Downloaded 14 times



![©2022 Databricks Inc. — All rights reserved
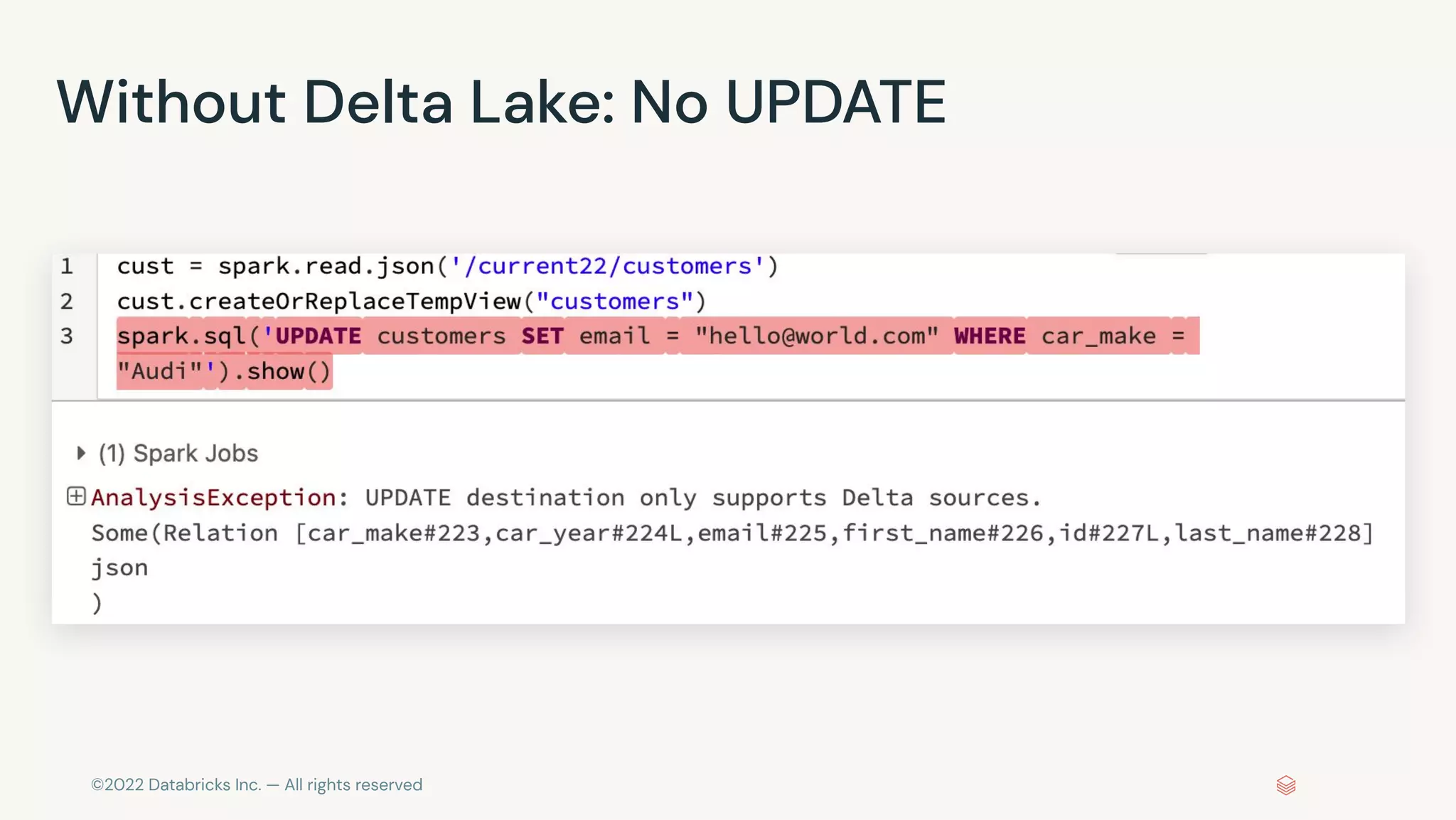
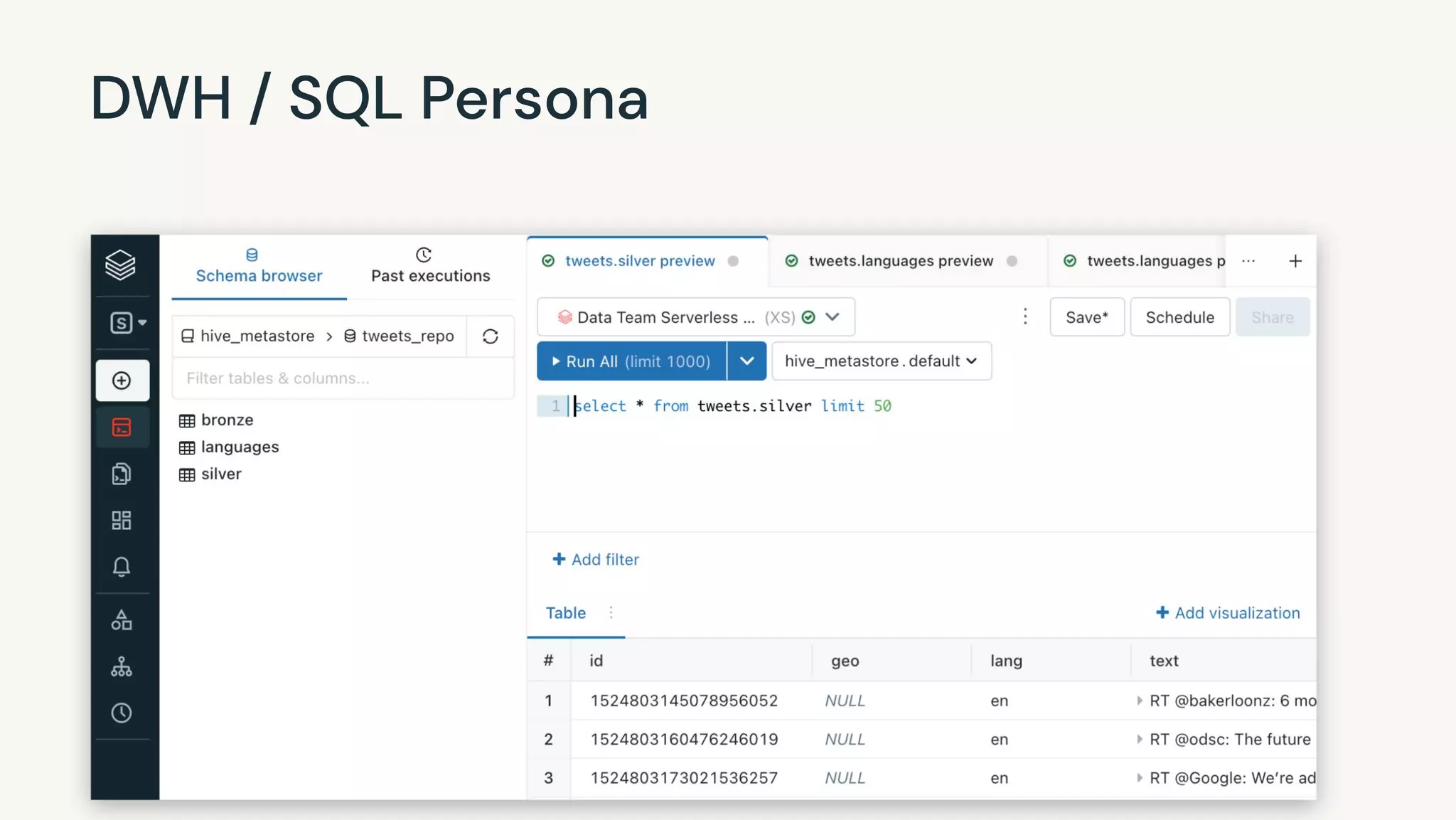
Spark SQL and Dataframe API
# PYTHON: read multiple JSON files with multiple