Download as PDF, PPTX

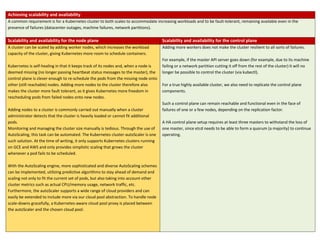
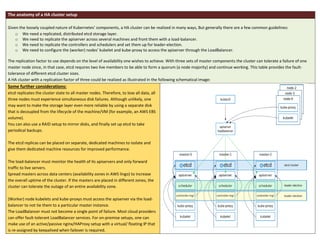


The document discusses setting up a highly available (HA) Kubernetes cluster. It describes the master-worker architecture of Kubernetes and explains that to achieve high availability, both the control plane (master components) and node plane need replication. It provides details on replicating the etcd database, API server, and controller/scheduler components across multiple machines. It also discusses considerations for load balancing the API server and placing components across availability zones. While a HA cluster improves fault tolerance, it involves more complexity, so the document discusses when a single master may suffice and factors to consider in that decision.



































































