Download as PDF, PPTX



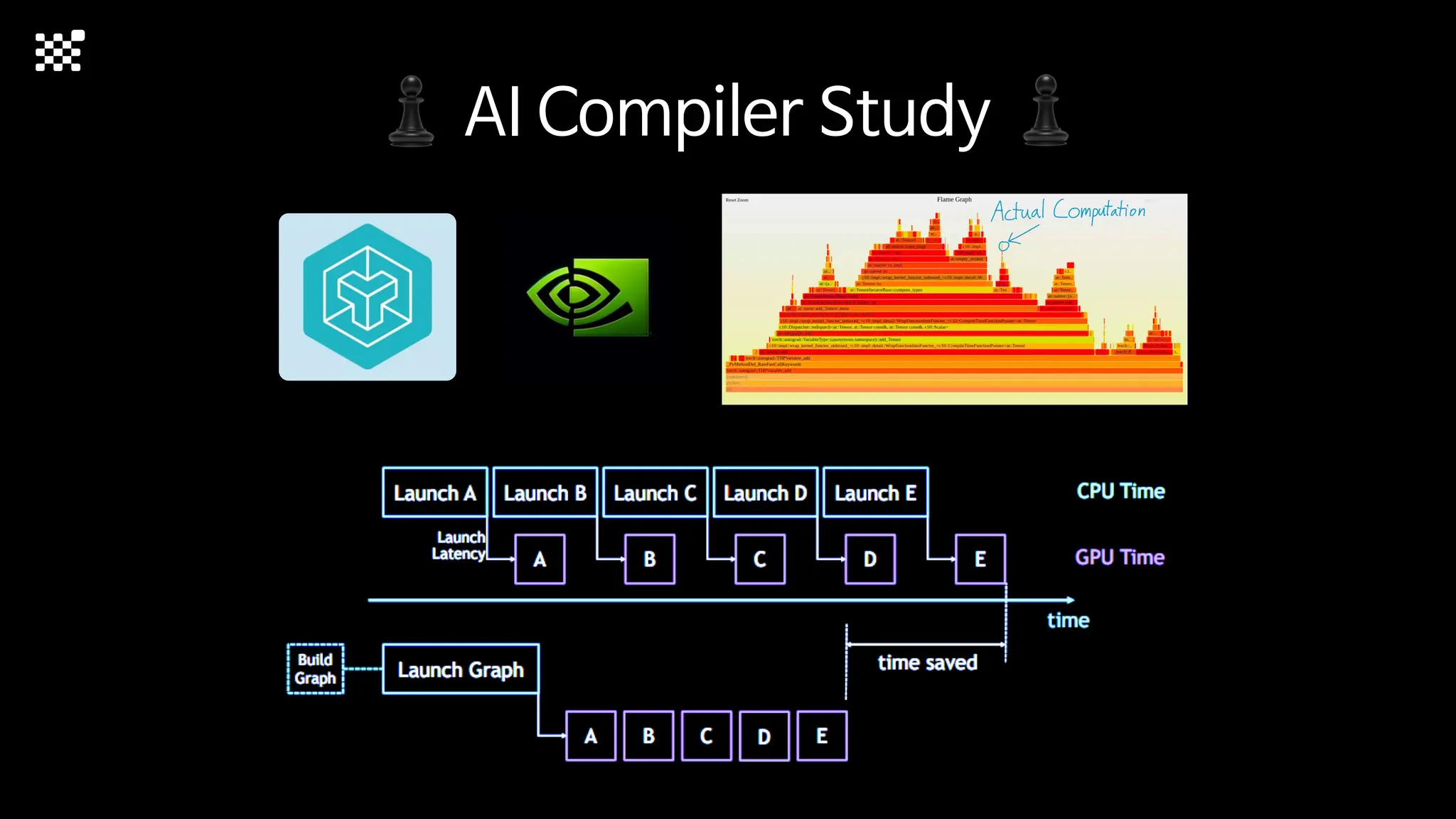







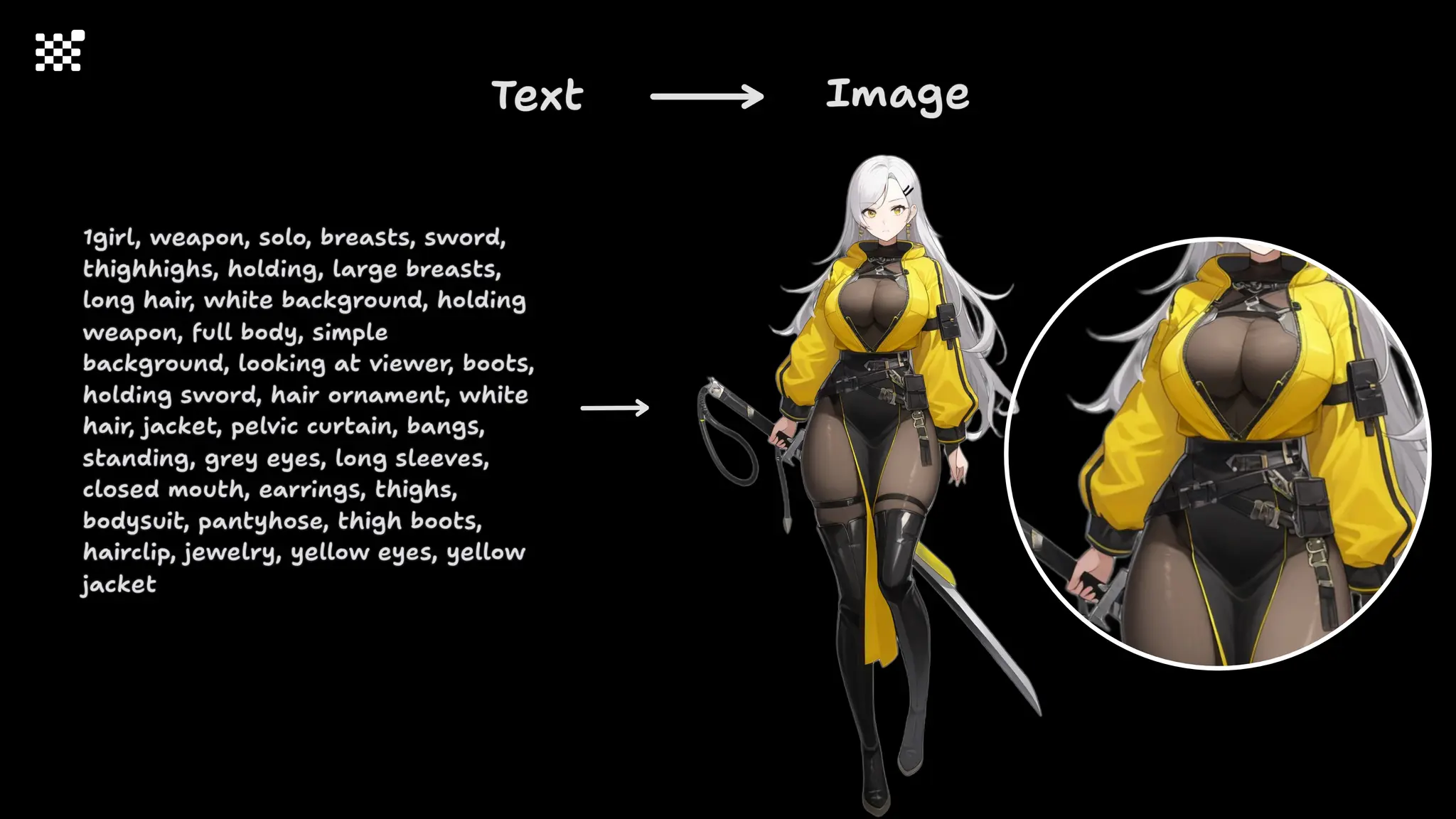















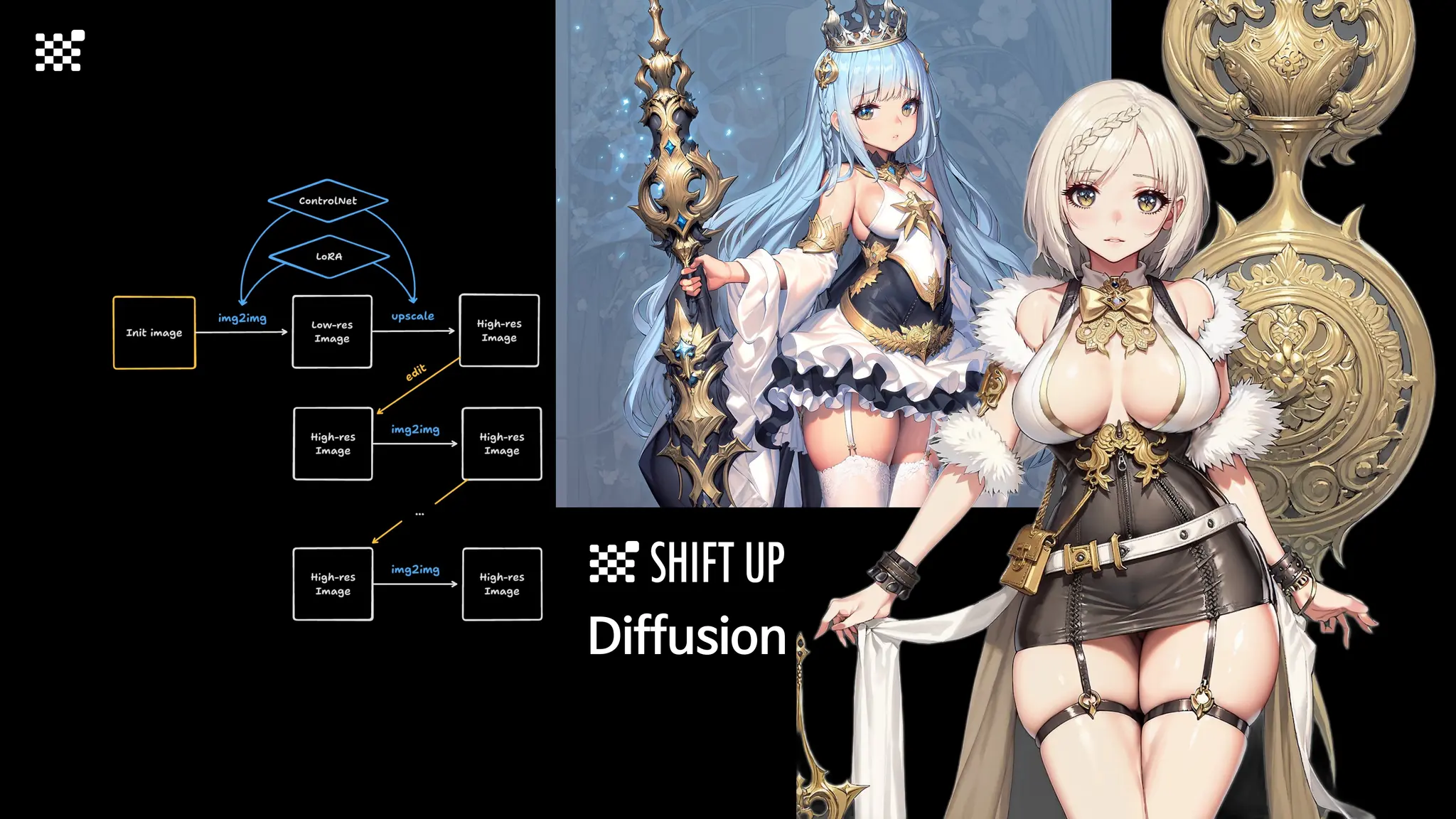
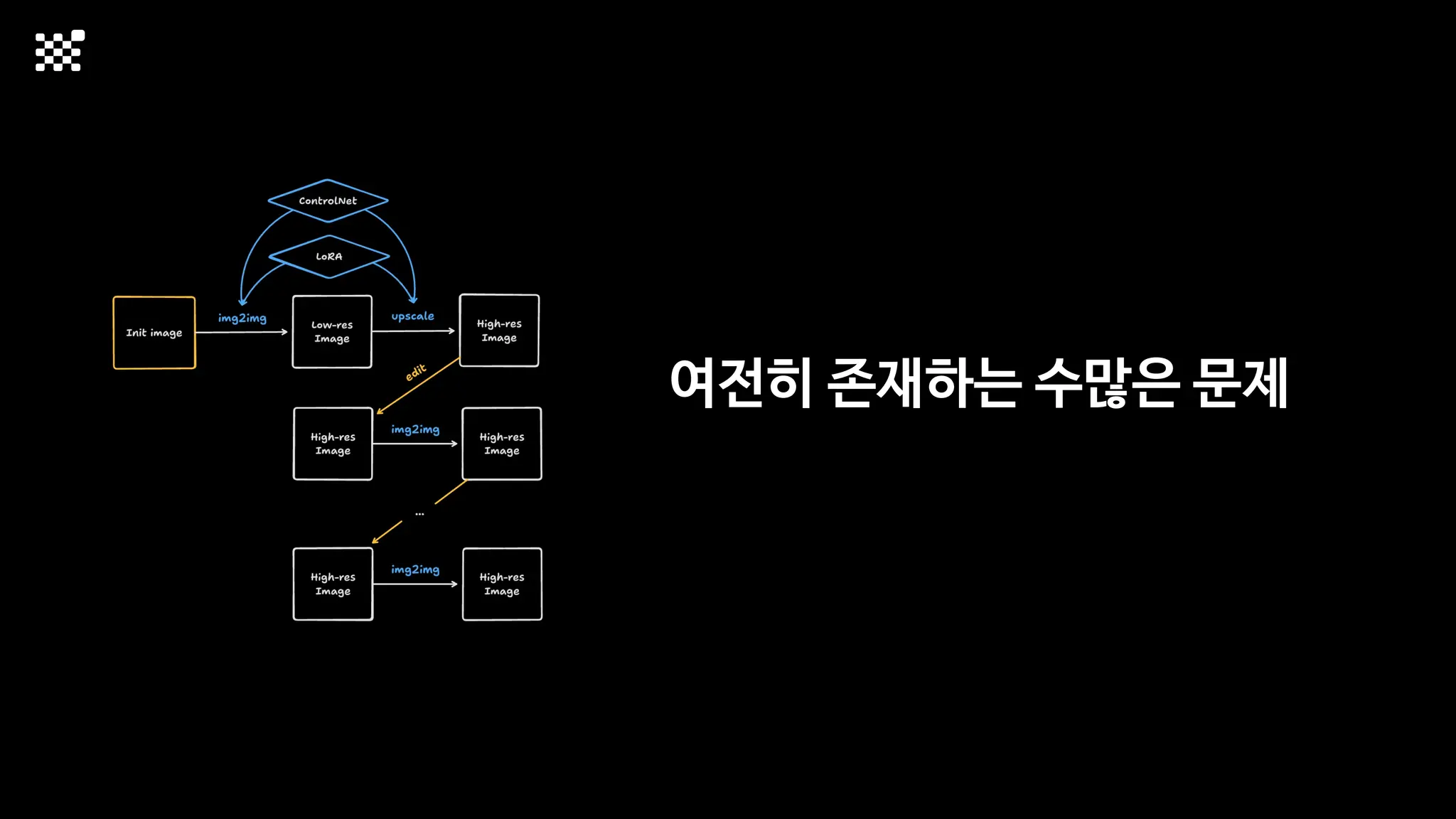





















