The document details the work of Edgar Barbosa, a security researcher at Coseinc, focusing on hardware virtualization rootkits like Bluepill. It covers the mechanisms by which virtualization rootkits operate, detection methods, and countermeasures to avoid detection. The document also discusses theory versus practice regarding detection and the implications of such rootkits in executing privileged instructions.














![“Undetectable” rootkits
Popek and Goldberg VMM properties:
Efficiency
Resource control
Equivalence
Equivalence “implies that any program executing on a virtual machine must
behave in a manner identical to the way it would have behaved when
running directly on the native hardware” [1]
SVM/VT-x rootkits are only theoreticaly ‘undetectable’
However, the equivalence principle is not fully respected in the hardware
virtualization extensions
There are computer resources that hypervisor has not full control:
TLB (partially)
Branch prediction
SMP processing](https://image.slidesharecdn.com/detectingvirtualizedhardwarerootkits-ppt-130530023406-phpapp01/85/Detecting-hardware-virtualization-rootkits-15-320.jpg)




![TLB
The idea of using TLB to detect hypervisor was first published
by Peter Ferrie [2]. However, in the second version of his paper
[3], Ferrie states that the TLB method does not work on AMD-
based hypervisors because they can direct the hardware to not
flush the TLB when a hypervisor event occurs.
Ferrie suggests the CPUID instruction to be used in the TLB
method. But Bluepill doesn’t need to intercept cpuid
instruction. Another instruction could be used instead, the
rdmsr EFER, which bluepill must intercept.
It is still possible to use the TLB method to detect bluepill even
if the hypervisor controls TLB flush! How?](https://image.slidesharecdn.com/detectingvirtualizedhardwarerootkits-ppt-130530023406-phpapp01/85/Detecting-hardware-virtualization-rootkits-20-320.jpg)
![TLB
TLB entries are tagged with ASID (Address Space Identifier) bits to
distinguish different host and/or guest space address.
ASID #00 assigned to VMM and #1..#63 to guests.
TLB_CONTROL field:
The VMM can control the TLB flush operations by setting the
TLB_CONTROL field on the VMCB. If set to 1, the VMRUN
instruction will flush the entire TLB (all ASID’s).
Even with tagged ASID TLB, we can evict all lines in the TLB. The
number of TLB entries are limited, so it will evict lines if necessary.
Opteron primary TLB has only 40 entries [4].
AMD optimization manual suggests to avoid using the
TLB_CONTROL = 1 to flush the guest TLB. Instead, it is best to
assign a new ASID to the guest!](https://image.slidesharecdn.com/detectingvirtualizedhardwarerootkits-ppt-130530023406-phpapp01/85/Detecting-hardware-virtualization-rootkits-21-320.jpg)
![Branch prediction
Studies have shown that the behavior of branch instruction is
highly predictable [5]
Execution trace history of branch instructions can be used to
predict its future behavior.
If a branch is predicted to be taken and this prediction turns out
to be incorrect, there is a huge performance penalty because all
the pipeline must be flushed.
There are a lot of branch prediction schemes. Explaining these
schemes are out of the scope of this presentation.
There are some very good references about this subject[5]
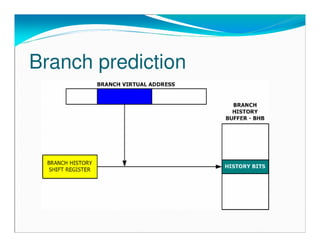
Branch prediction unit uses a small cache to store the history of
the branch instruction execution.](https://image.slidesharecdn.com/detectingvirtualizedhardwarerootkits-ppt-130530023406-phpapp01/85/Detecting-hardware-virtualization-rootkits-22-320.jpg)

![Branch prediction
The Branch Prediction Unit was successfully used to obtain a
512-bit encryption key by using a Branch Prediction Analysis
(BPA) attack[6]. This attack is based in some interesting
features of BPU:
The execution history cache is accessed using just a few low-
order bits from the branch instruction address. Two different
address can use the same history. This is called Branch Aliasing
or Branch Interference.
The cache is shared between all threads.
The spy thread was running simultaneously with the decryption
thread. Since the two threads was using the same branch
prediction cache (branch aliasing), the spy thread can
determine which branches the decryption thread has taken.](https://image.slidesharecdn.com/detectingvirtualizedhardwarerootkits-ppt-130530023406-phpapp01/85/Detecting-hardware-virtualization-rootkits-24-320.jpg)
![Branch prediction
It is not possible to use Branch Aliasing effect to detect
virtualization rootkits due to the fact that we do not know the
virtual address where the rootkit code is being executed.
To use our detection method we must know internal details of
the implementation of the branch prediction unit. However, this
information is not easy to find in the cpu manuals.
We can use some very clever benchmarks developed by Milena
Milenkovic, Aleksandar Milenkovic and Jeffrey Kulick [7].
These benchmarks give us very specific details of the BPU,
like the number of entries and associativiy of BTB, the bits
used from the branch address that are used as the set index and
the local branch history length.](https://image.slidesharecdn.com/detectingvirtualizedhardwarerootkits-ppt-130530023406-phpapp01/85/Detecting-hardware-virtualization-rootkits-26-320.jpg)







![BP in hibernation-mode
One interesting idea discussed is the possibility of bluepill
being able to unload itself while some attack is being executed
and reload itself after the finish of the attack.[8]
That’s a weird idea because if we know that the rootkit is
unloaded, we can load our own detector hypervisor and waits
for any code trying to get access to SVM resources! Remember
bluepill is predicted to be undetectable even if the source is
published.
However, the unload idea can be cleverly used against the next
detection idea. It is interesting to present this attack to know
how virtualization rootkits can use this ‘unload’ trick.](https://image.slidesharecdn.com/detectingvirtualizedhardwarerootkits-ppt-130530023406-phpapp01/85/Detecting-hardware-virtualization-rootkits-34-320.jpg)









![References
[1] J. Smith and R. Nair. Virtual Machines. Versatile platforms for systems and processes. Morgan Kaufmann, 2005.
[2]http://pferrie.tripod.com/papers/attacks.pdf
[3]http://pferrie.tripod.com/papers/attacks2.pdf
[4]http://www.chip-architect.com/news/2003_09_21_Detailed_Architecture_of_AMDs_64bit_Core.html
[5]J. Shen and M. Lipasti. Modern Processor Design. Fundamentals of Superscalar processors. McGraw-Hill , 2005.
[6]O. Acuçmez, Ç. Koç and J. Seifert. On the power of simple branch prediction analysis. http://eprint.iacr.org/2006/351.pdf
[7] M. Milenkovic, A. Milenkovic and J. Kulick. Demystifying Intel Branch Predictors.
http://www.ece.wisc.edu/~wddd/2002/final/milenkovic.pdf
[8]http://blogs.zdnet.com/Ou/?p=297](https://image.slidesharecdn.com/detectingvirtualizedhardwarerootkits-ppt-130530023406-phpapp01/85/Detecting-hardware-virtualization-rootkits-44-320.jpg)








































![[Defcon] Hardware backdooring is practical](https://cdn.slidesharecdn.com/ss_thumbnails/slidesdefcon2012brossard-120729030359-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















![he-dieu-hanh_david-mazieres_l18-virtual-machines - [cuuduongthancong.com].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/he-dieu-hanhdavid-mazieresl18-virtual-machines-cuuduongthancong-230504152824-d5e49a1c-thumbnail.jpg?width=640&height=640&fit=bounds)























