Download as PDF, PPTX

















































![52
-XX:CompileCommand=
§ Syntax
– “[command] [method] [signature]”
§ Supported commands
– exclude – never compile
– inline – always inline
– dontinline – never inline
§ Method reference
– class.name::methodName
§ Method signature is optional](https://image.slidesharecdn.com/jitjeeconf20134x3-130603165706-phpapp01/75/JIT-compiler-overview-JEEConf-2013-Kiev-Ukraine-52-2048.jpg)




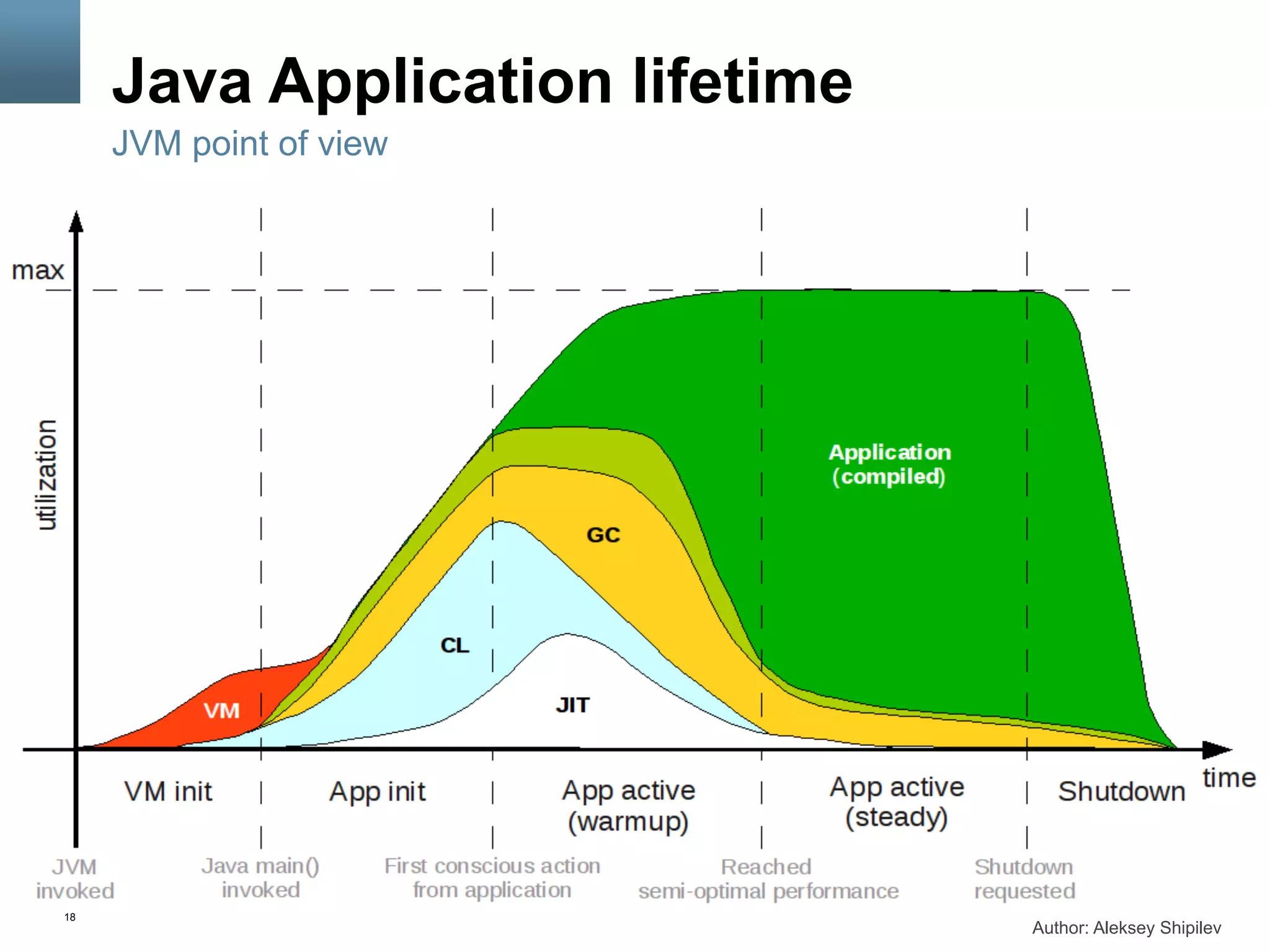
