamic features and speed in query processing, suggesting the need for further advancements in commercial systems.



































































