Download as PDF, PPTX

![References
1. [Sukhbaatar, 2015] Sukhbaatar, Szlam, Weston, Fergus. “End-To-End Memory Networks” Advances in
Neural Information Processing Systems. 2015.
2. [Hill, 2015] Hill, Bordes, Chopra, Weston. “The Goldilocks Principle: Reading Children's Books with Explicit
Memory Representations” arXiv preprint arXiv:1511.02301 (2015).
3. [Kumar, 2015] Kumar, Irsoy, Ondruska, Iyyer, Bradbury, Gulrajani, Zhong, Paulus, Socher. “Ask Me
Anything: Dynamic Memory Networks for Natural Language Processing” arXiv preprint
arXiv:1511.06038 (2015).
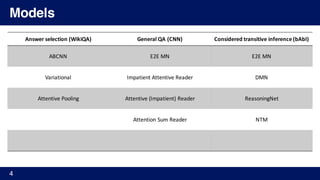
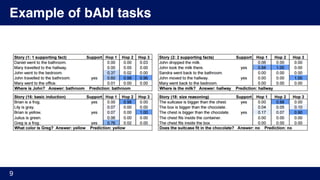
4. [Xiong, 2016] Xiong, Merity, Socher. “Dynamic Memory Networks for Visual and Textual Question
Answering” arXiv preprint arXiv:1603.01417 (2016).
5. [Yin, 2015] Yin, Schütze, Xiang, Zhou. “ABCNN: Attention-Based Convolutional Neural Network for
Modeling Sentence Pairs” arXiv preprint arXiv:1512.05193 (2015).
6. [Yu, 2015] Yu, Zhang, Hang, Xiang, Zhou. “Empirical Study on Deep Learning Models for Question
Answering” arXiv preprint arXiv:1510.07526 (2015).
7. [Hermann, 2015] Hermann, Kočiský, Grefenstette, Espeholt, Will Kay, Suleyman, Blunsom. “Teaching
Machines to Read and Comprehend” arXiv preprint arXiv:1506.03340 (2015).
8. [Kadlec, 2016] Kadlec, Schmid, Bajgar, Kleindienst. “Text Understanding with the Attention Sum Reader
Network” arXiv preprint arXiv:1603.01547 (2016).
2](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-2-320.jpg)
![References
9. [Miao, 2015] Miao, Lei Yu, Blunsom. “Neural Variational Inference for Text Processing” arXiv preprint
arXiv:1511.06038 (2015).
10. [Kingma, 2013] Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes" arXiv preprint
arXiv:1312.6114 (2013).
11. [Sohn, 2015] Sohn, Kihyuk, Honglak Lee, and Xinchen Yan. "Learning Structured Output Representation
using Deep Conditional Generative Models." Advances in Neural Information Processing Systems. 2015.
3](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-3-320.jpg)
![End-to-End Memory Network [Sukhbaatar, 2015]
5](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-5-320.jpg)
![End-to-End Memory Network [Sukhbaatar, 2015]
6
I go to school.
He gets ball.
…
Embed
C
Where does he go?u Embed
B
Embed
A
Attention
o
I
go
to
he
gets
ball
Input Memory
Output Memory
softmax
Inner product
weighted sum
Σ linear](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-6-320.jpg)
![End-to-End Memory Network [Sukhbaatar, 2015]
7
I go to school.
He gets ball.
…
linear
Where does he go?
Σ
Σ
Σ
Sentence representation :
𝑖 th sentence : 𝑥% = 𝑥%',𝑥%),…, 𝑥%+
BoW : 𝑚% = ∑ 𝐴𝑥%//
Position Encoding : 𝑚% = ∑ 𝑙/ 1 𝐴𝑥%//
Temporal Encoding : 𝑚% = ∑ 𝐴𝑥%/ + 𝑇4(𝑖)/](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-7-320.jpg)