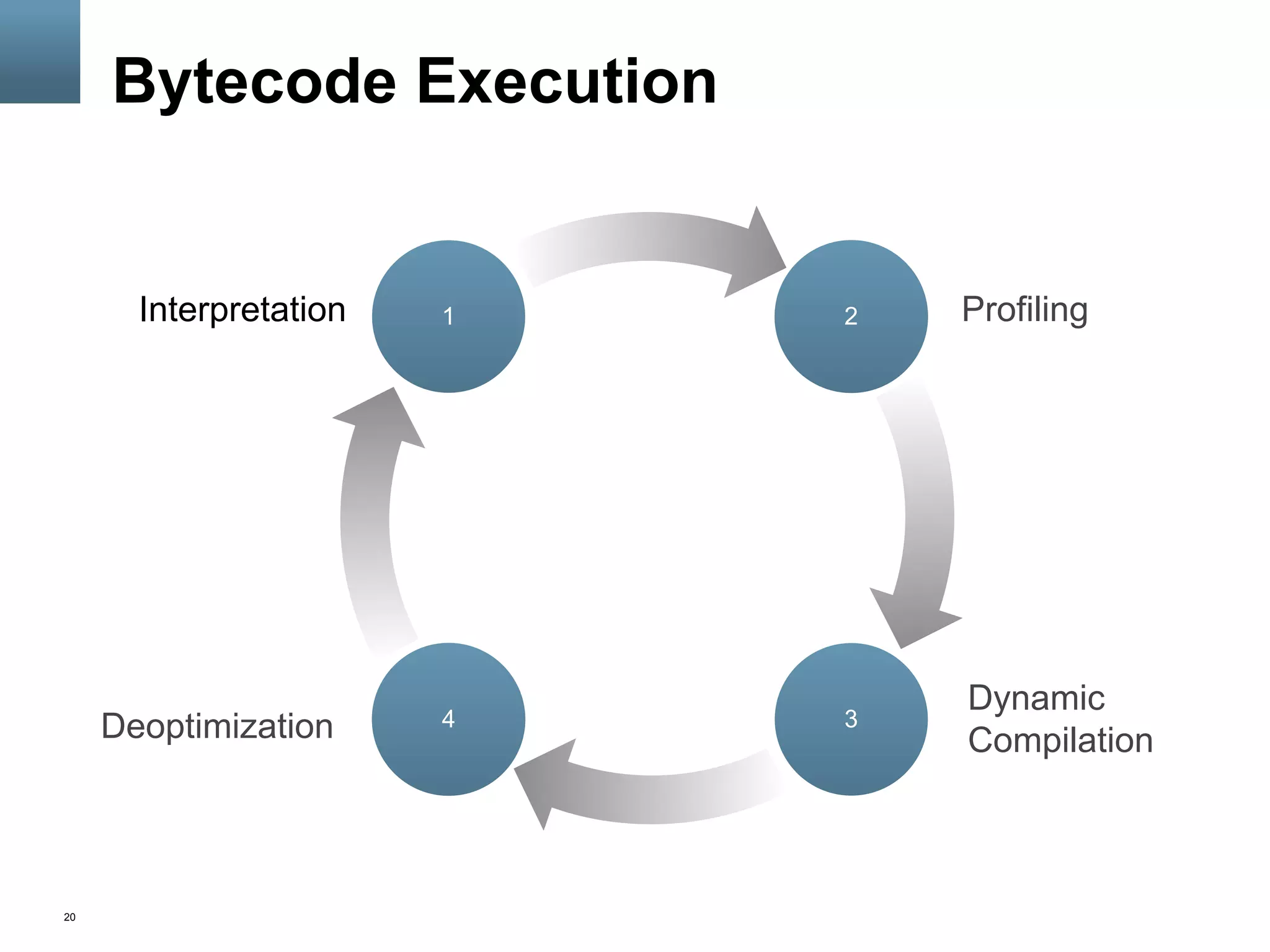
This document provides an overview of JVM JIT compilers, specifically focusing on the HotSpot JVM compiler. It discusses the differences between static and dynamic compilation, how just-in-time compilation works in the JVM, profiling and optimizations performed by JIT compilers like inlining and devirtualization, and how to monitor the JIT compiler through options like -XX:+PrintCompilation and -XX:+PrintInlining.











































