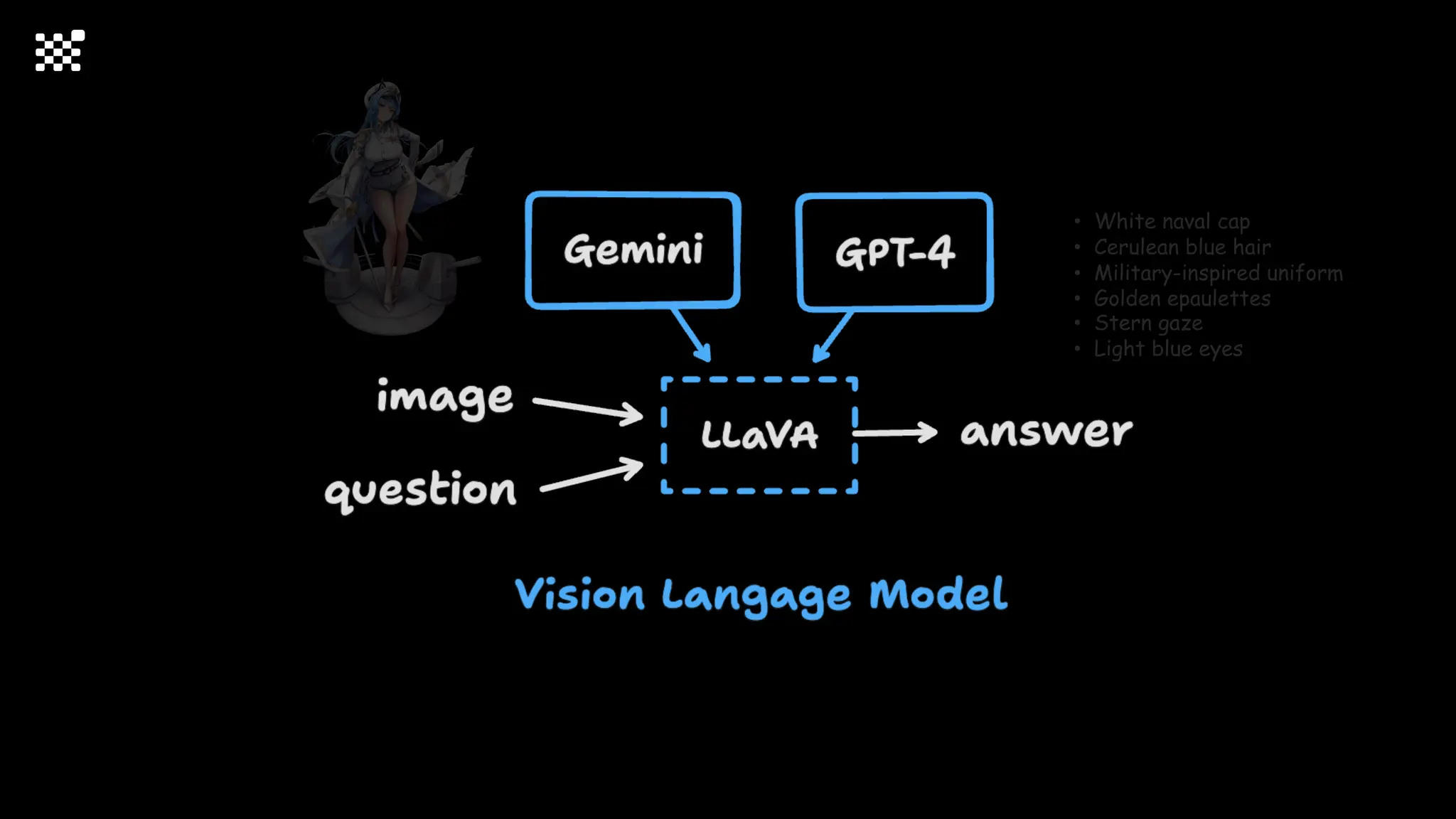










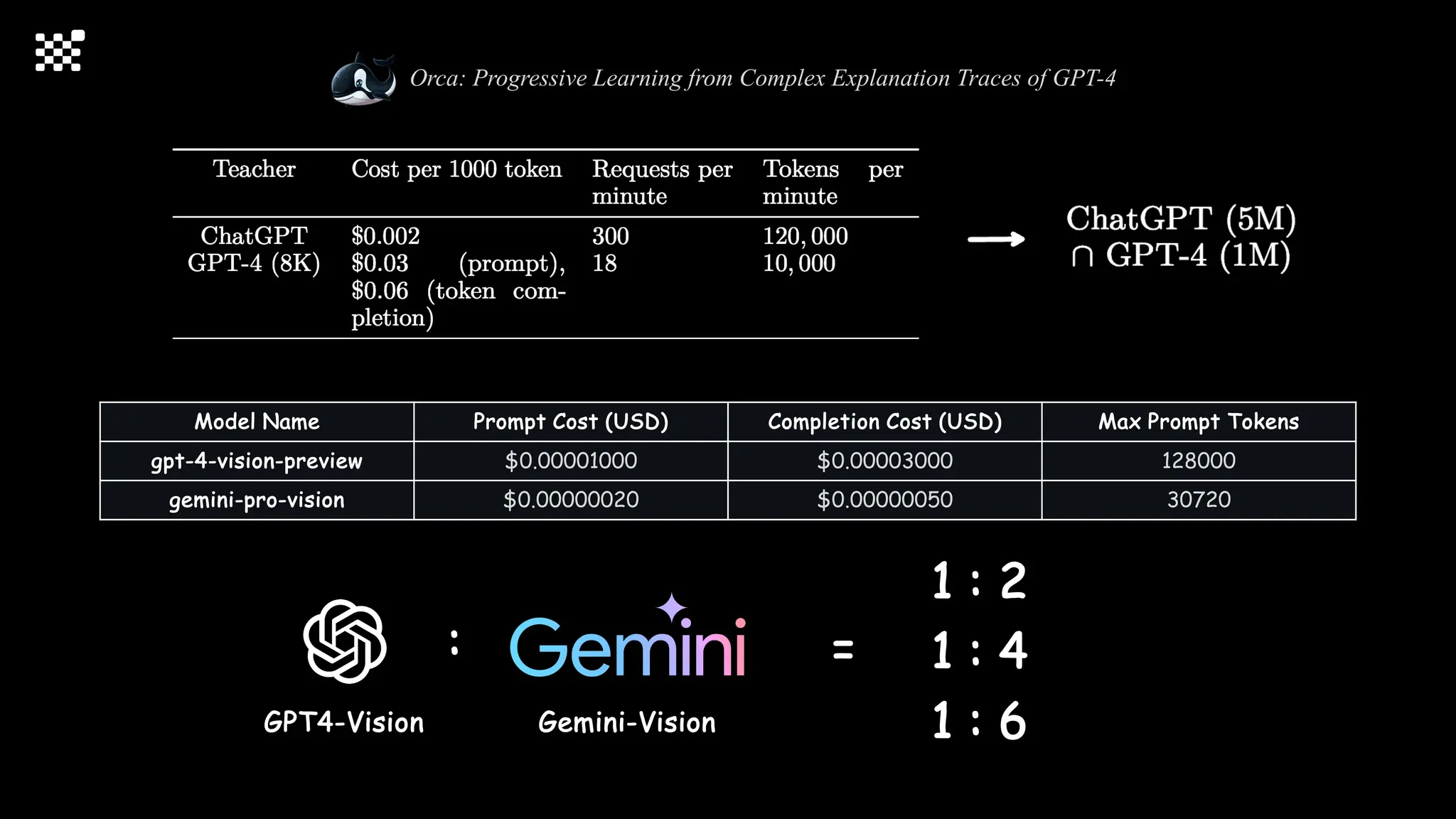

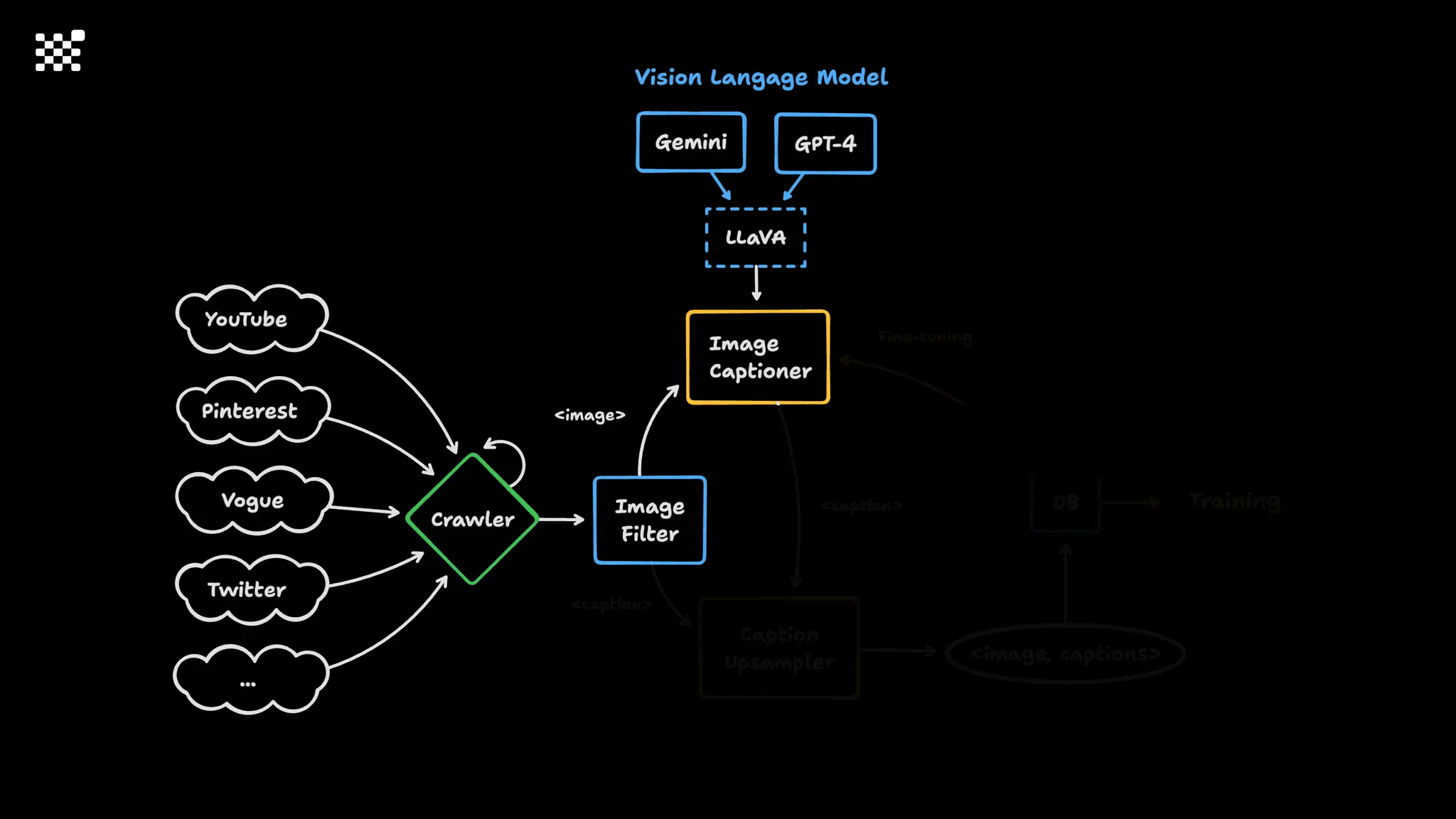
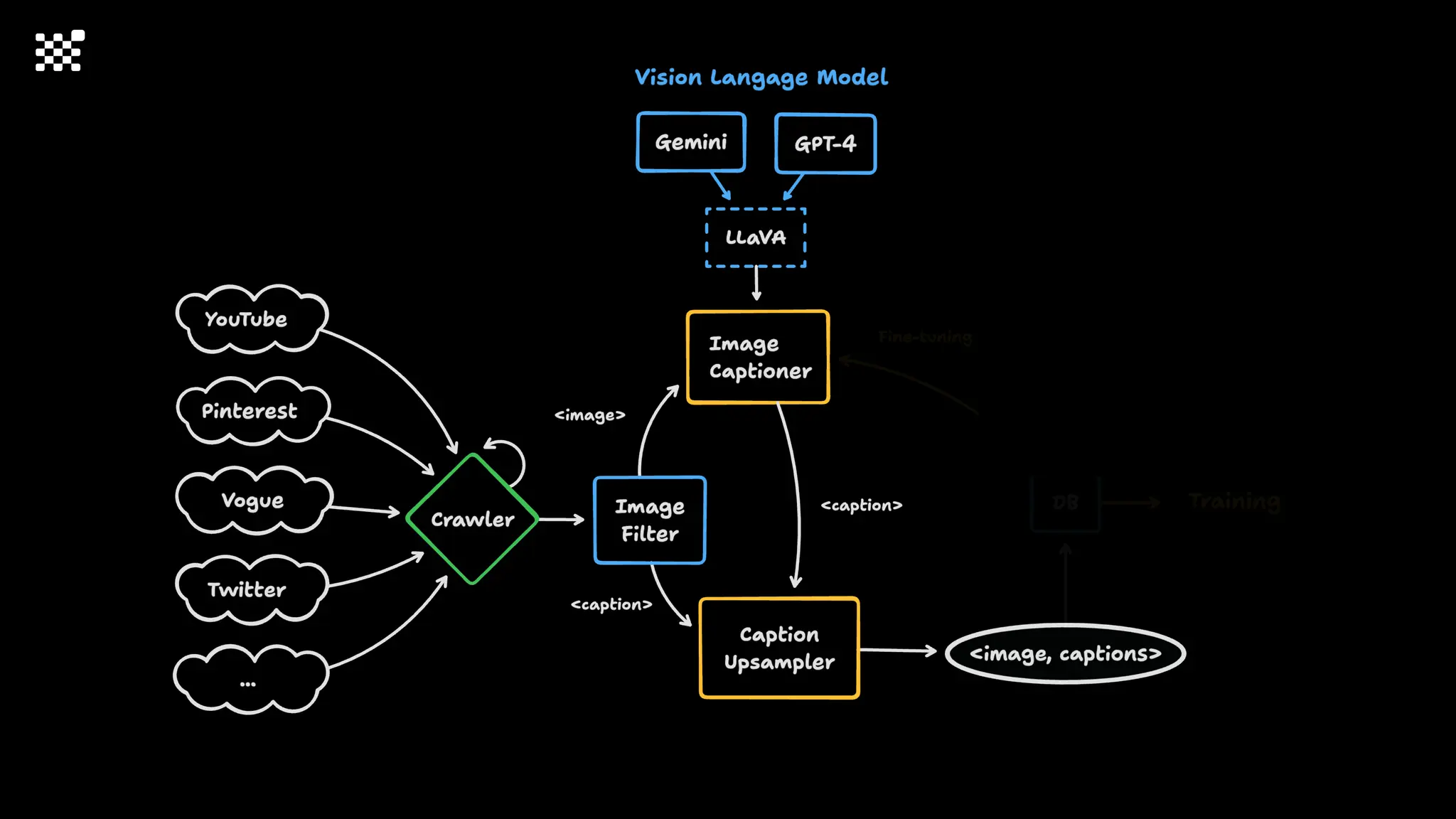




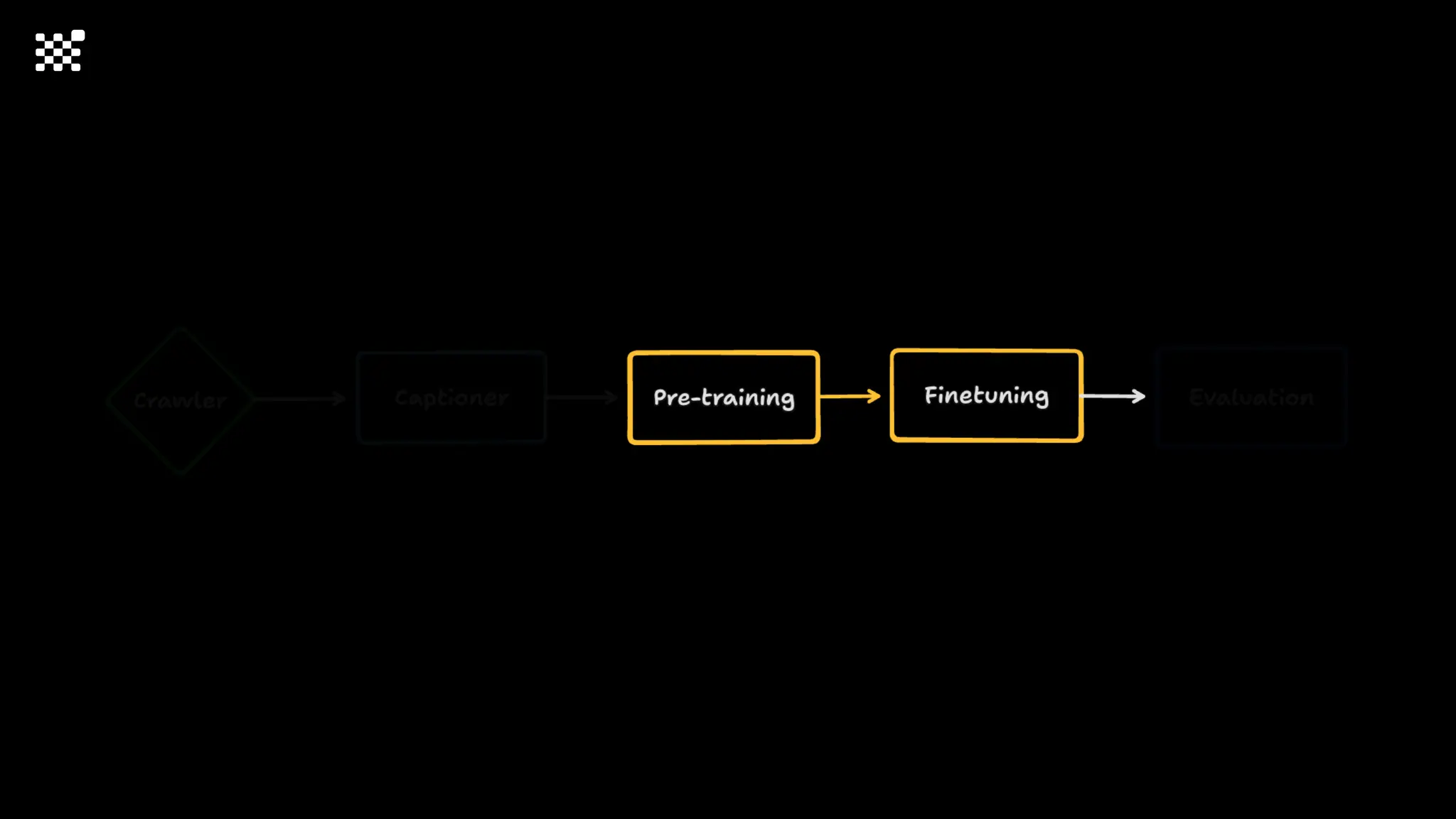


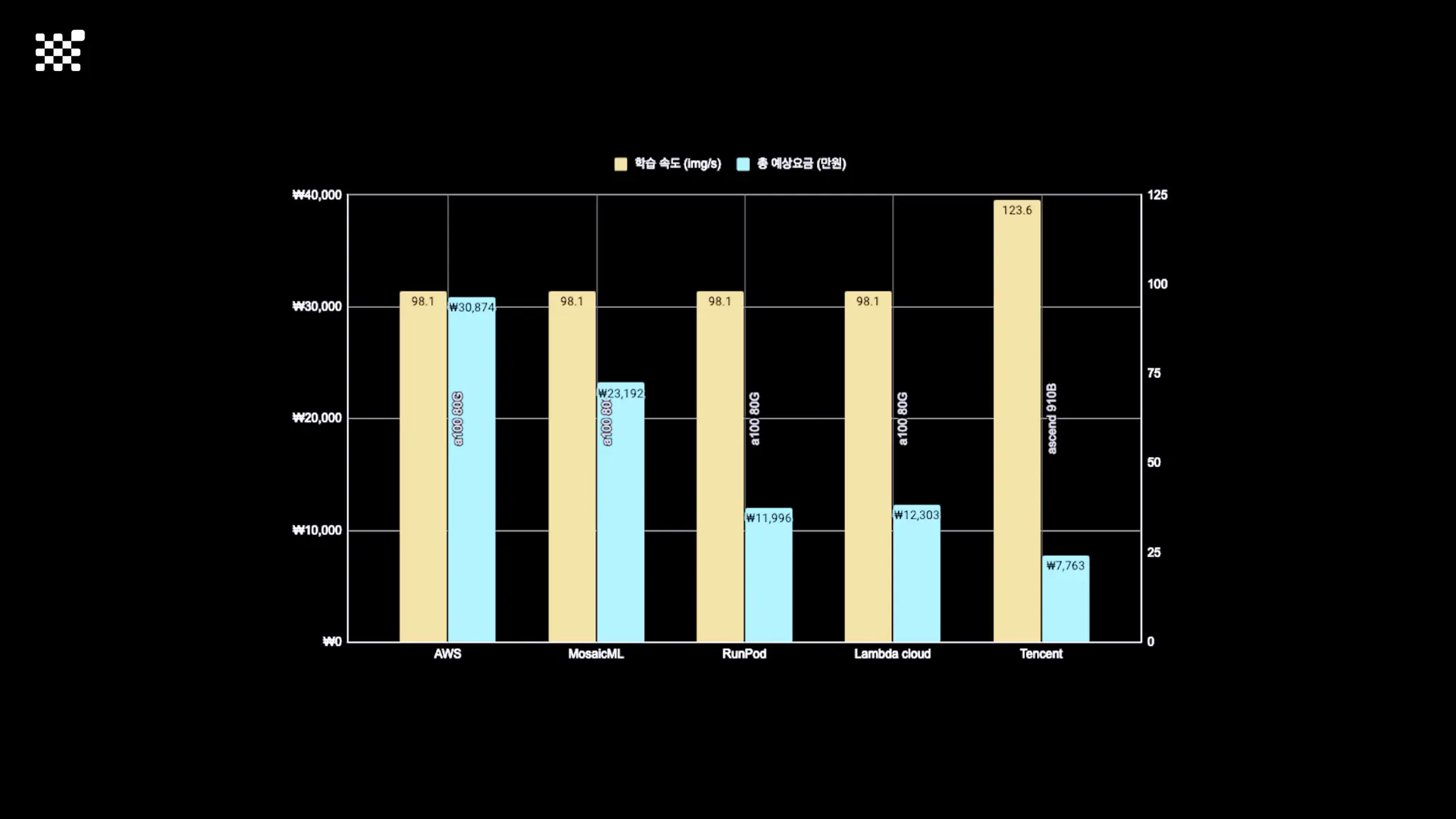