![The Goldilocks Principle: Reading Children's Books with Explicit
Memory Representations [Hill, 2016]
10](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-10-320.jpg)
![The Goldilocks Principle: Reading Children's Books with Explicit
Memory Representations [Hill, 2016]
11
• Context sentences : 𝑆 = 𝑠', 𝑠), … , 𝑠+ , 𝑠% ∶ BoW word representation
• Encoded memory : m; = 𝜙 𝑠 ∀𝑠 ∈ 𝑆
• Lexical memory
• Each word occupies a separate slot in the memory
• 𝑠 is a single word and 𝜙 𝑠 has only one non-zero feature
• Multiple hop only beneficial in this memory model
• Window memory (best)
• 𝑠 corresponds to a window of text from the context 𝑆 centered on an individual mention of a candidate 𝑐 in 𝑆
m; = 𝑤%A BA' )⁄ … 𝑤% … 𝑤%D BA' )⁄
• Where 𝑤% ∈ 𝐶 which is an instance of one of the candidate words
• Sentential memory
• Same as original implementation of Memory Network](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-11-320.jpg)
![The Goldilocks Principle: Reading Children's Books with Explicit
Memory Representations [Hill, 2016]
12
Self-supervision for window memories
- Memory supervision (knowing which memories to attend to) is not provided at training time
- Making gradient steps using SGD to force the model to give a higher score to the supporting
memory 𝒎G relative to any other memory from any other candidate using:
Hard attention (training and testing) : 𝑚H' = argmax
%M',…,+
𝑐%
N
𝑞
Soft attention (testing) : 𝑚H' = ∑ 𝛼% 𝑚%%M'…+ , 𝑤𝑖𝑡ℎ 𝛼% =
ST
U
VW
∑ S
T
U
VW
X
- If 𝑚H' happens to be different from 𝑚G (memory contain true answer), then model is updated
- Can be understood as a way of achieving hard attention over memories (no need any new
label information beyond the training data)](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-12-320.jpg)
![The Goldilocks Principle: Reading Children's Books with Explicit
Memory Representations [Hill, 2016]
13](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-13-320.jpg)
![Ask Me Anything: Dynamic Memory Networks for Natural Language
Processing [Kumar, 2015]
15](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-15-320.jpg)
![Ask Me Anything: Dynamic Memory Networks for Natural Language