datasets per file
cust = spark.read.json('/data/customers/')
cust.createOrReplaceTempView("customers")
cust.filter(cust['car_make']== "Audi").show()
%sql
select * from customers where car_make = "Audi"
-- PYTHON:
-- spark.sql('select * from customers where car_make ="Audi"').show()](https://image.slidesharecdn.com/frankmunzbr03010-221021201205-b2a4980d/75/Streaming-Data-Into-Your-Lakehouse-With-Frank-Munz-Current-2022-4-2048.jpg)


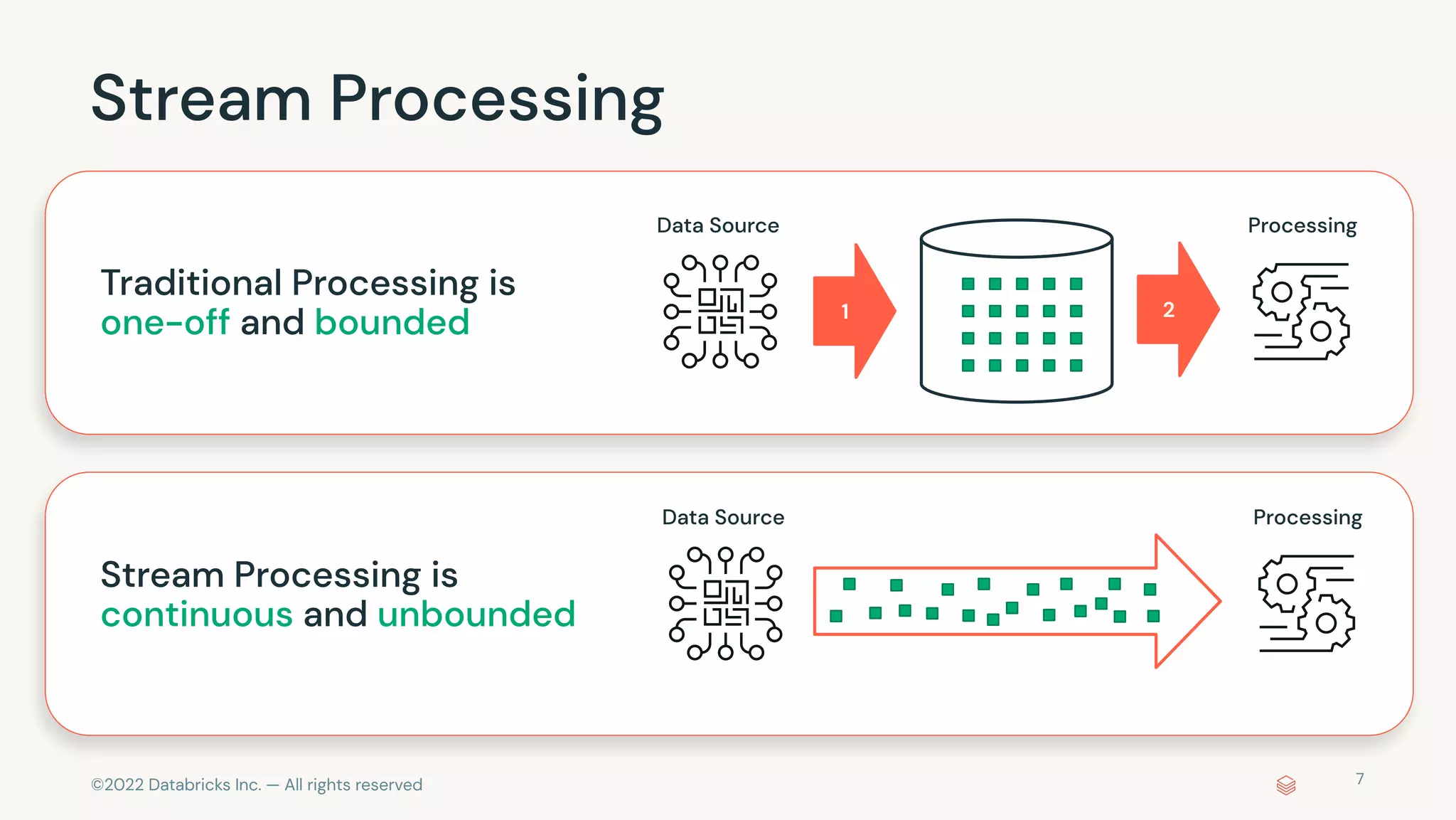

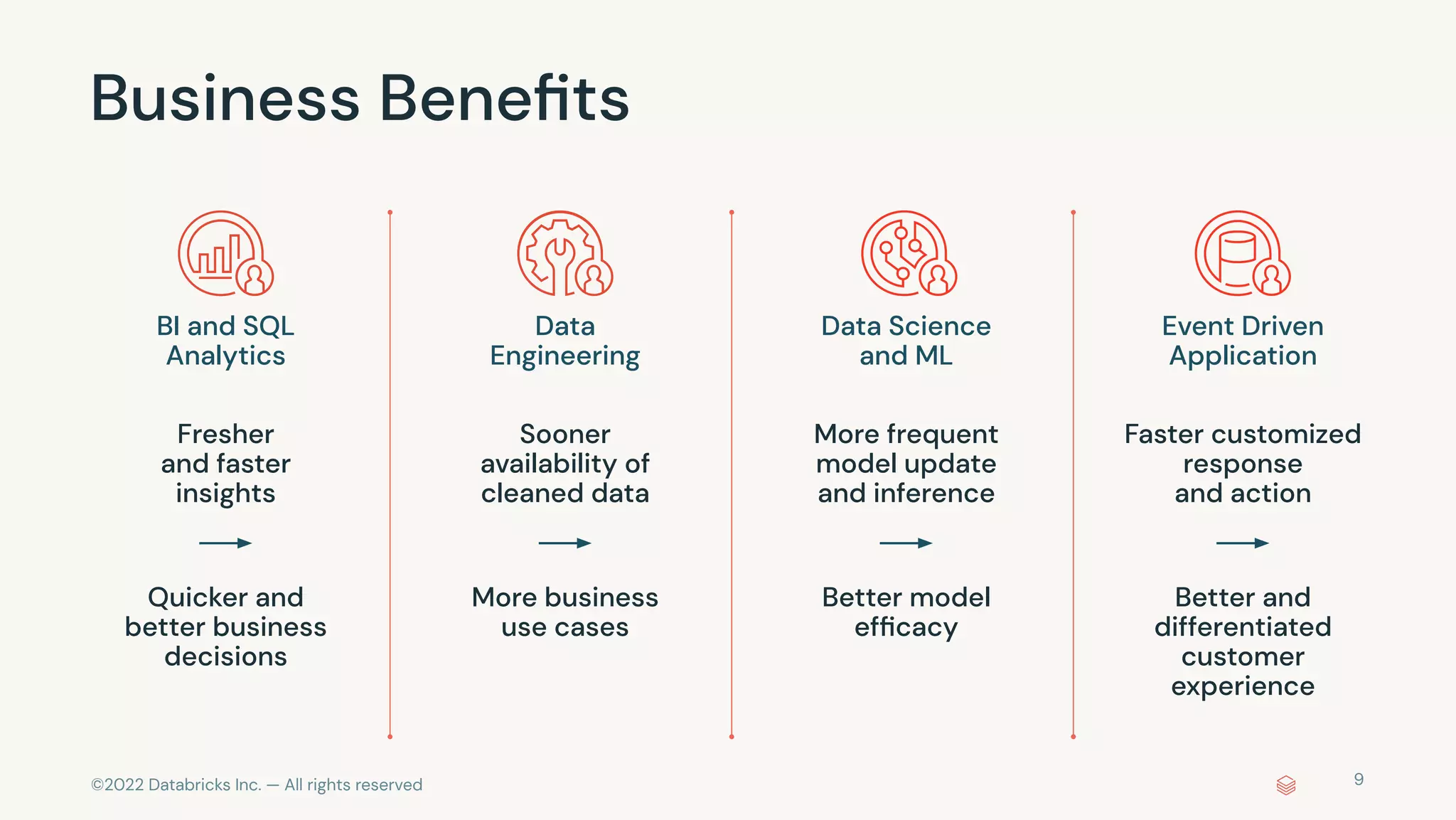


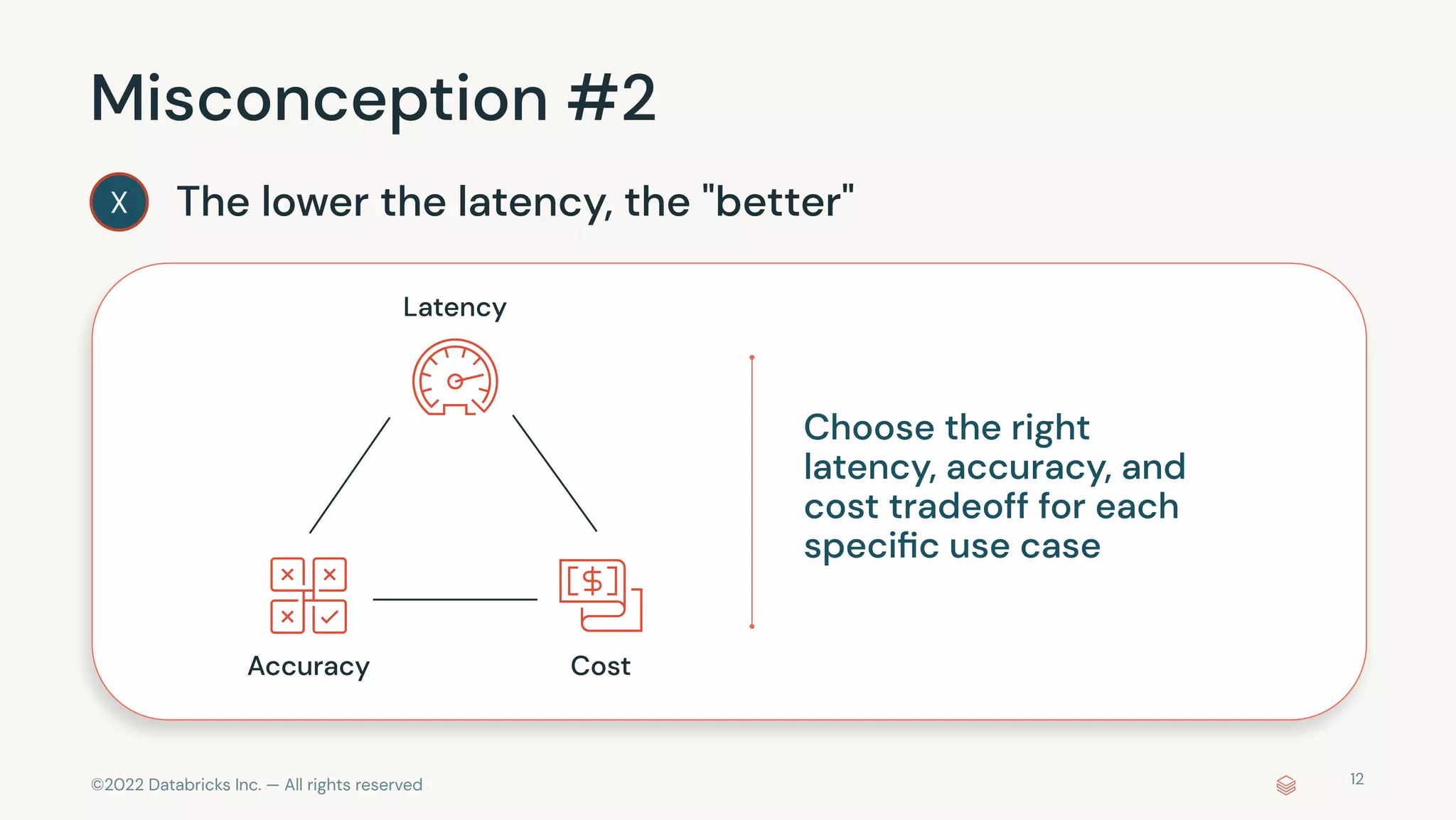



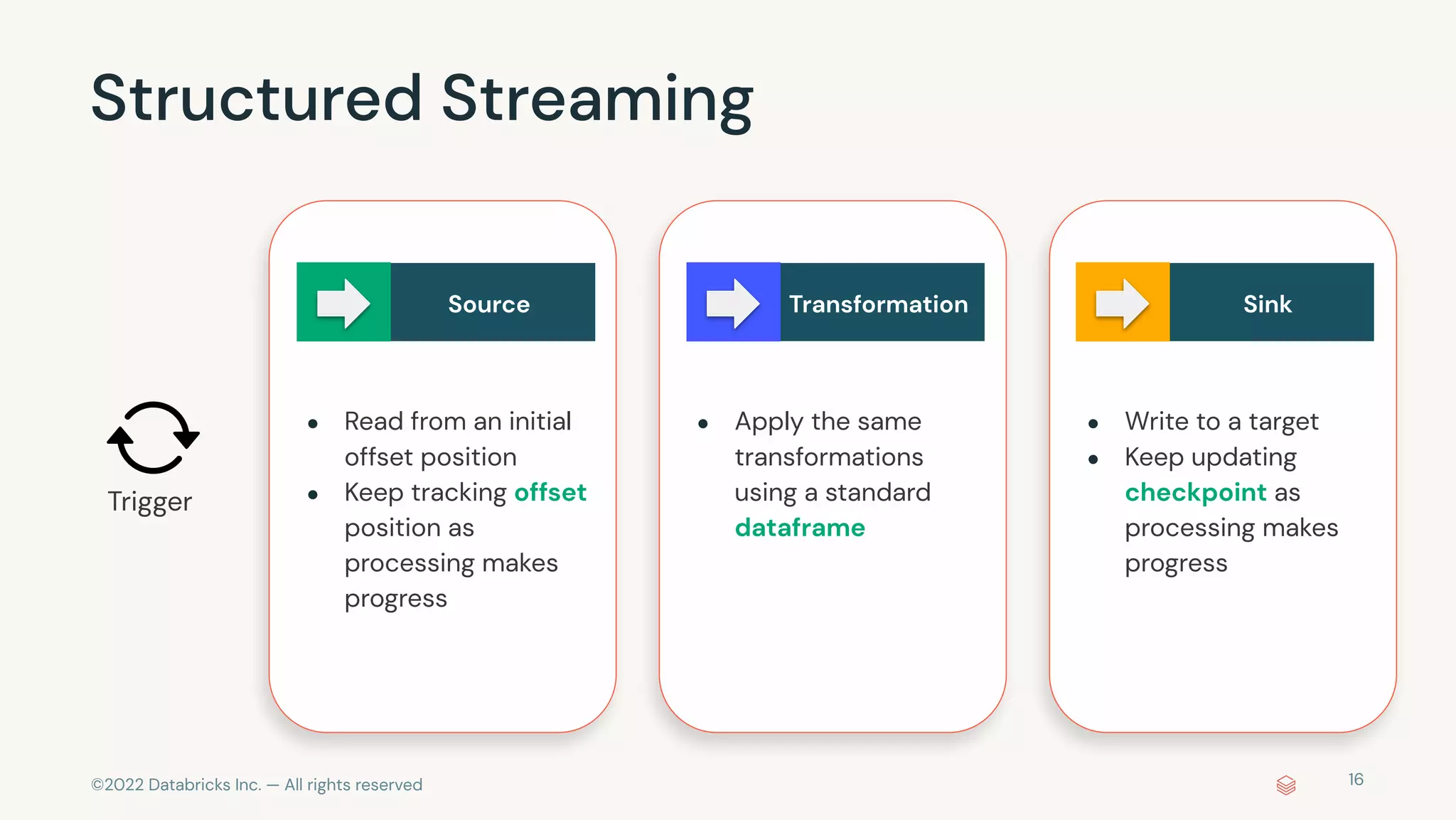



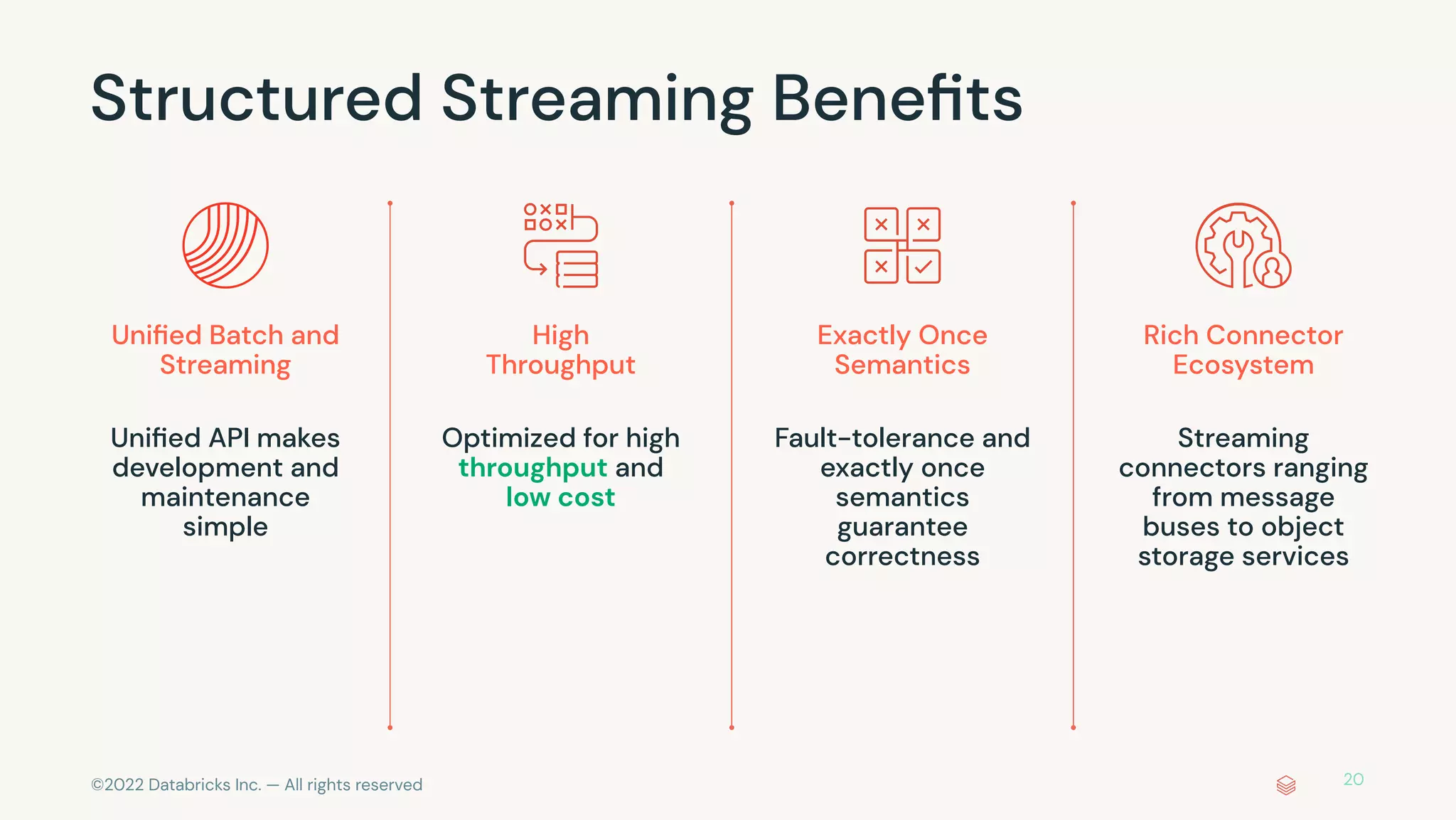

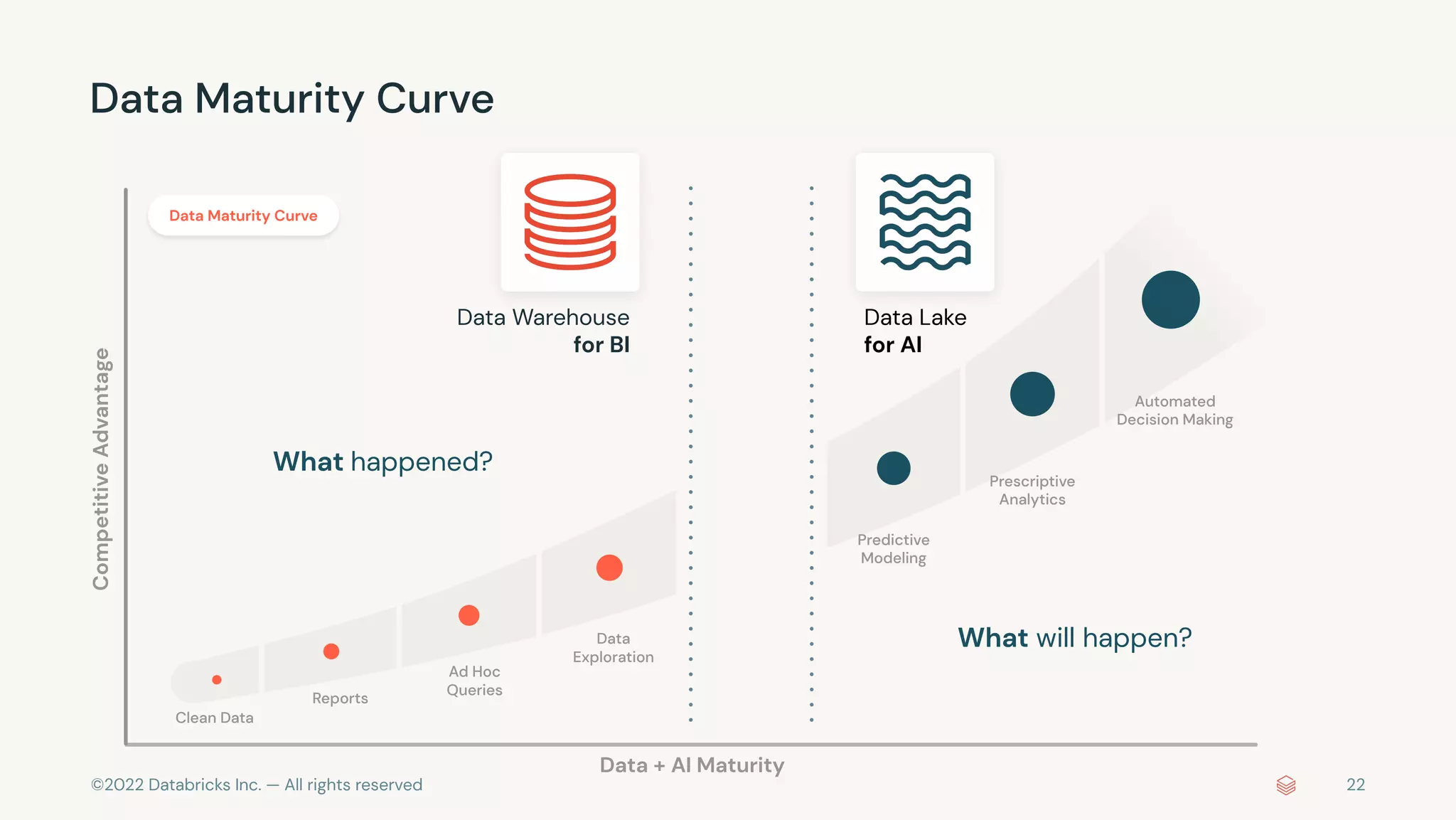
