Downloaded 19 times





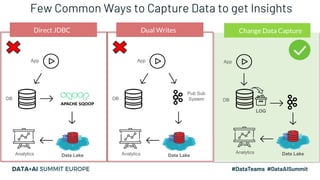

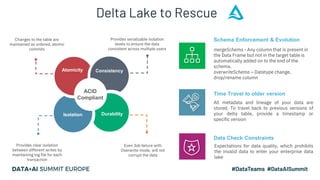

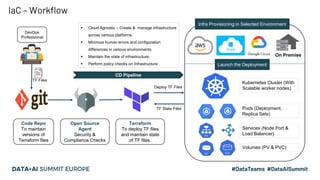




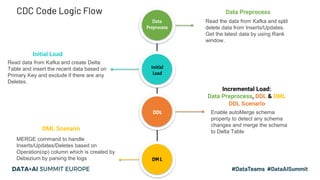




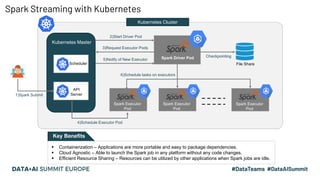

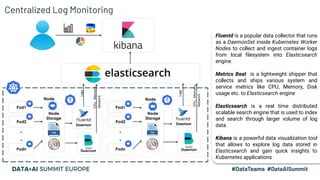
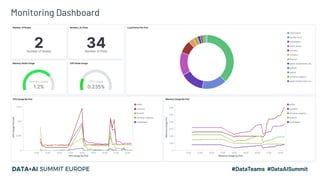






This document discusses the design and implementation of a containerized stream engine using Delta Lake for real-time data processing and operational analytics. It highlights the importance of change data capture (CDC) for creating a single source of truth, outlines infrastructure provisioning with Terraform, and delves into data handling practices including schema management and merge strategies in Delta Lake. Additionally, it touches on monitoring tools and considerations for ensuring data integrity and performance in a cloud-agnostic environment.























































