Processing [Kumar, 2015]
16
I go to school.
He gets ball.
…
Where does he go?
GloVe
Embed
𝑦Y
I
go
to
GloVe
Embedwh
do
he
𝑞
𝑎Y
𝑦Y
𝑞
𝑎Y
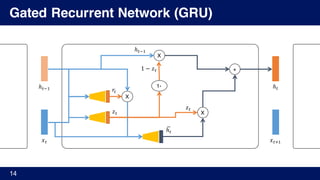
𝐺𝑅𝑈 𝐺𝑅𝑈
< 𝐸𝑂𝑆 >
ℎY 𝑒%
𝑒%
𝑮𝑹𝑼𝒍𝒊𝒔𝒉
Episodic Memory
𝑔Y
%
Input Module
Answer Module
Question Module](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-16-320.jpg)
![Ask Me Anything: Dynamic Memory Networks for Natural Language
Processing [Kumar, 2015]
17
𝑐Y
ℎY 𝑒%
I go to school.
He gets ball.
…
𝑔Y
%
Where does he go?
𝑞
GloVe
Embed
𝐺𝑅𝑈(𝐿[𝑤Y
s
], ℎYA'
u
) = ℎY
u
= 𝑐Y
𝑦Y
I
go
to
Input Memory
Episodic Memory 𝑒% 𝑚%
𝑞
GloVe
EmbedI
go
to𝑞Y = 𝐺𝑅𝑈(𝐿 𝑤Y
v
, 𝑞YA')
ℎN
%
= 𝑒%
𝑔Y
%
= 𝑮(𝑐Y, 𝑚%A'
, 𝑞)
𝑮𝑹𝑼𝒍𝒊𝒔𝒉ℎY
%
= 𝑔Y
%
𝐺𝑅𝑈 𝑐Y, ℎYA'
%
+ (1 − 𝑔Y
%
) ℎYA'
%
𝑚%
new Memory
Gate
𝑞
𝑎Y
𝑦Y
𝑞
𝑎Y
𝐺𝑅𝑈 𝐺𝑅𝑈
< 𝐸𝑂𝑆 >
𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑠𝑜𝑓𝑡𝑚𝑎𝑥](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-17-320.jpg)
![Ask Me Anything: Dynamic Memory Networks for Natural Language
Processing [Kumar, 2015]
18
ℎY 𝑒Y
I go to school.
He gets ball.
…
Where does he go?
GloVe
Embed
𝐺𝑅𝑈(𝐿[𝑤Y
s
], ℎYA'
u
) = ℎY
u
= 𝑐Y
𝑦Y
I
go
to
Input Memory
Episodic Memory 𝑒Y 𝑚%
GloVe
EmbedI
go
to𝑞Y = 𝐺𝑅𝑈(𝐿 𝑤Y
v
, 𝑞YA')
ℎN
%
= 𝑒%
𝑮𝑹𝑼𝒍𝒊𝒔𝒉ℎY
%
= 𝑔Y
%
𝐺𝑅𝑈 𝑐Y, ℎYA'
%
+ (1 − 𝑔Y
%
) ℎYA'
%
𝑚%
new Memory
𝑞
𝑎Y
𝑦Y
𝑞
𝑎Y
𝐺𝑅𝑈 𝐺𝑅𝑈
< 𝐸𝑂𝑆 >
𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑠𝑜𝑓𝑡𝑚𝑎𝑥
𝑔Y
%
= 𝑮(𝑐Y, 𝑚%A'
, 𝑞)Gate
feature vector : captures a similarities between c, m, q
G : two-layer feed forward neural network
Attention Mechanism
𝑞𝑞𝑐Y
𝑔Y
%](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-18-320.jpg)
![Ask Me Anything: Dynamic Memory Networks for Natural Language
Processing [Kumar, 2015]
19
𝑐Y
ℎY 𝑒Y
I go to school.
He gets ball.
…
𝑔Y
%
Where does he go?
𝑞
GloVe
Embed
𝐺𝑅𝑈(𝐿[𝑤Y
s
], ℎYA'
u
) = ℎY
u
= 𝑐Y
𝑦Y
I
go
to
Input Memory
Episodic Memory
𝑞
GloVe
EmbedI
go
to𝑞Y = 𝐺𝑅𝑈(𝐿 𝑤Y
v
, 𝑞YA')
ℎN
%
= 𝑒%
𝑮𝑹𝑼𝒍𝒊𝒔𝒉
𝑞
𝑎Y
𝑦Y
𝑞
𝑎Y
𝐺𝑅𝑈 𝐺𝑅𝑈
< 𝐸𝑂𝑆 >
𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑠𝑜𝑓𝑡𝑚𝑎𝑥
𝑔Y
%
= 𝑮(𝑐Y, 𝑚%A'
, 𝑞)Gate
ℎY
%
= 𝑔Y
%
𝐺𝑅𝑈 𝑐Y, ℎYA'
%
+ (1 − 𝑔Y
%
) ℎYA'
%
𝑒%
= ℎNy
%
new Memory
Episodic memory update
𝑒% 𝑚%
𝑚%
𝑚%
= 𝐺𝑅𝑈(𝑒%
, 𝑚%A'