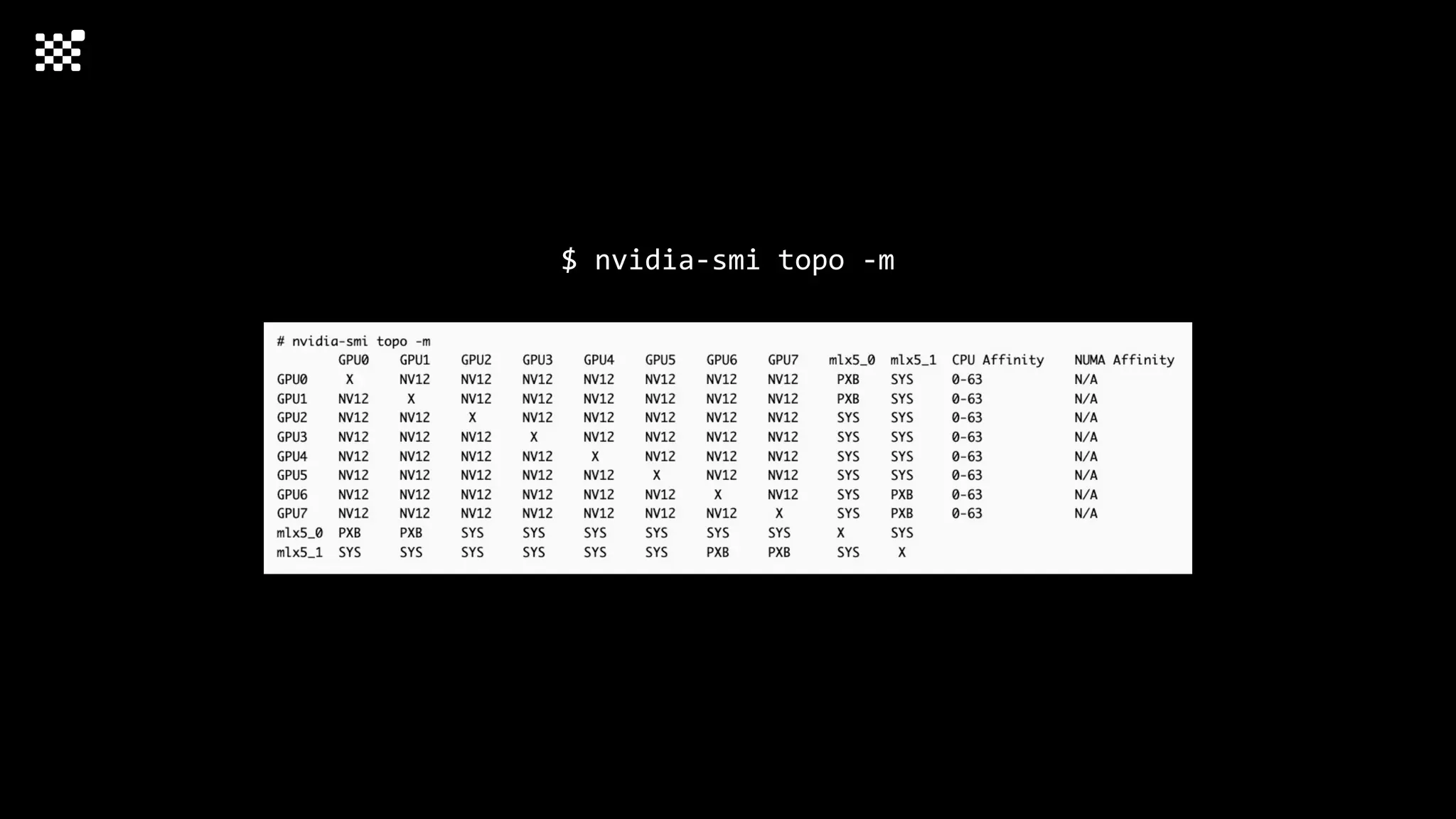


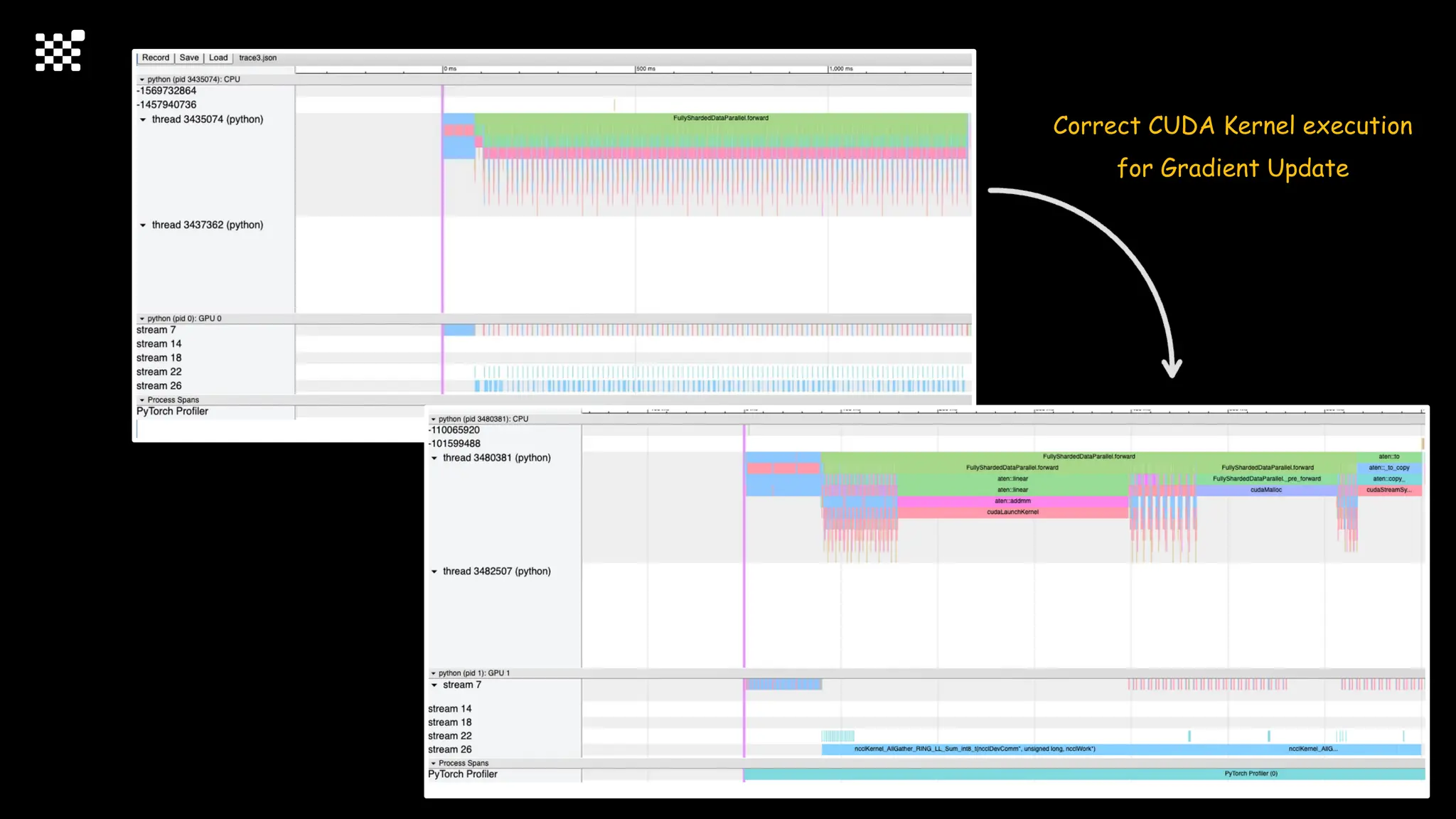
![Training Speed Error
from torch.profiler import profile, record_function, ProfilerActivity
with profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