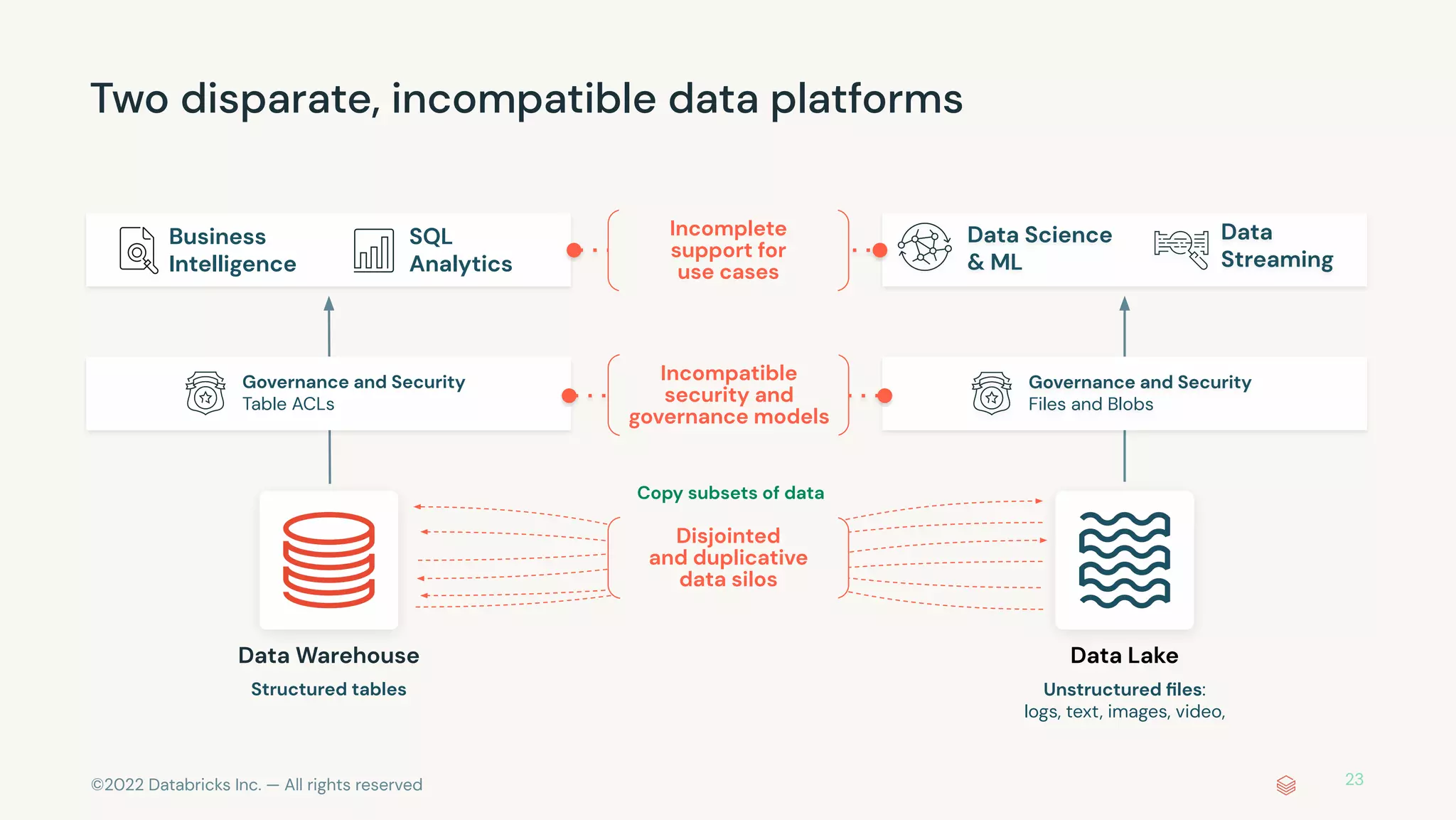

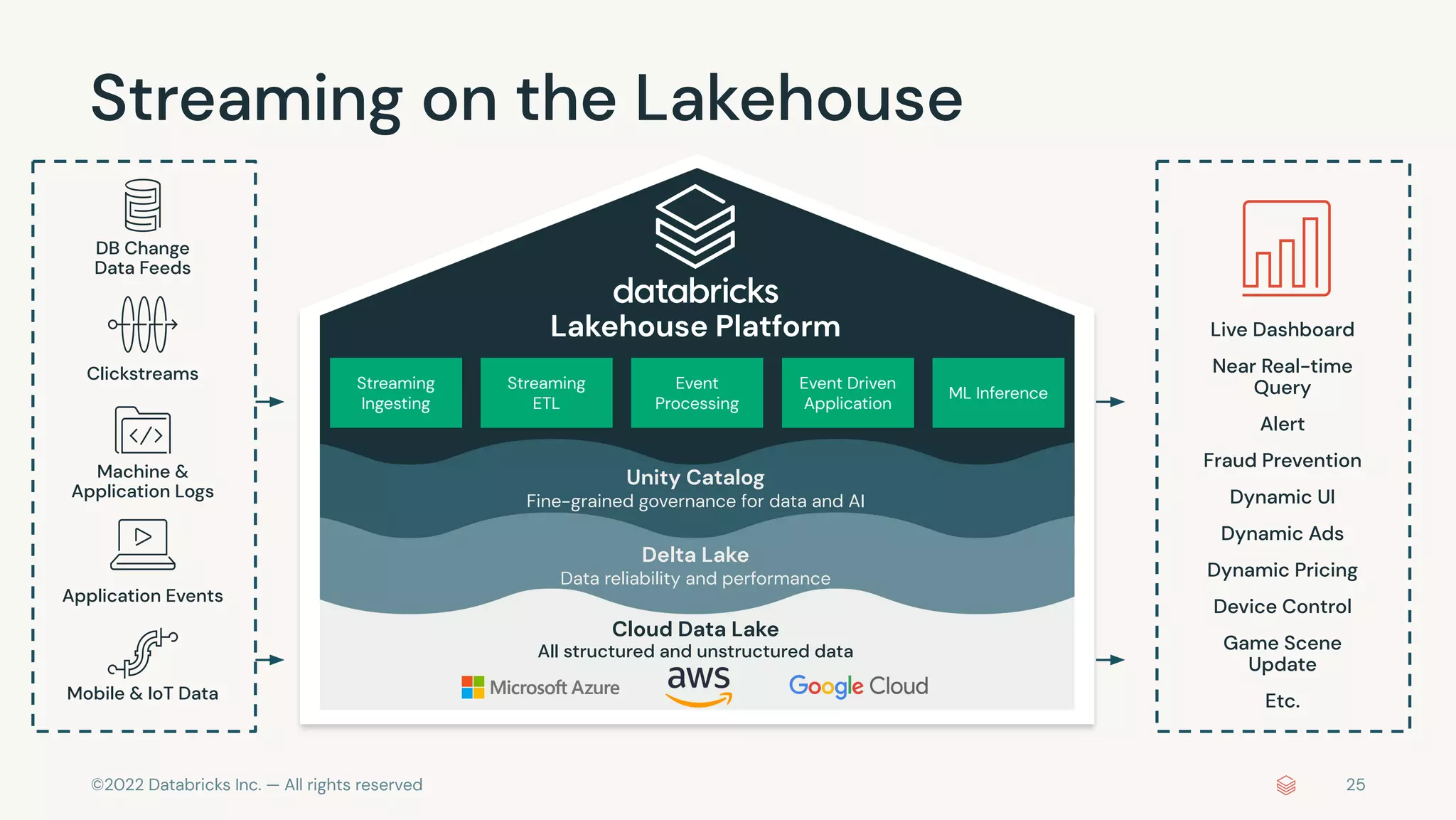
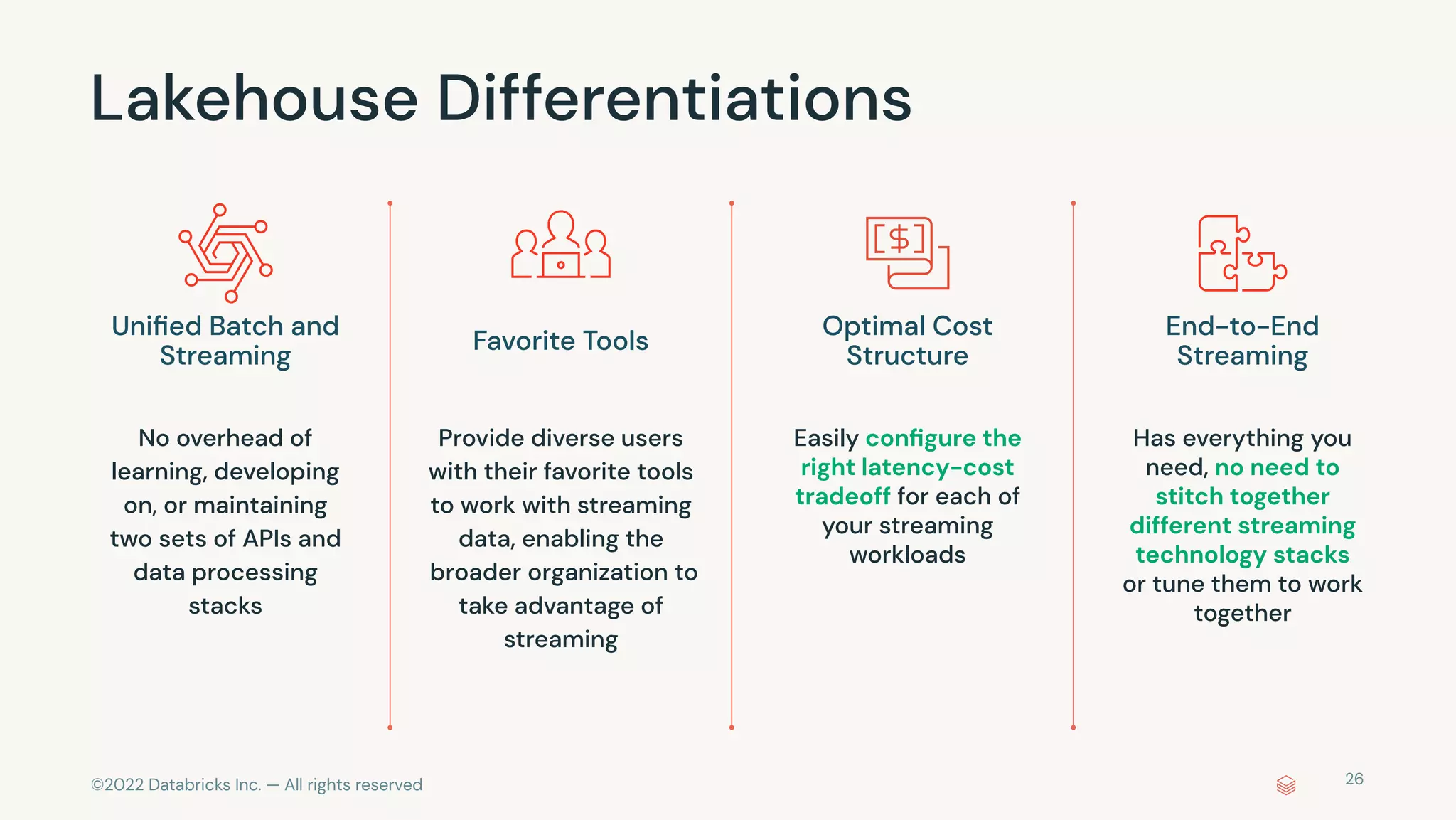



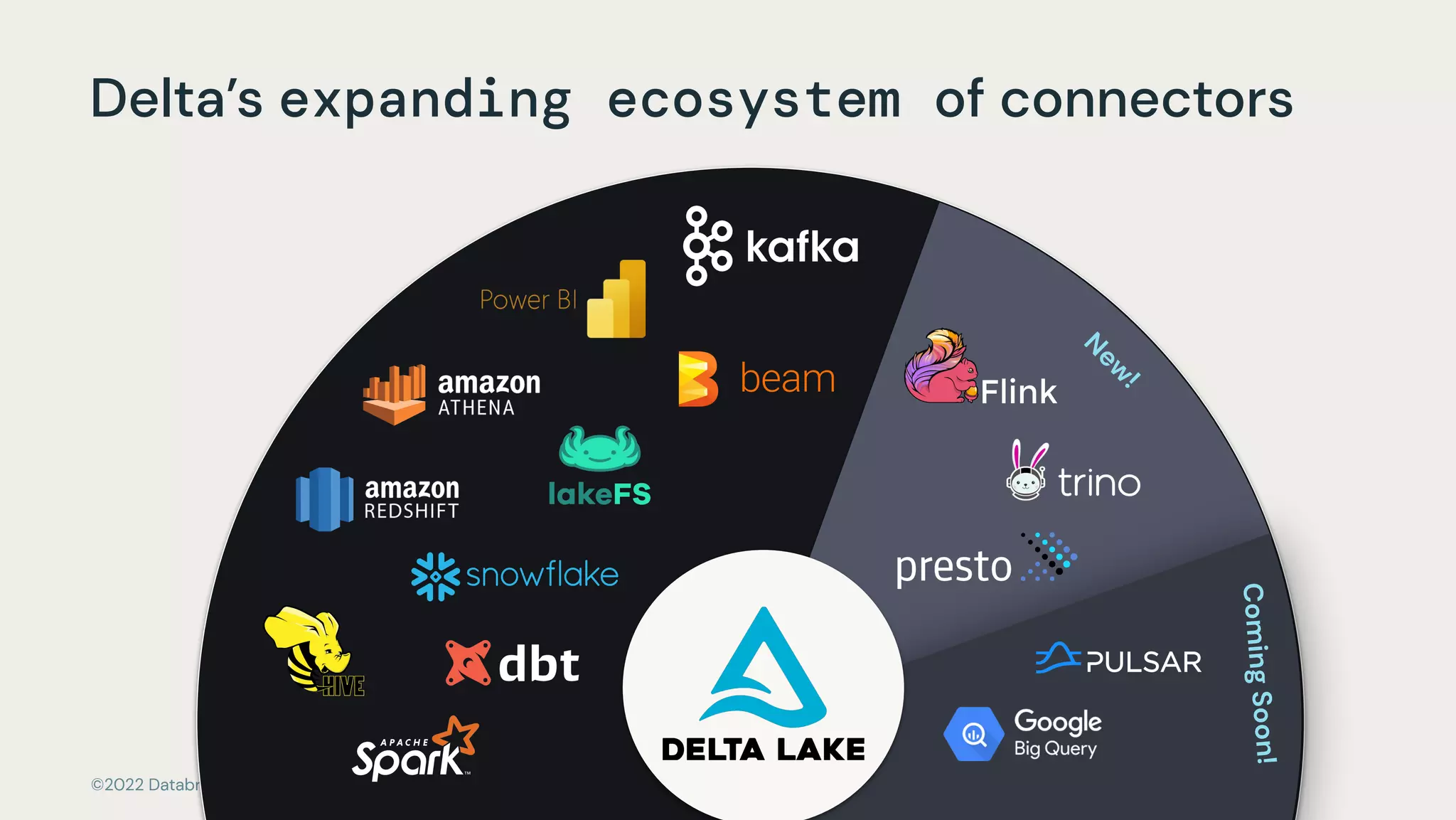






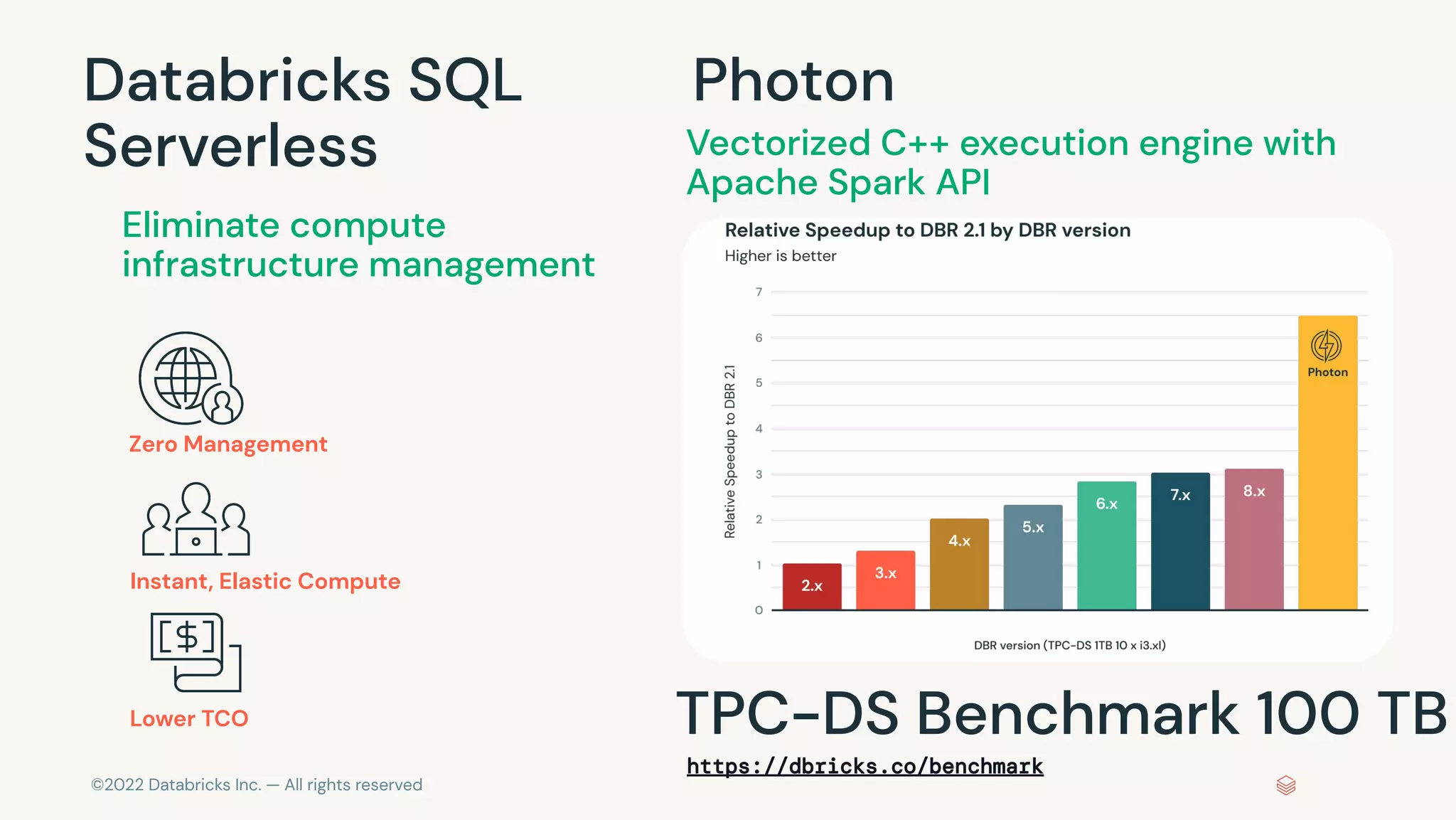