)
Episodic Memory Module
- Iterates over input representations, while updating episodic memory 𝒆𝒊
- Attention mechanism + Recurrent network → Update memory 𝒎 𝒊
Memory update](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-19-320.jpg)
![Ask Me Anything: Dynamic Memory Networks for Natural Language
Processing [Kumar, 2015]
20
𝑐Y
I go to school.
He gets ball.
…
𝑔Y
%
Where does he go?
𝑞
GloVe
Embed
𝐺𝑅𝑈(𝐿[𝑤Y
s
], ℎYA'
u
) = ℎY
u
= 𝑐Y
𝑦Y
I
go
to
Input Memory
Episodic Memory
GloVe
EmbedI
go
to𝑞Y = 𝐺𝑅𝑈(𝐿 𝑤Y
v
, 𝑞YA')
ℎN
%
= 𝑒%
𝑮𝑹𝑼𝒍𝒊𝒔𝒉
𝑞
𝑎Y
𝑦Y
𝑞
𝑎Y
𝐺𝑅𝑈 𝐺𝑅𝑈
< 𝐸𝑂𝑆 >
𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑠𝑜𝑓𝑡𝑚𝑎𝑥
𝑔Y
%
= 𝑮(𝑐Y, 𝑚%A'
, 𝑞)Gate
ℎY
%
= 𝑔Y
%
𝐺𝑅𝑈 𝑐Y, ℎYA'
%
+ (1 − 𝑔Y
%
) ℎYA'
%
new Memory
ℎY 𝑒%
𝑞
𝑒% 𝑚%
𝑚%
Multiple Episodes
- Allows to attend to different inputs during each pass
- Allows for a type of transitive inference, since the first
pass may uncover the need to retrieve additional facts.
Q : Where is the football?
C1 : John put down the football.
Only once the model sees C1, John is relevant,
can reason that the second iteration should
retrieve where John was.
Criteria for Stopping
- Append a special end-of-passes
representation to the input 𝒄
- Stop if this representation is chosen by
the gate function
- Set a maximum number of iterations
- This is why called Dynamic MM](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-20-320.jpg)
![Ask Me Anything: Dynamic Memory Networks for Natural Language
Processing [Kumar, 2015]
21
𝑐Y
I go to school.
He gets ball.
…
𝑔Y
%
Where does he go?
GloVe
Embed
𝐺𝑅𝑈(𝐿[𝑤Y
s
], ℎYA'
u
) = ℎY
u
= 𝑐Y
I
go
to
Input Memory
Episodic Memory
GloVe
EmbedI
go
to𝑞Y = 𝐺𝑅𝑈(𝐿 𝑤Y
v
, 𝑞YA')
ℎN
%
= 𝑒%
𝑮𝑹𝑼𝒍𝒊𝒔𝒉
𝑔Y
%
= 𝑮(𝑐Y, 𝑚%A'
, 𝑞)Gate
ℎY
%
= 𝑔Y
%
𝐺𝑅𝑈 𝑐Y, ℎYA'
%
+ (1 − 𝑔Y
%
) ℎYA'
%
new Memory
ℎY 𝑒Y
𝑞
𝑒Y
𝑚%
𝑞
𝑦Y
𝑞
𝑎Y
𝑦Y
𝑞
𝑎Y
𝐺𝑅𝑈 𝐺𝑅𝑈
< 𝐸𝑂𝑆 >
𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑠𝑜𝑓𝑡𝑚𝑎𝑥
𝑚%
Answer Module
- Triggered once at the end of the episodic memory or at
each time step
- Concatenate the last generated word and the question
vector as the input at each time step
- Cross-entropy error](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-21-320.jpg)