record_shapes=True
) as prof:
# 문제가 있던 코드
optimizer.step()
prof.export_chrome_trace("trace.json")](https://image.slidesharecdn.com/2024attentionxpublic-240329071953-16f92dd7/75/LLM-ZERO-Training-Large-Scale-Diffusion-Model-from-Scratch-132-2048.jpg)
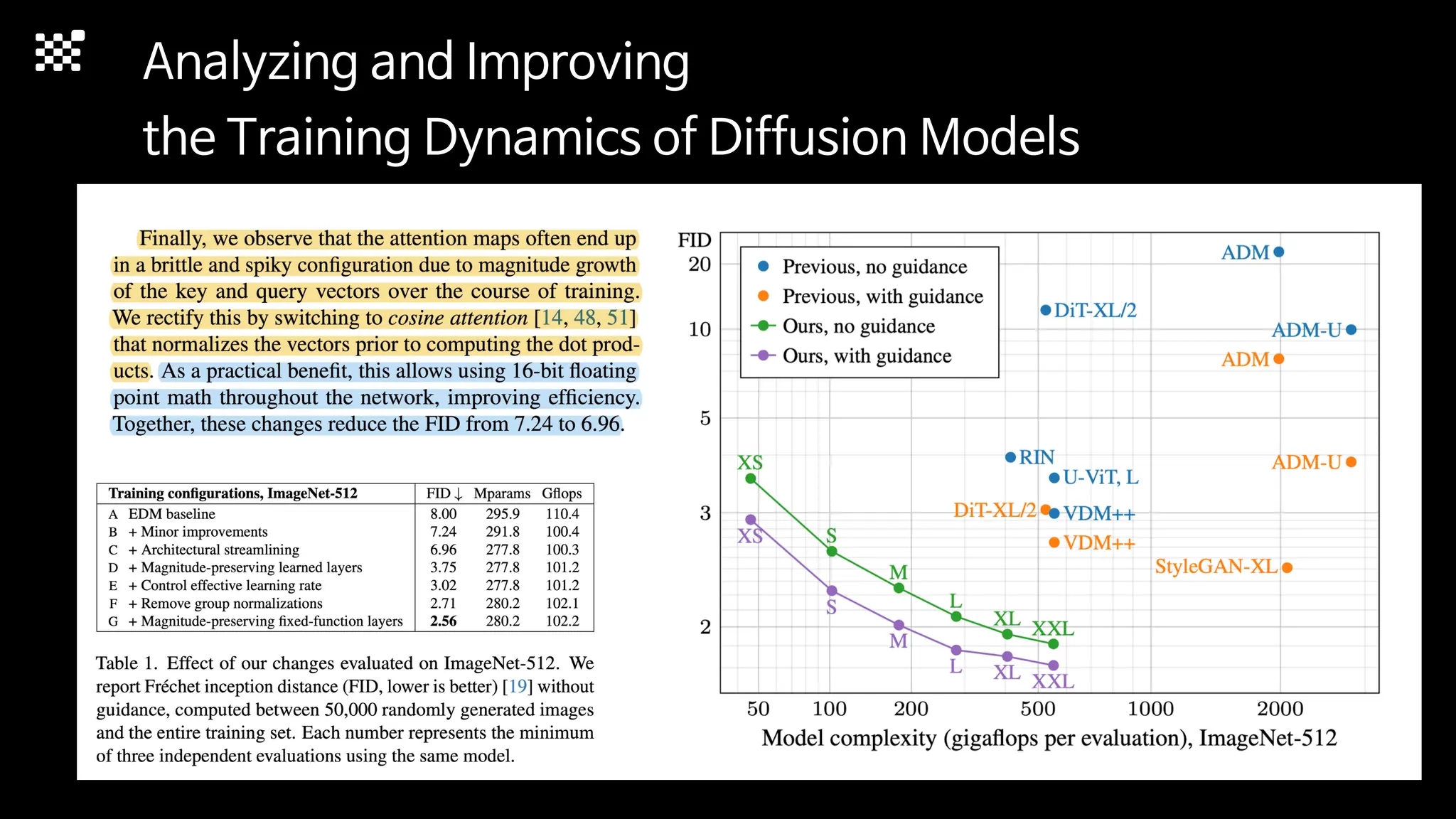
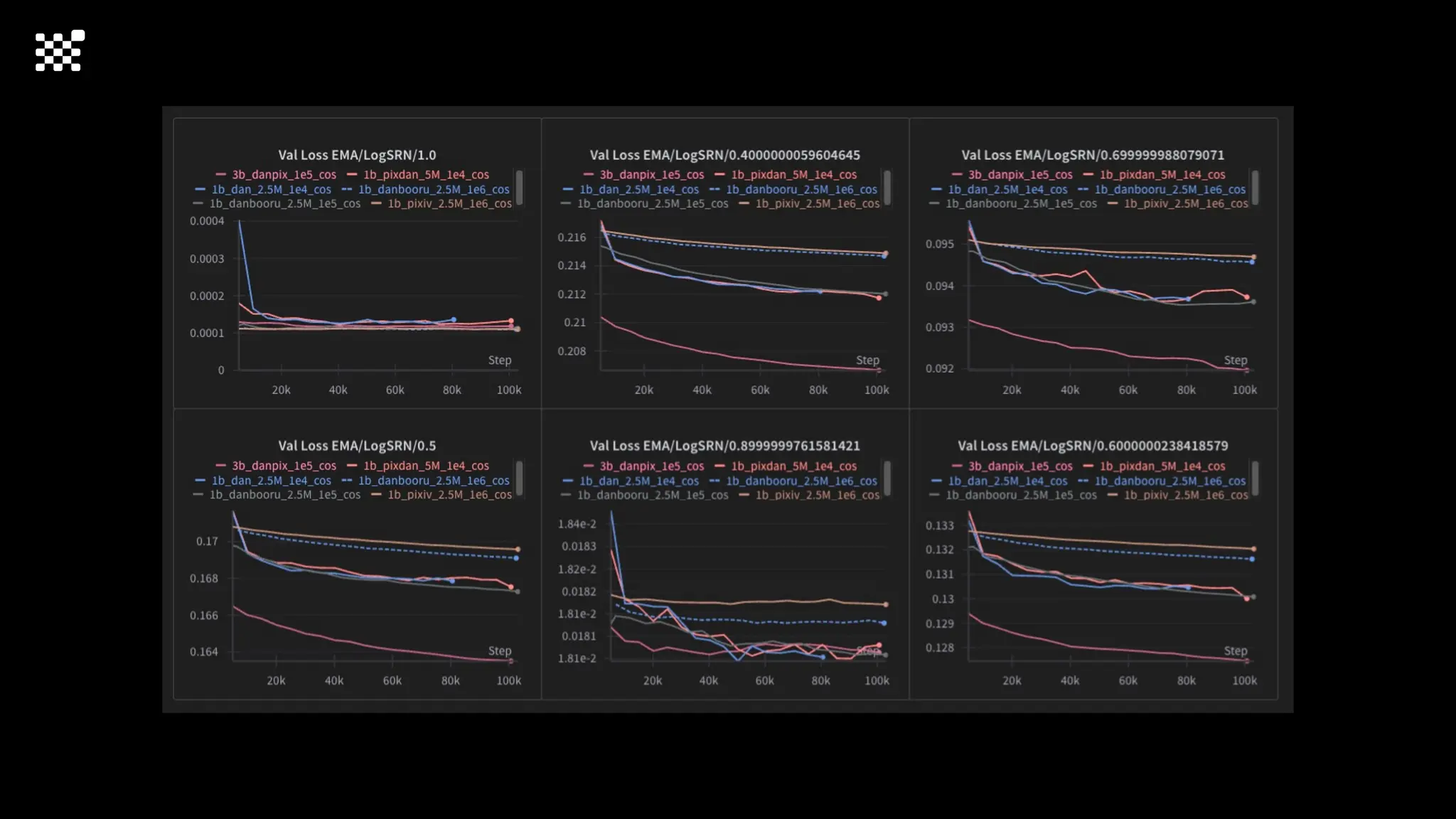




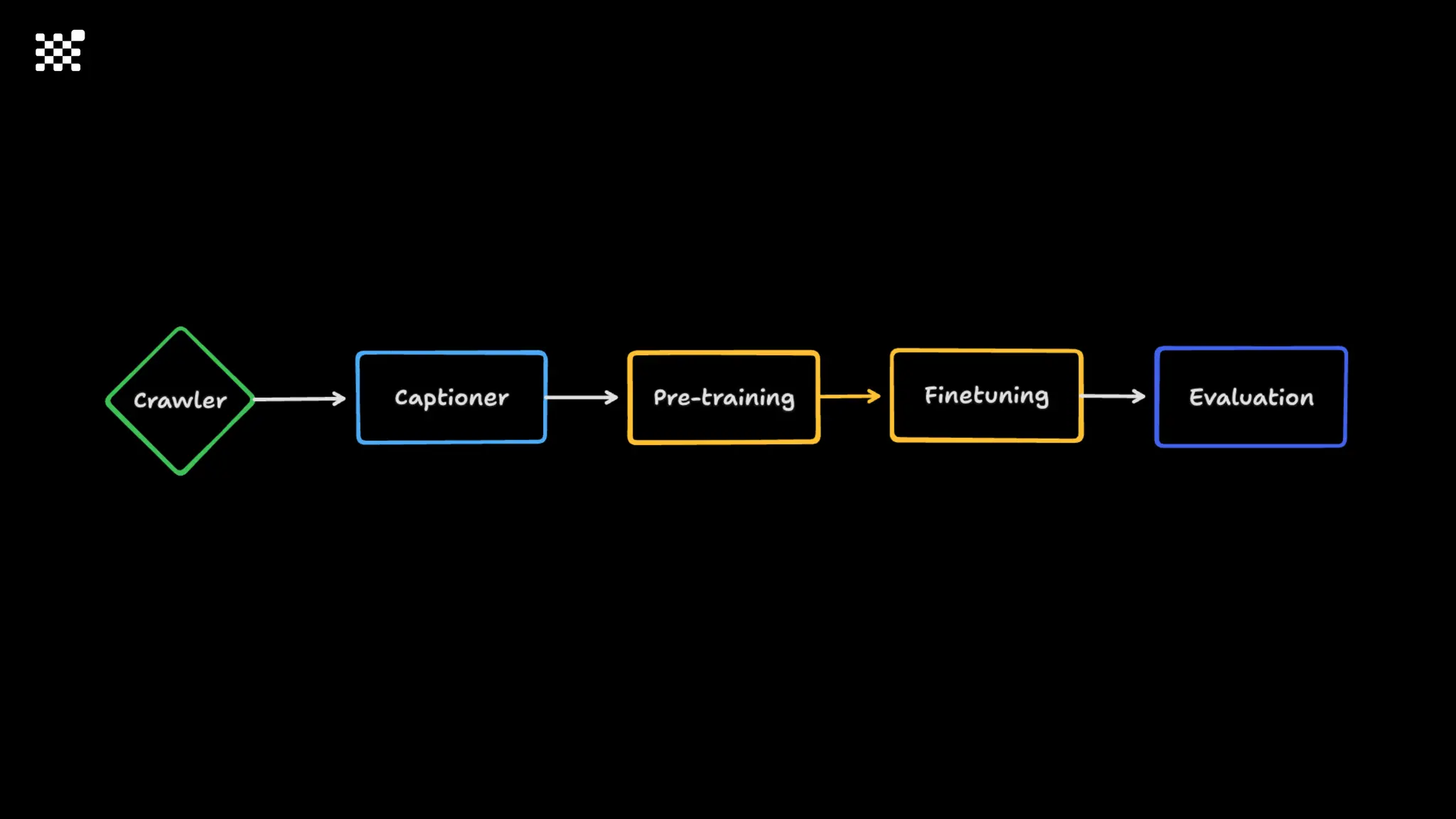













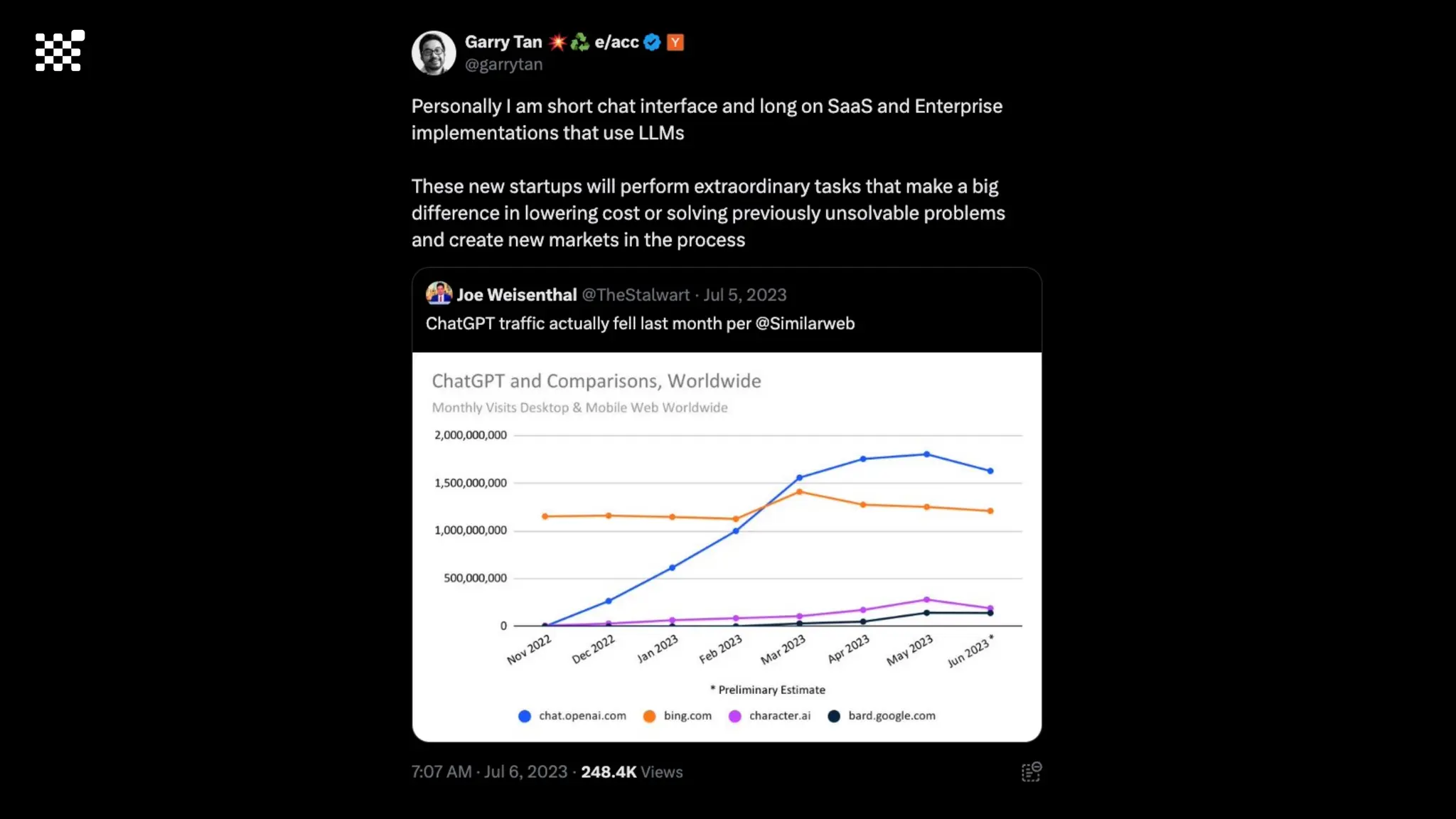



















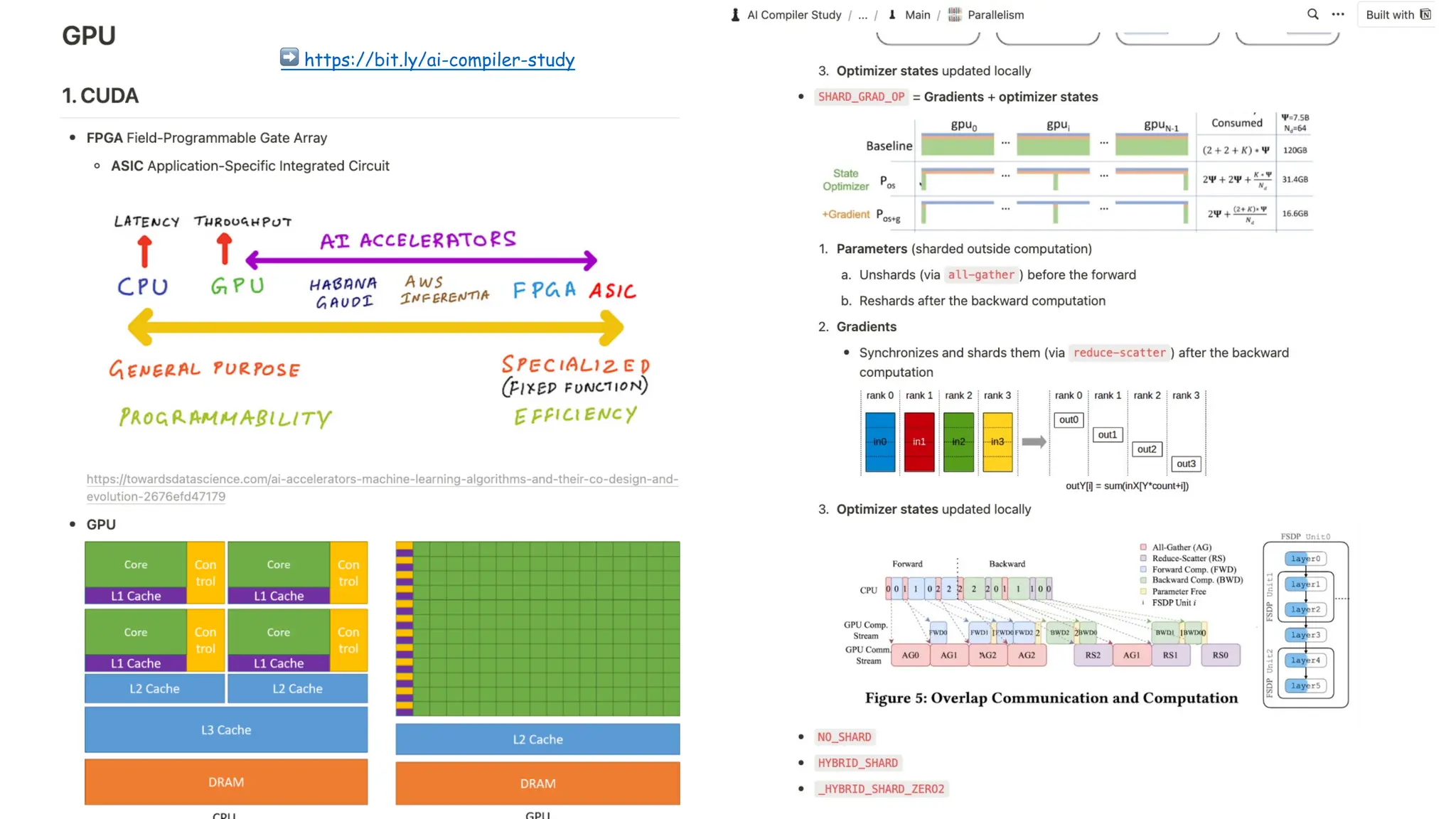