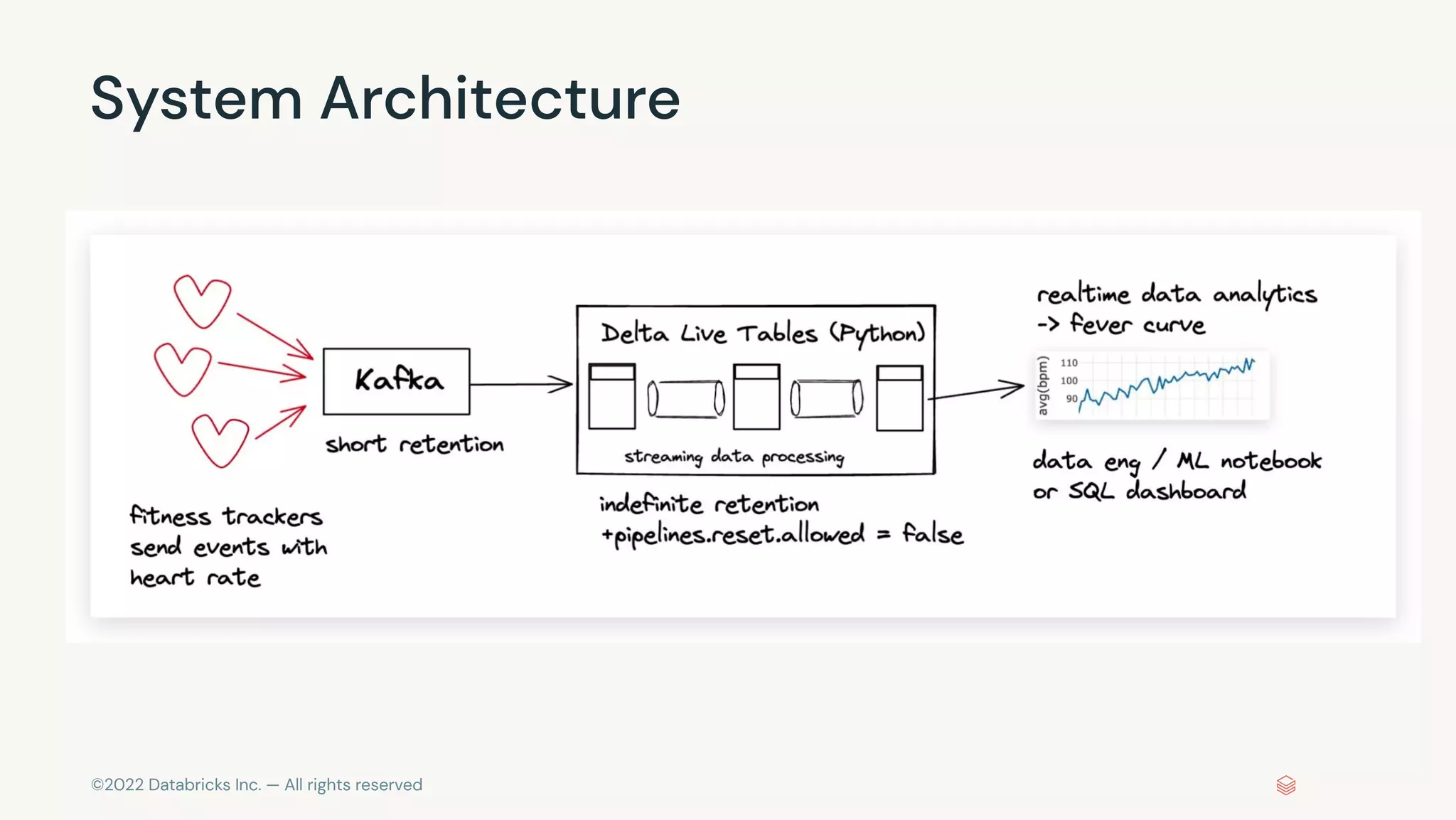





The document discusses the advantages and methods of streaming data processing within Databricks' Lakehouse Platform, emphasizing its integration of structured and unstructured data for efficient data management and analytics. It highlights the capabilities of Apache Spark for continuous and incremental data processing, while addressing common misconceptions about streaming's latency and cost. Additionally, it outlines the Delta Lake's role in providing reliability, performance, and a unified API for both batch and streaming operations.



































