![Dynamic Memory Networks for Visual and Textual Question
Answering [Xiong 2016]
25
Several design choices are motivated by intuition and accuracy improvements](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-25-320.jpg)


![Input Module for DMN+
28
Referenced paper : A Hierarchical Neural Autoencoder for Paragraphs and Documents [Li, 2015]](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-28-320.jpg)
![Episodic Memory Module in DMN+
- 𝐹⃡ = [𝑓', 𝑓), … , 𝑓“] : output of the input module
- Interactions between the fact 𝒇 𝒊 and both the question 𝒒 and episode memory
state 𝒎𝒕
29](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-29-320.jpg)




![ABCNN: Attention-Based Convolutional Neural Network for Modeling
Sentence Pairs [Yin 2015]
34](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-34-320.jpg)
![ABCNN: Attention-Based Convolutional Neural Network for Modeling
Sentence Pairs [Yin 2015]
35
• Most prior work on answer selection model each sentence separately and
neglects mutual influence
• Human focus on key parts of 𝑠Ÿ by extracting parts from 𝑠' related by
identity, synonymy, antonym etc.
• ABCNN : taking into account the interdependence between 𝑠Ÿ and 𝑠'
• Convolution layer : increase abstraction of a phrase from words](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-35-320.jpg)
![ABCNN: Attention-Based Convolutional Neural Network for Modeling
Sentence Pairs [Yin 2015]
36
1. Input embedding with word2vec
2-1. Convolution layer with wide convolution
• To make each word 𝑣% to be detected by all weights in 𝑊
2-2. Average pooling layer
• all-ap : column-wise averaging over all columns
• w-ap : column-wise averaging over windows of 𝑤
3. Output layer with logistic regression
• Forward all-ap to all non-final ap layer + final ap layer](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-36-320.jpg)
![ABCNN: Attention-Based Convolutional Neural Network for Modeling
Sentence Pairs [Yin 2015]
37
Attention on feature map (ABCNN-1)
• Attention values of row 𝑖 in 𝑨 : attention distribution of the 𝑖−th unit of 𝑠Ÿ with respect to 𝑠'
• 𝐴%,/ = 𝑚𝑎𝑡𝑐ℎ𝑠𝑐𝑜𝑟𝑒(𝐹Ÿ,¢ :, 𝑖 , 𝐹',¢ :, 𝑗 )
• 𝑚𝑎𝑡𝑐ℎ𝑠𝑐𝑜𝑟𝑒 = 1/(1 + 𝑥 − 𝑦 )
• Generate the attention feature map 𝐹%,¦ for 𝑠%
• Cons : need more parameters](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-37-320.jpg)
![ABCNN: Attention-Based Convolutional Neural Network for Modeling
Sentence Pairs [Yin 2015]
38
Attention after convolution (ABCNN-2)
• Attention weights directly on the representation with the aim of improving the
features computed by convolution
• 𝑎Ÿ,/ = ∑𝐴 𝑗, : → col-wise, row-wise sum
• w-ap on convolution feature](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-38-320.jpg)
![ABCNN: Attention-Based Convolutional Neural Network for Modeling
Sentence Pairs [Yin 2015]
39
ABCNN-1 ABCNN-2
Indirect impact to convolution
Direct convolution via pooling
(weighted attention)
Need more features
Vulnerable to overfitting
No need features
handles smaller-granularity units
(ex. Word level)
handles larger-granularity units
(ex. Phrase level, phrase size = window size)
ABCNN-3](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-39-320.jpg)
![ABCNN: Attention-Based Convolutional Neural Network for Modeling
Sentence Pairs [Yin 2015]
40](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-40-320.jpg)
![Empirical Study on Deep Learning Models for QA [Yu 2015]
41](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-41-320.jpg)
![Empirical Study on Deep Learning Models for QA [Yu 2015]
42
The first to examine Neural Turing Machines on QA problems
Split QA into two step
1. search supporting facts
2. Generate answer from relevant pieces of information
NTM
• Single-layer LSTM network as controller
• Input : word embedding
1. Support fact only
2. Fact highlighted : user marker to annotate begin and end of supporting facts
• Output : softmax layer (multiclass classification) for answer](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-42-320.jpg)
![Teaching Machines to Read and Comprehend [Hermann 2015]
43](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-43-320.jpg)
![Teaching Machines to Read and Comprehend [Hermann 2015]
44
where 𝑓% = 𝑦§ 𝑡
𝑠(𝑡) : degree to which the network
attends to a particular token in the
document when answering the query
(soft attention)](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-44-320.jpg)
![Text Understanding with the Attention Sum Reader Network [Kadlec 2016]
45
Answer should be in context
Inspired by Pinter Network
Contrast to Attentive Reader:
• We select answer from context
directly using weighted sum of
individual representation Attentive Reader](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-45-320.jpg)
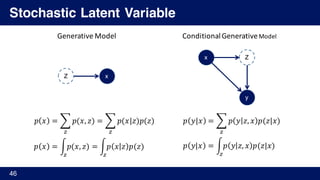




![Neural Variational Document Model [Miao, 2015]
51](https://image.slidesharecdn.com/1reasoning-160317105004/85/Deep-Reasoning-51-320.jpg)

The document describes several papers on deep learning models for natural language processing tasks that utilize memory networks or attention mechanisms. It begins with references to seminal papers on end-to-end memory networks and dynamic memory networks. It then provides examples of tasks these models have been applied to, such as question answering, and summarizes the training procedures and architectures of memory networks and dynamic memory networks. Finally, it discusses extensions like utilizing episodic memory with multiple passes over the inputs and attention mechanisms.








![[GAN by Hung-yi Lee]Part 2: The application of GAN to speech and text processing](https://cdn.slidesharecdn.com/ss_thumbnails/part2v2-180809095331-thumbnail.jpg?width=640&height=640&fit=bounds)































![[246]reasoning, attention and memory toward differentiable reasoning machines](https://cdn.slidesharecdn.com/ss_thumbnails/246reasoningattentionandmemory-towarddifferentiablereasoningmachines-171017054258-thumbnail.jpg?width=640&height=640&fit=bounds)



![[246]QANet: Towards Efficient and Human-Level Reading Comprehension on SQuAD](https://cdn.slidesharecdn.com/ss_thumbnails/246qanetdeview2018-181012000849-thumbnail.jpg?width=640&height=640&fit=bounds)






![Random Thoughts on Paper Implementations [KAIST 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/kaist2018-180426031539-thumbnail.jpg?width=640&height=640&fit=bounds)






