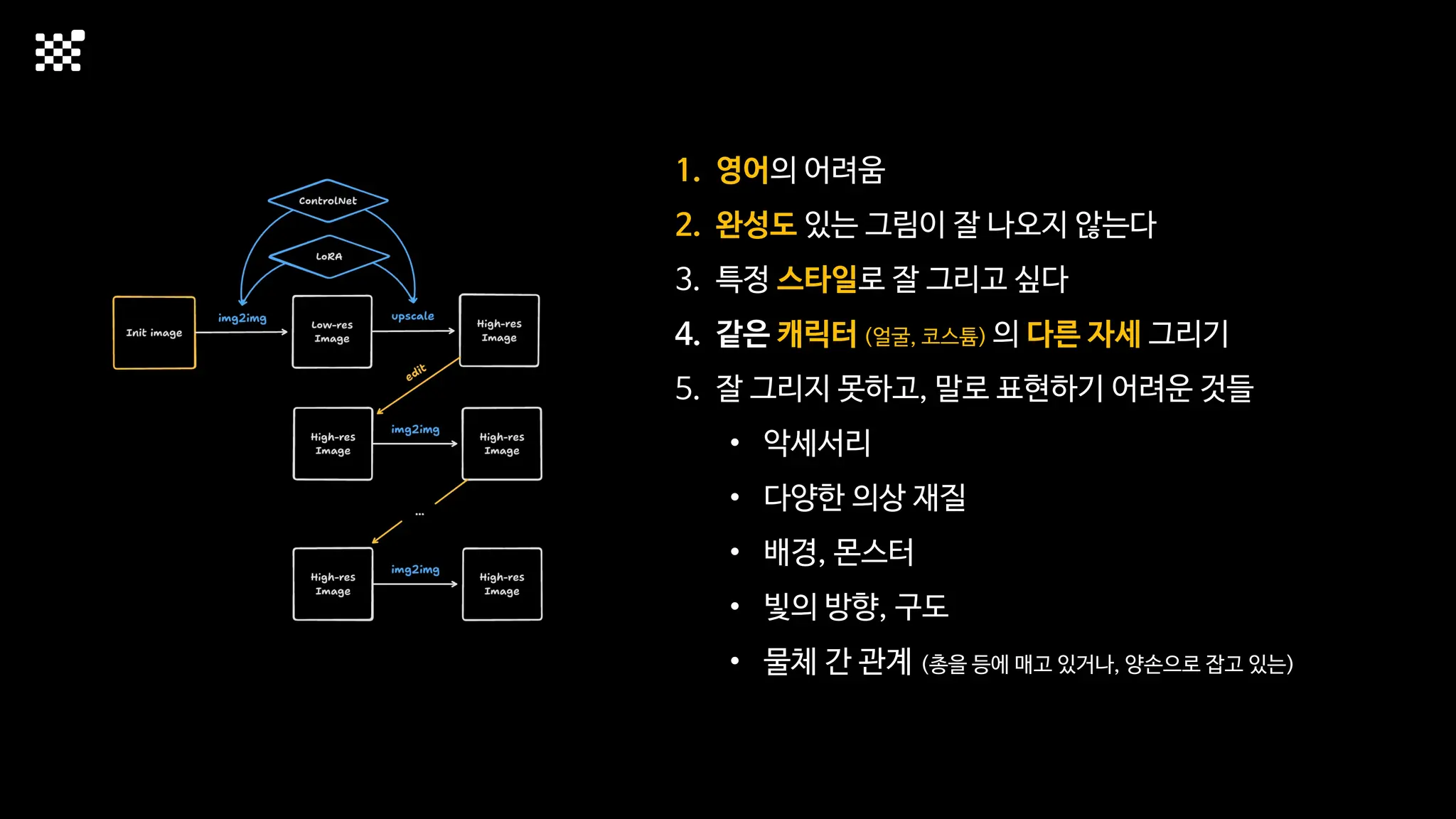
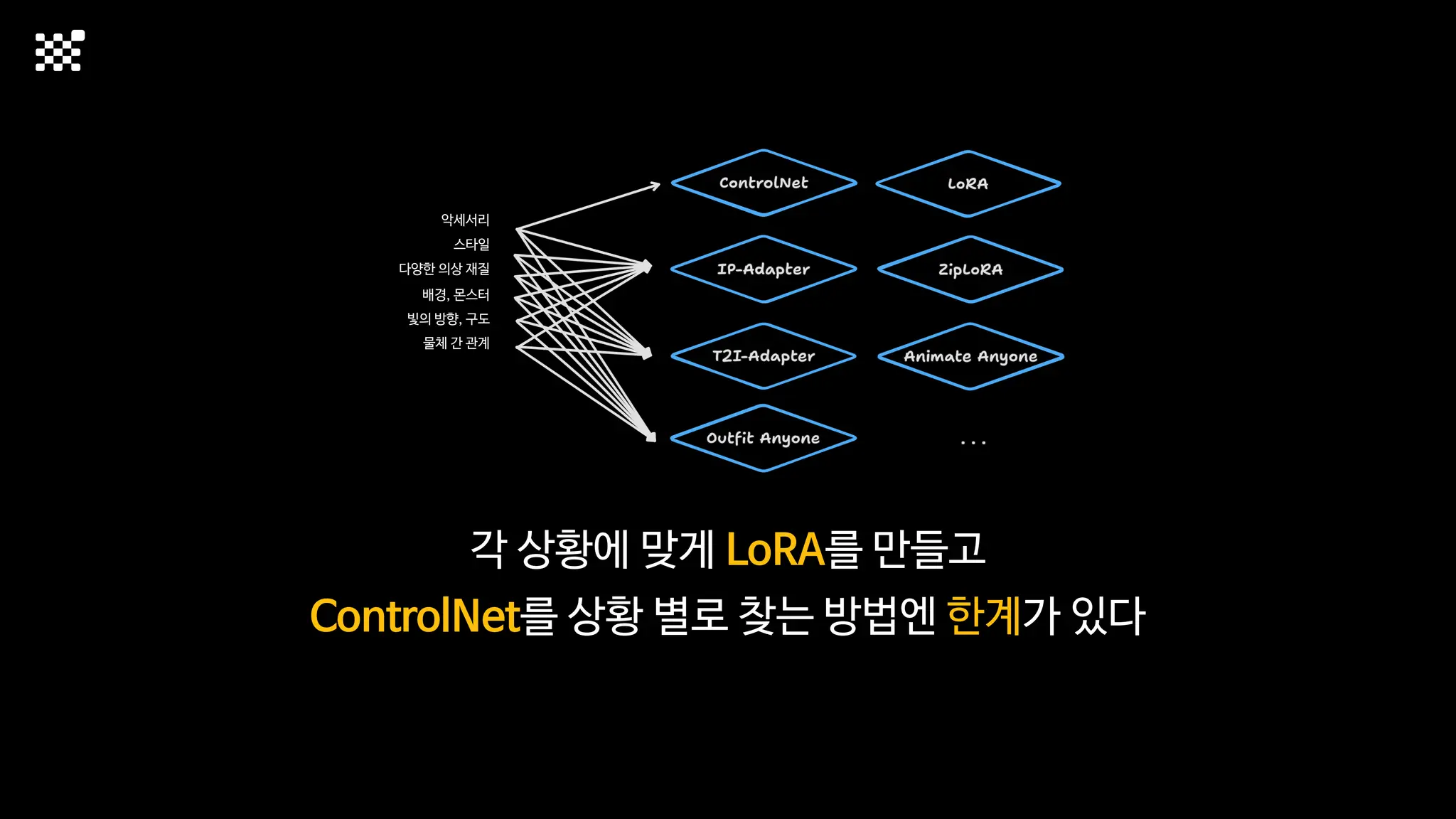
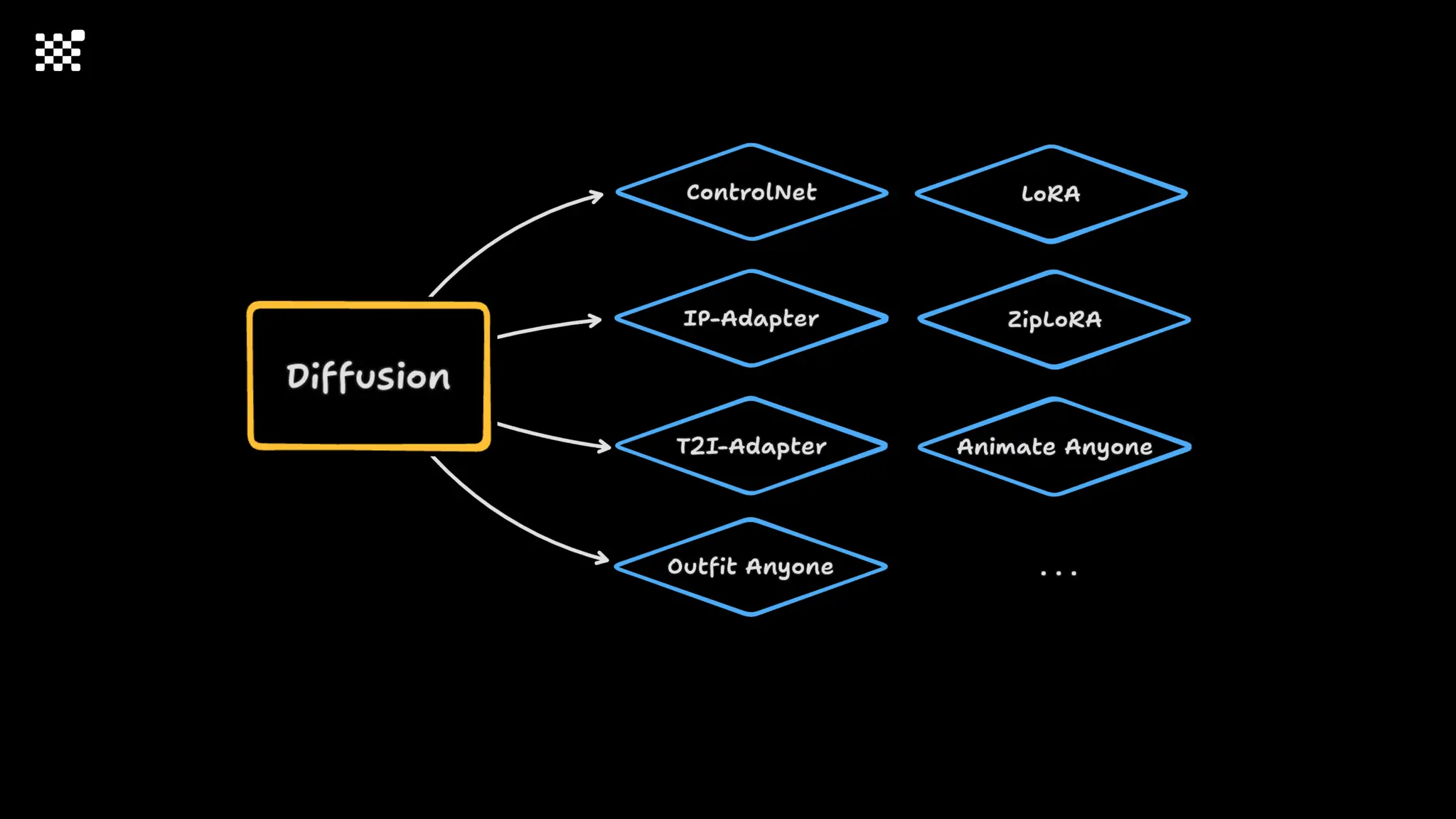
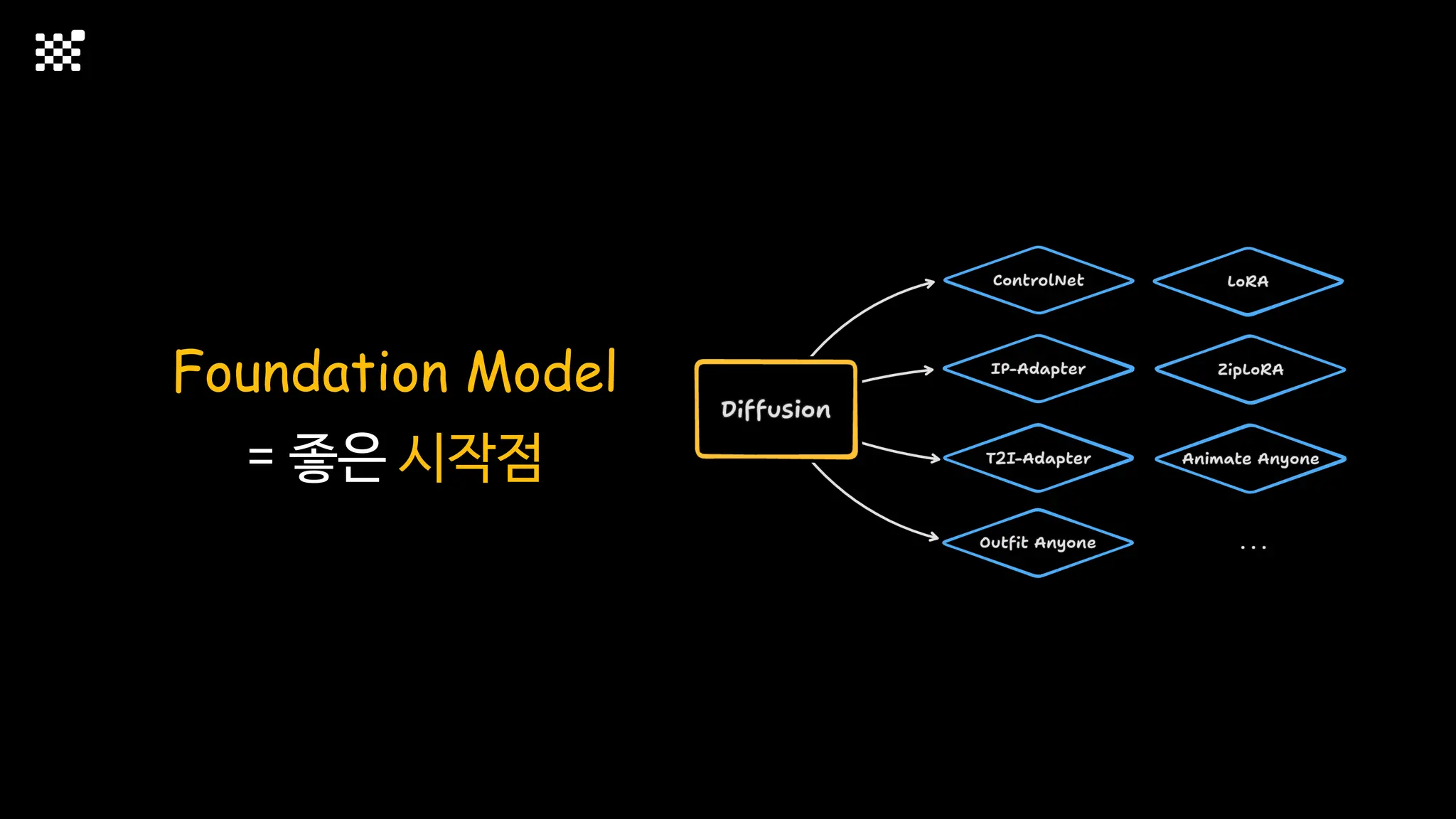
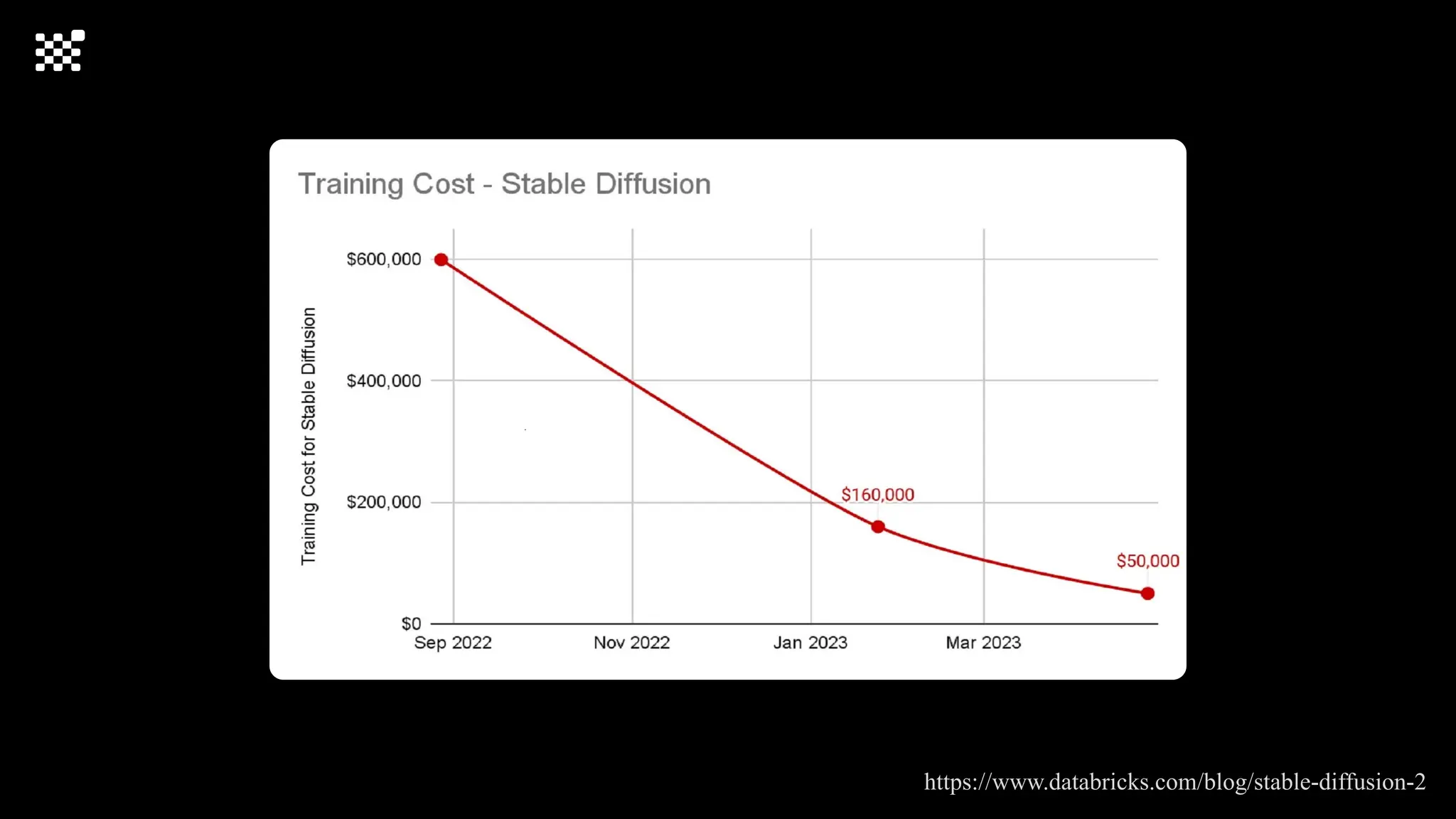
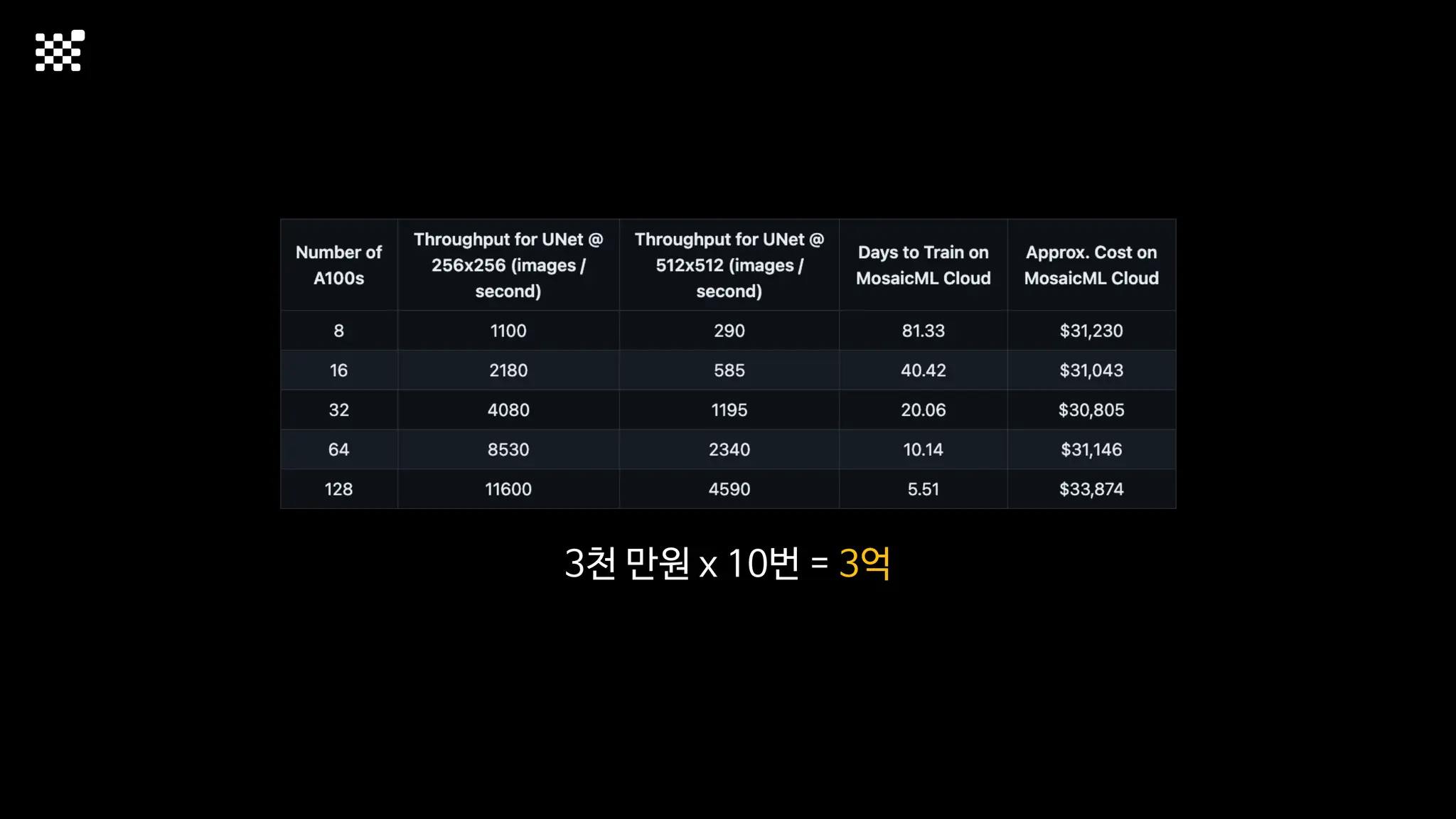
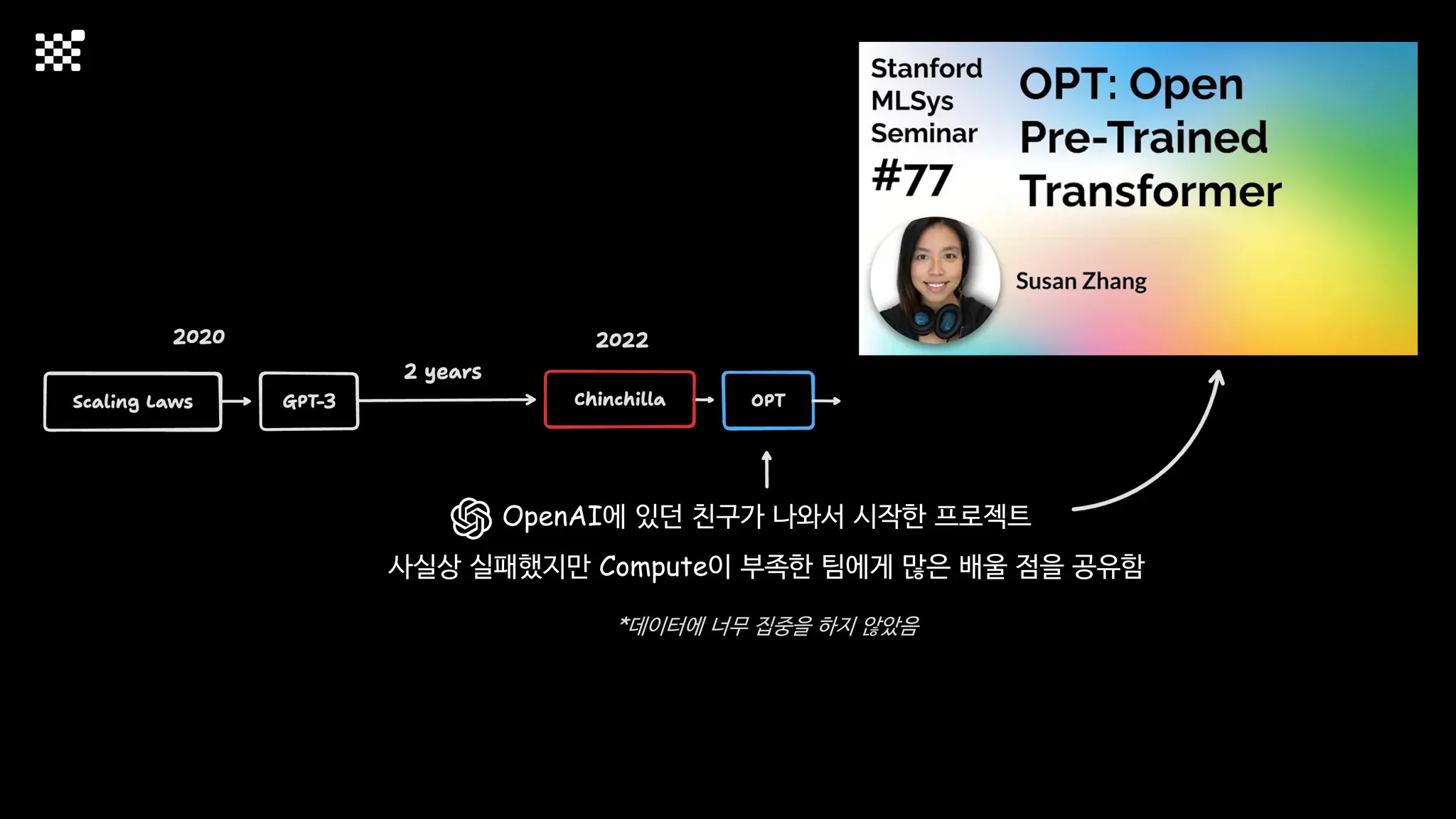
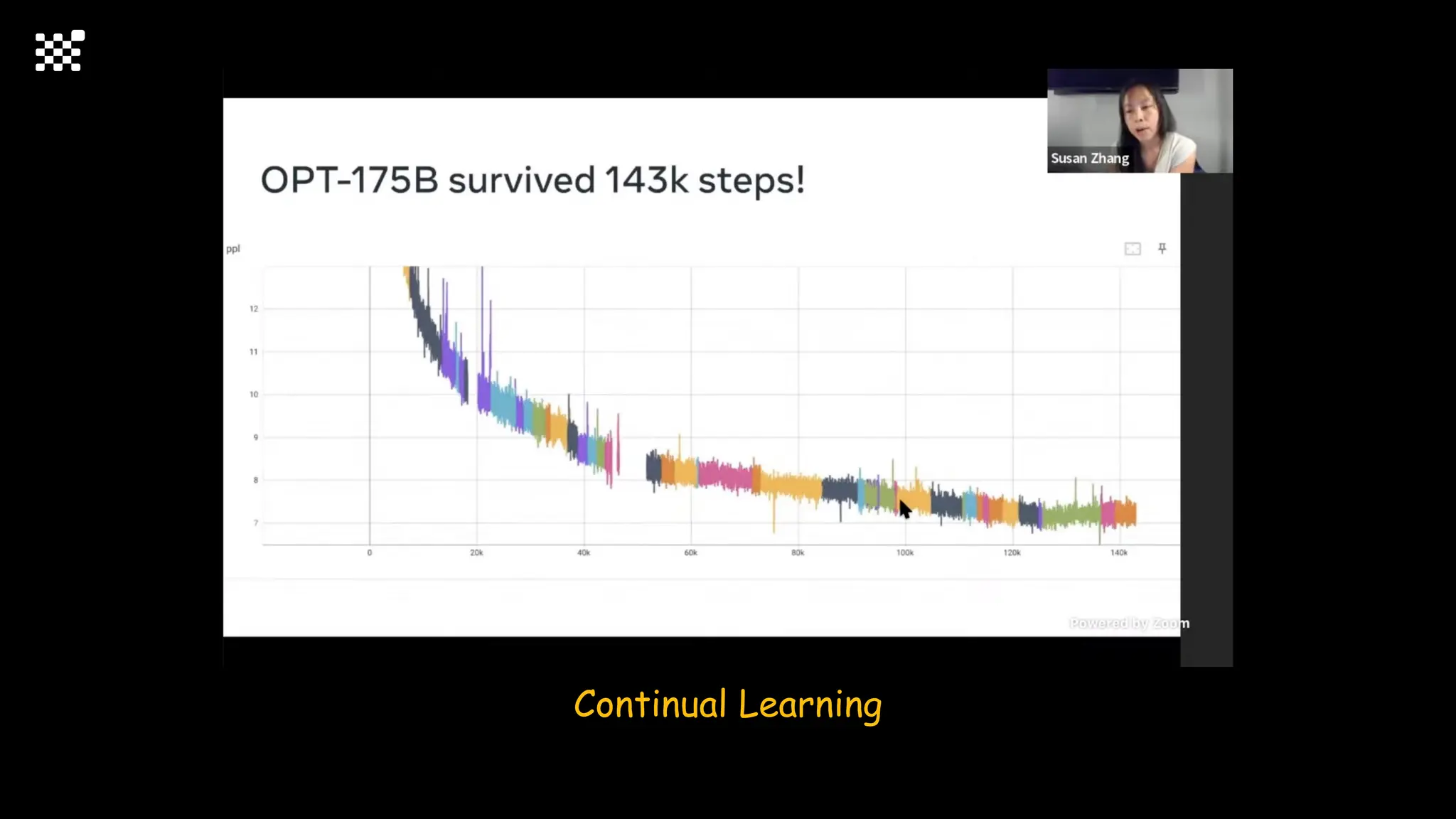
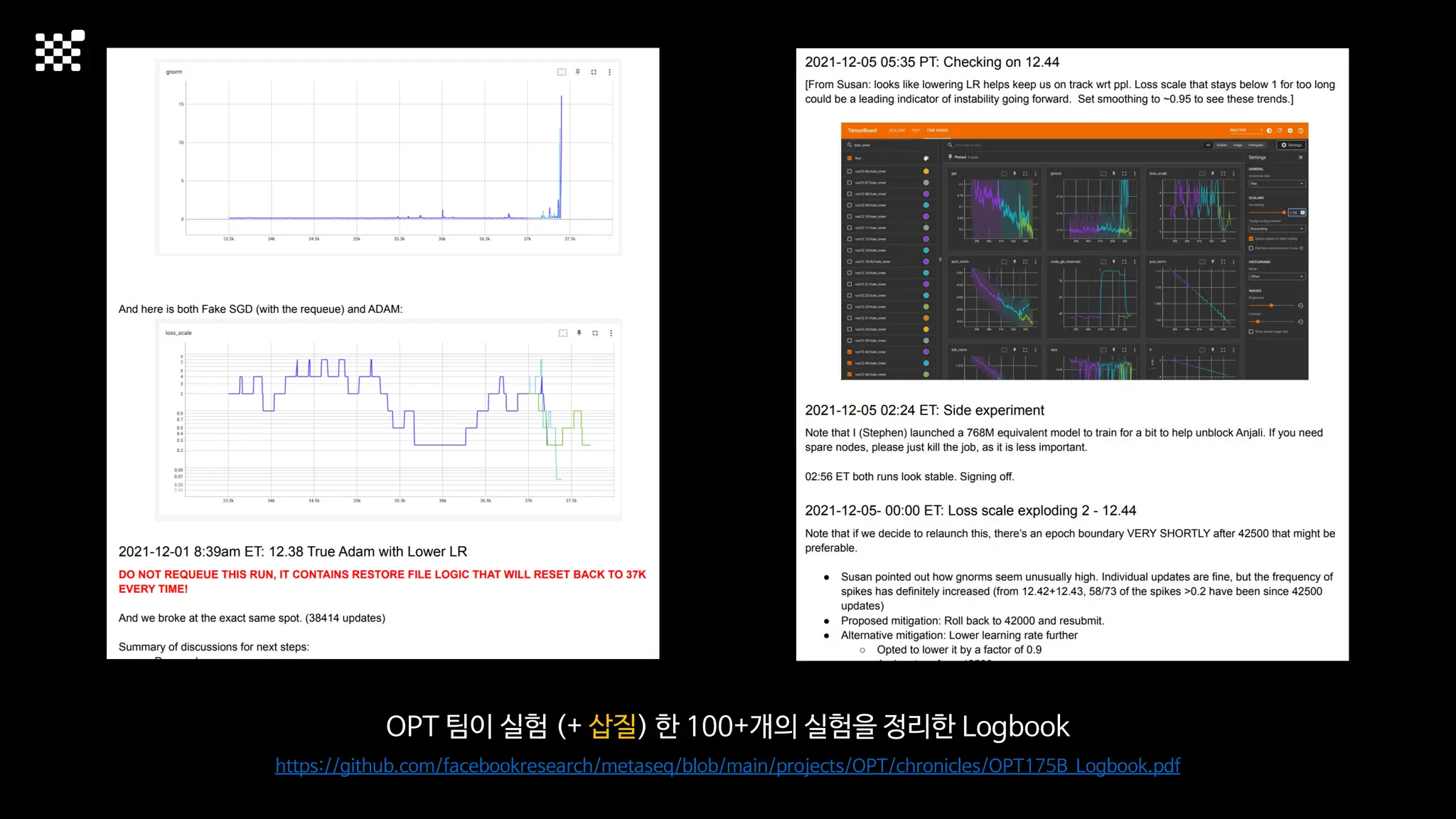
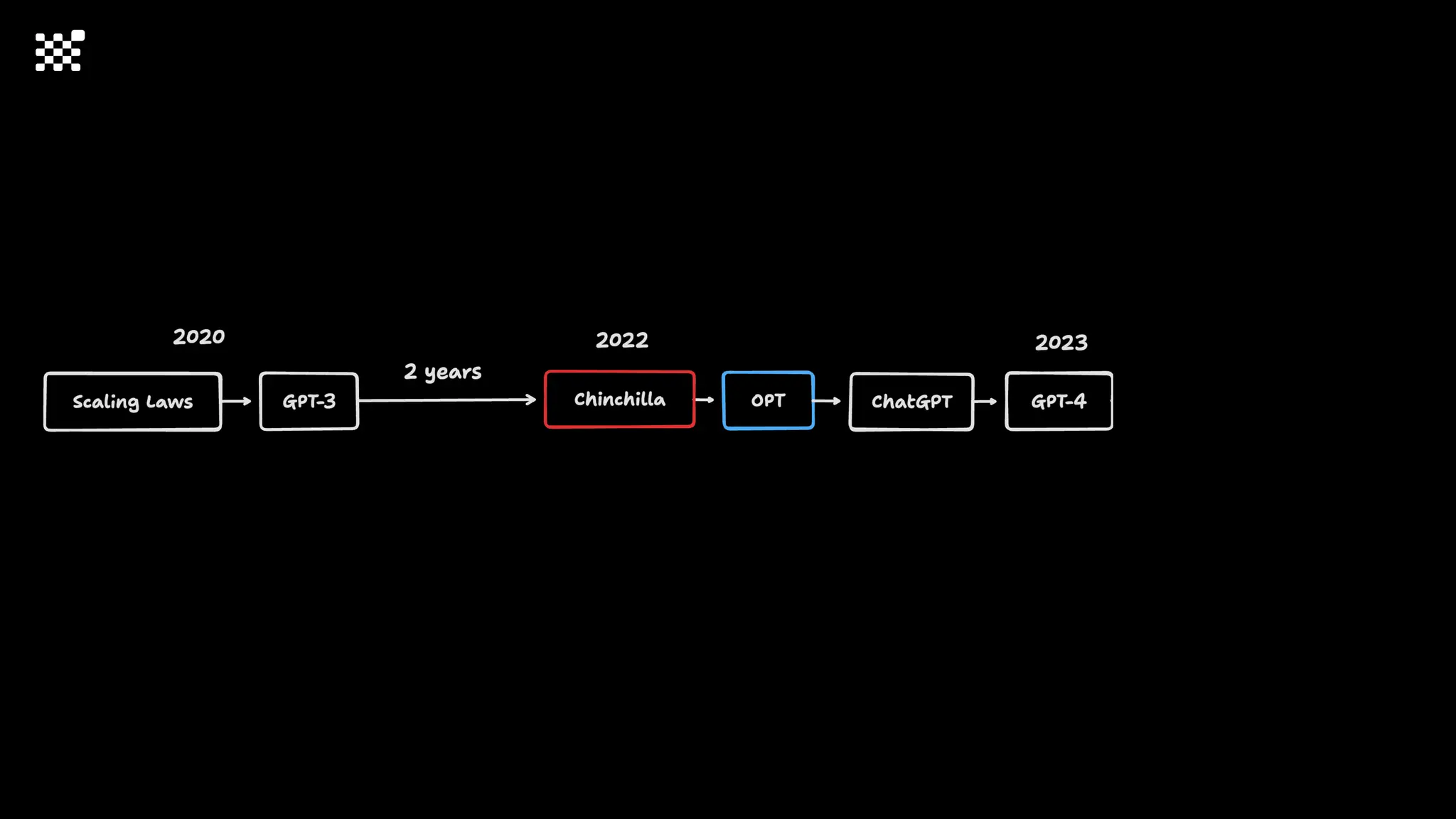
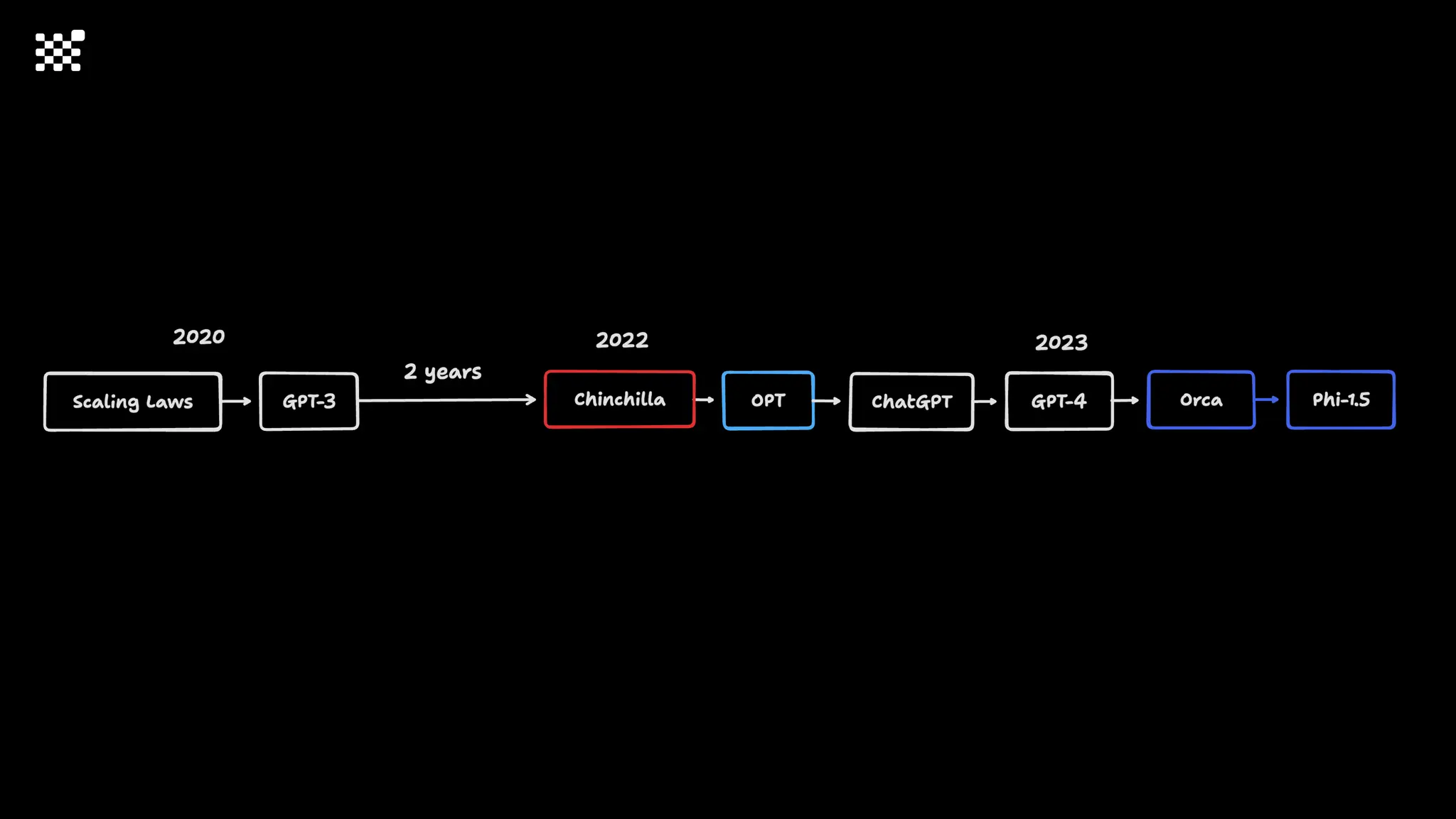
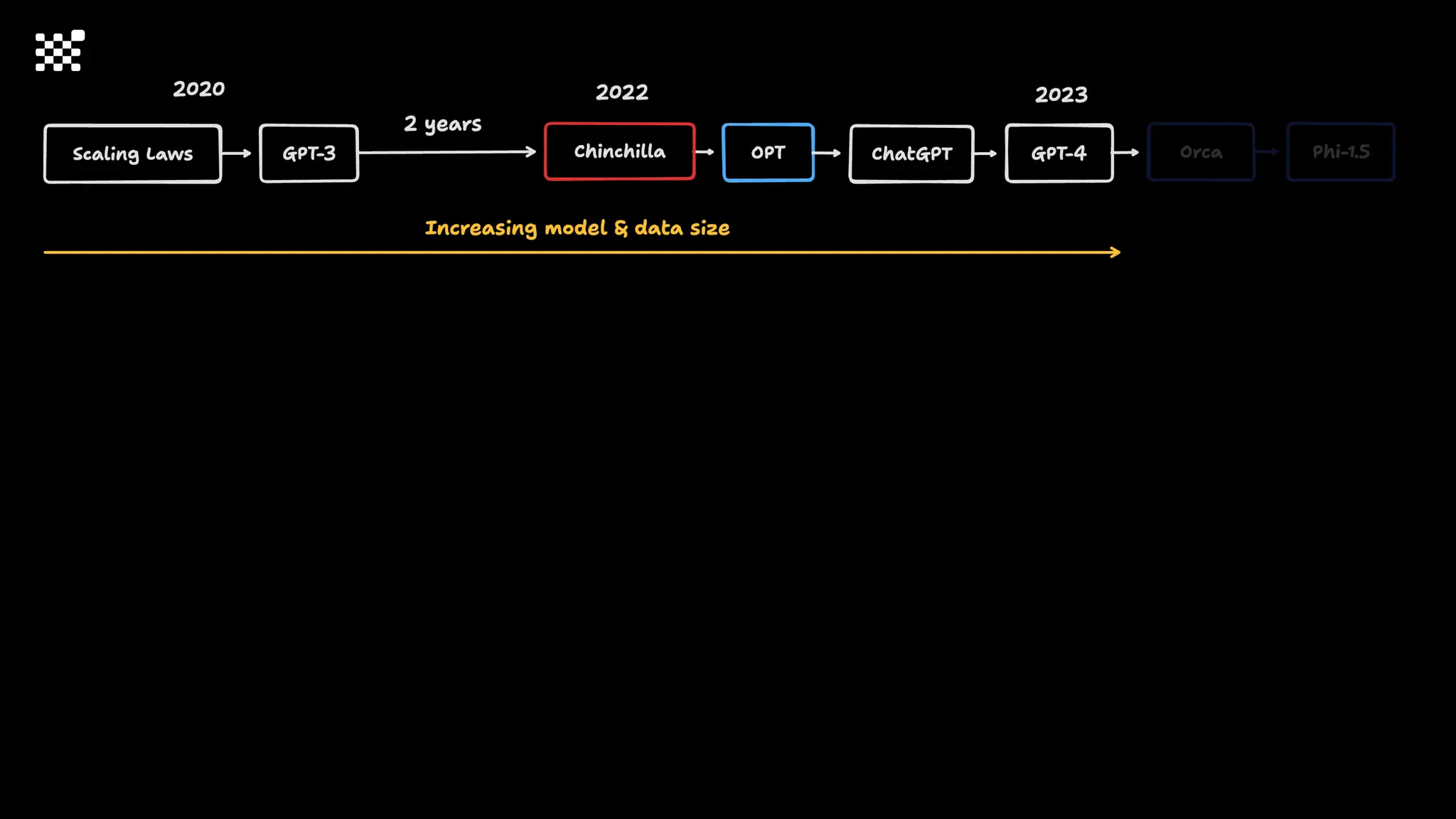
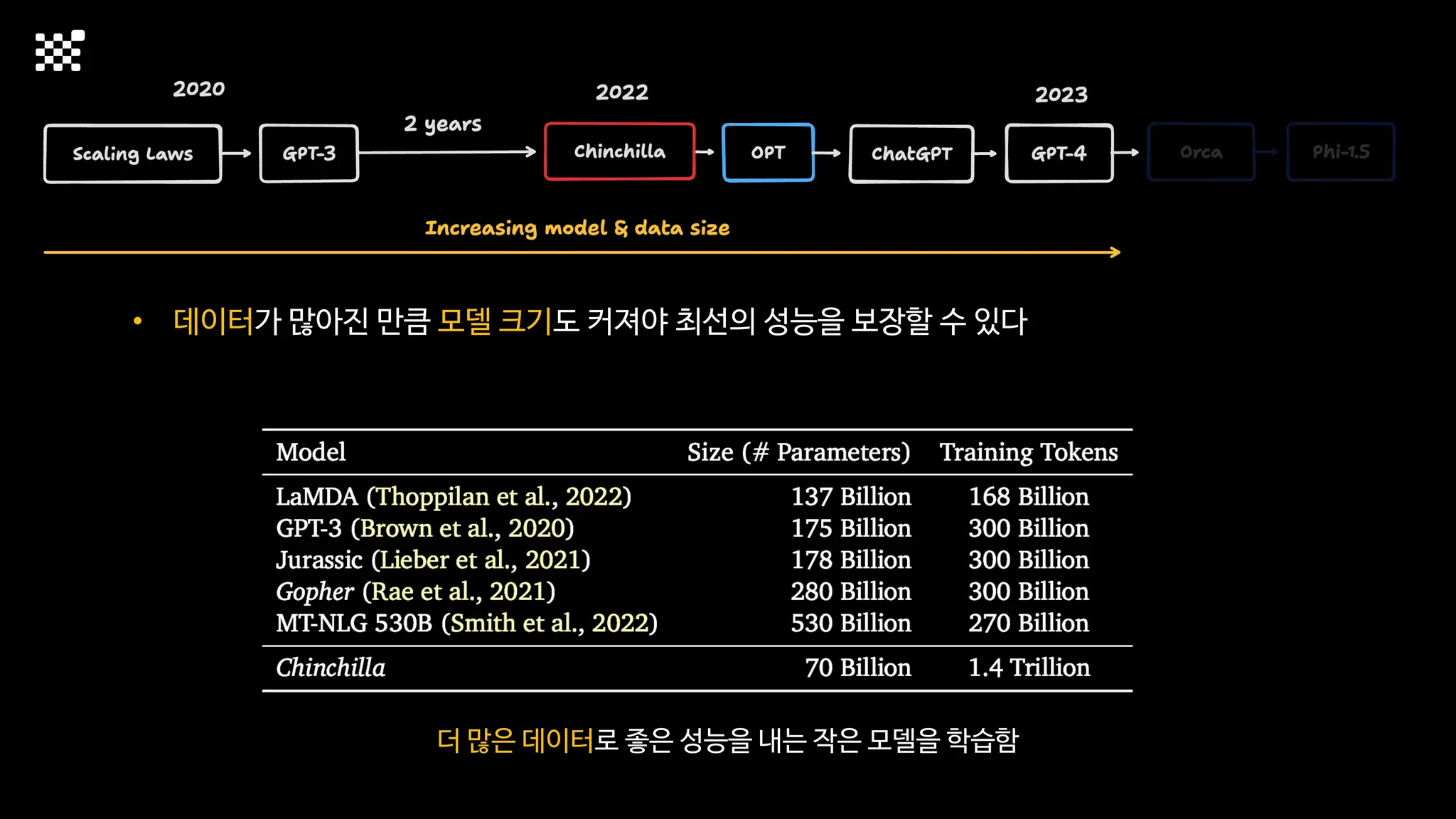
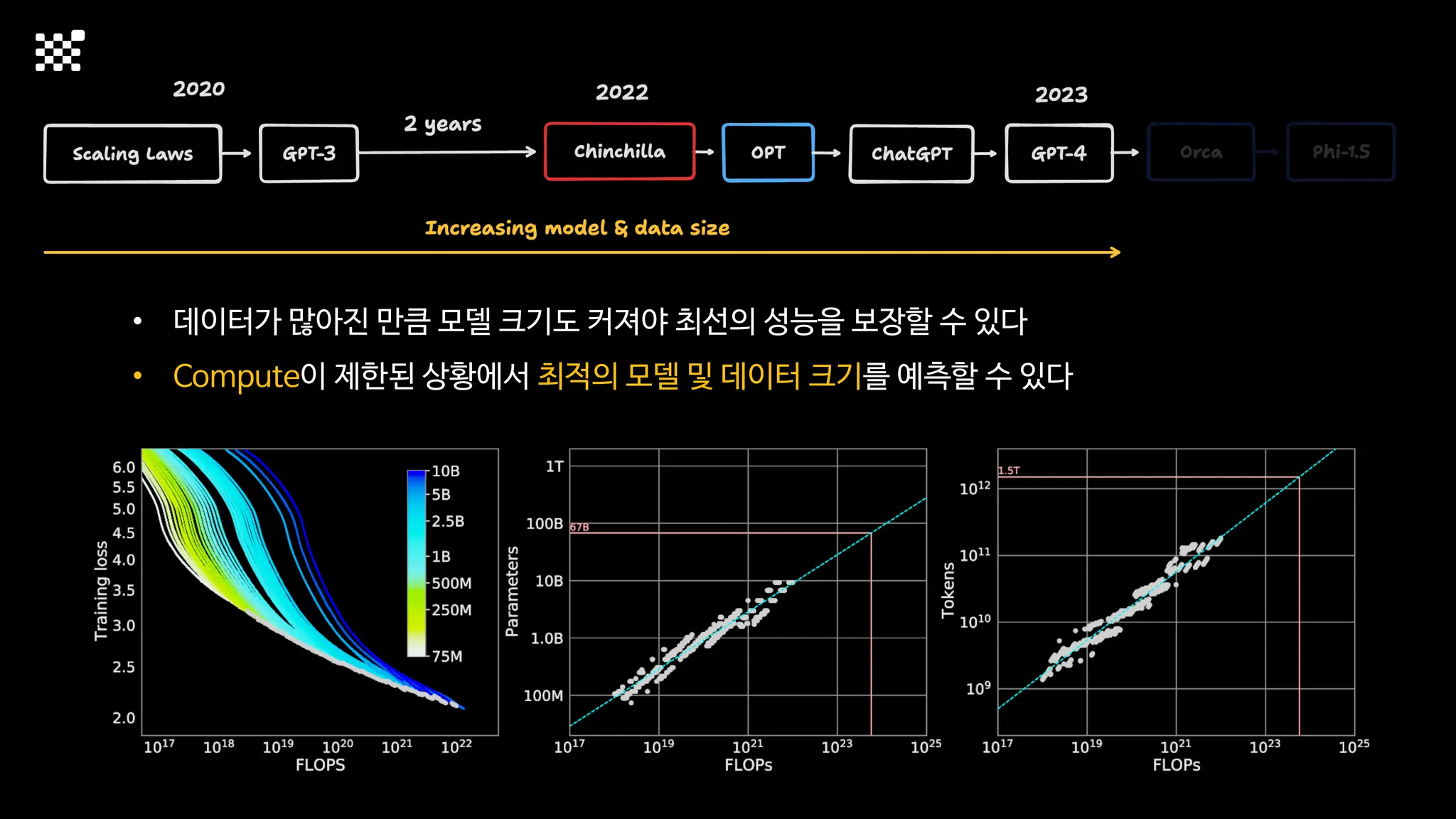
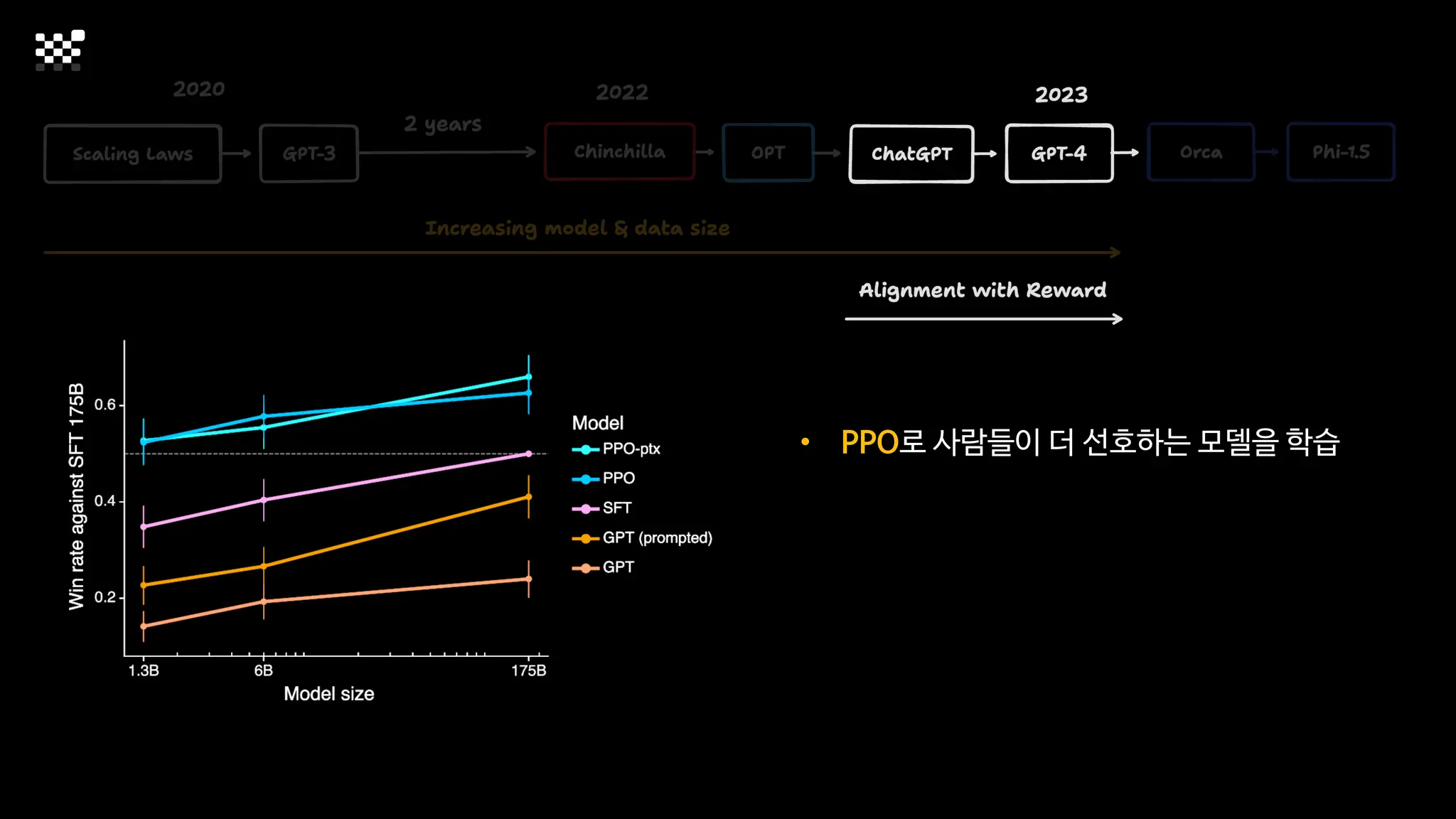
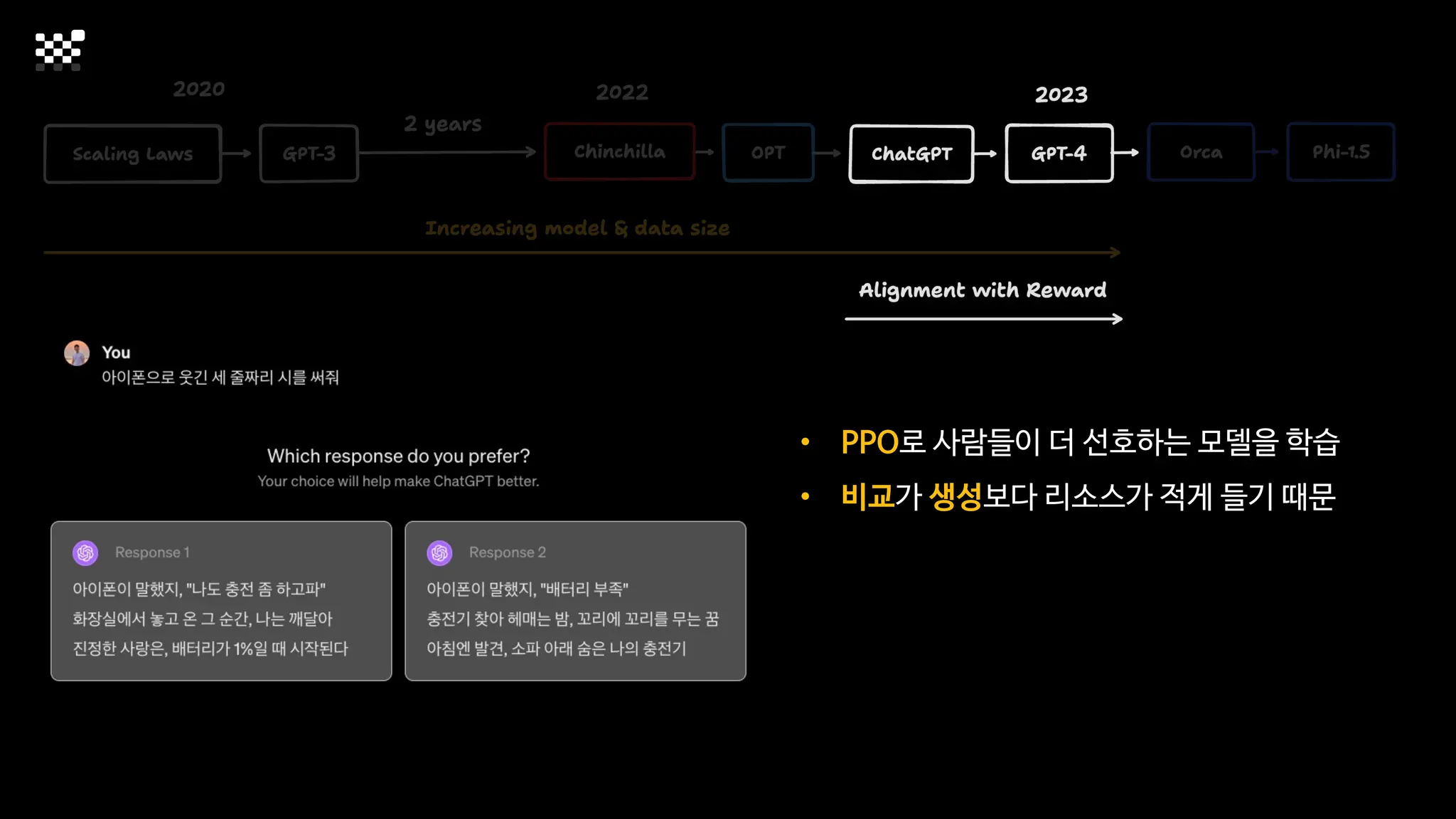
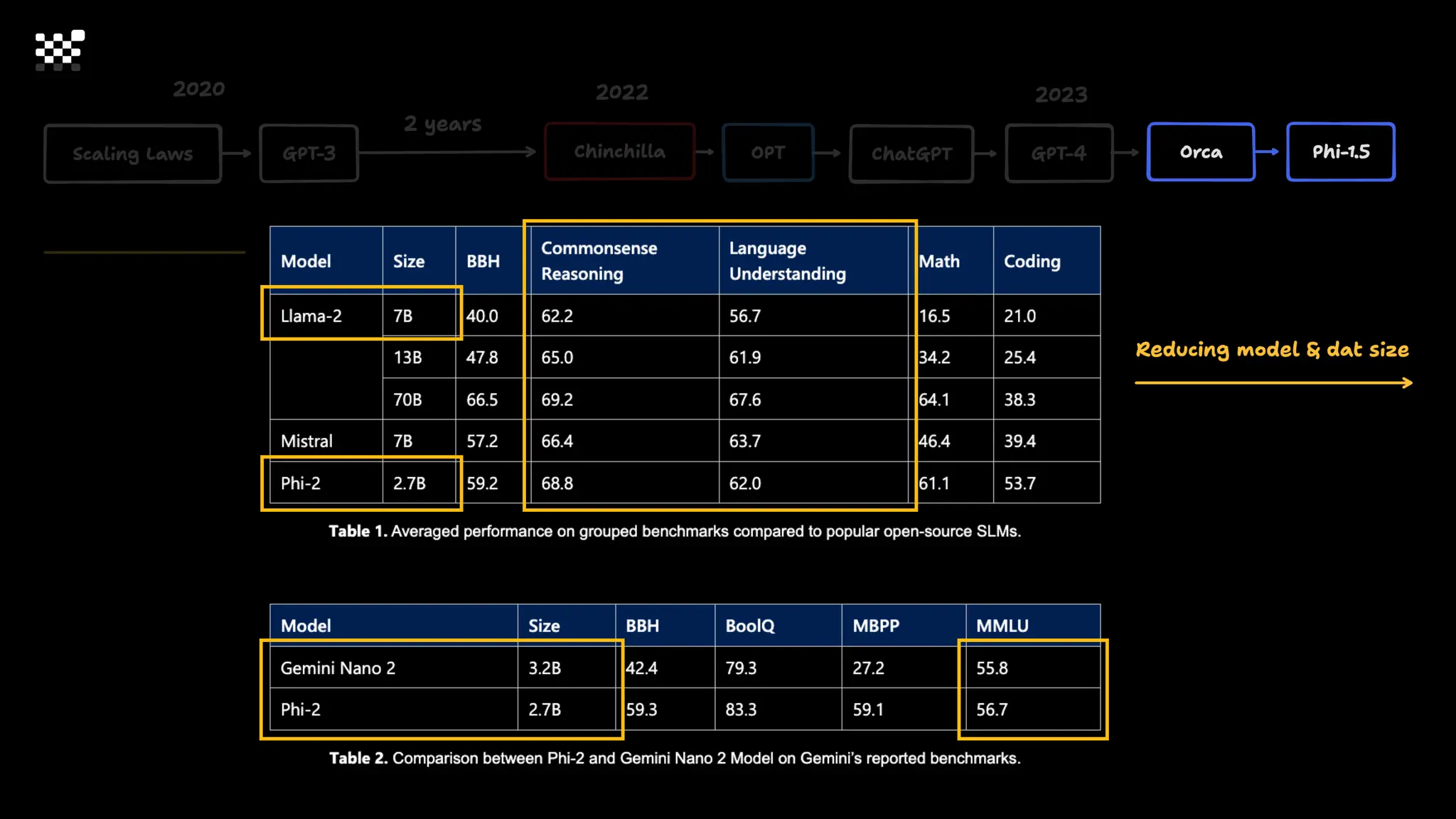
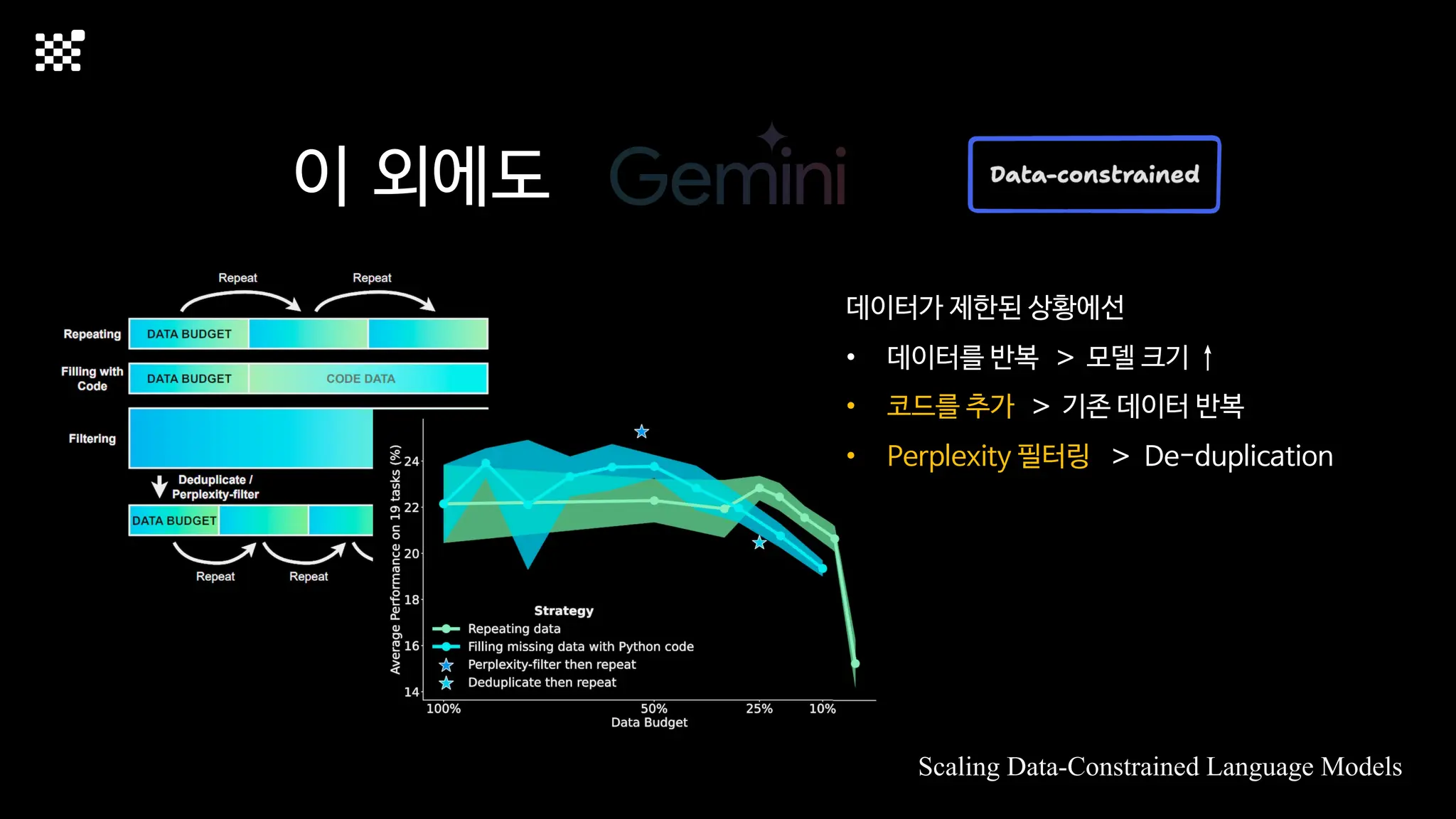
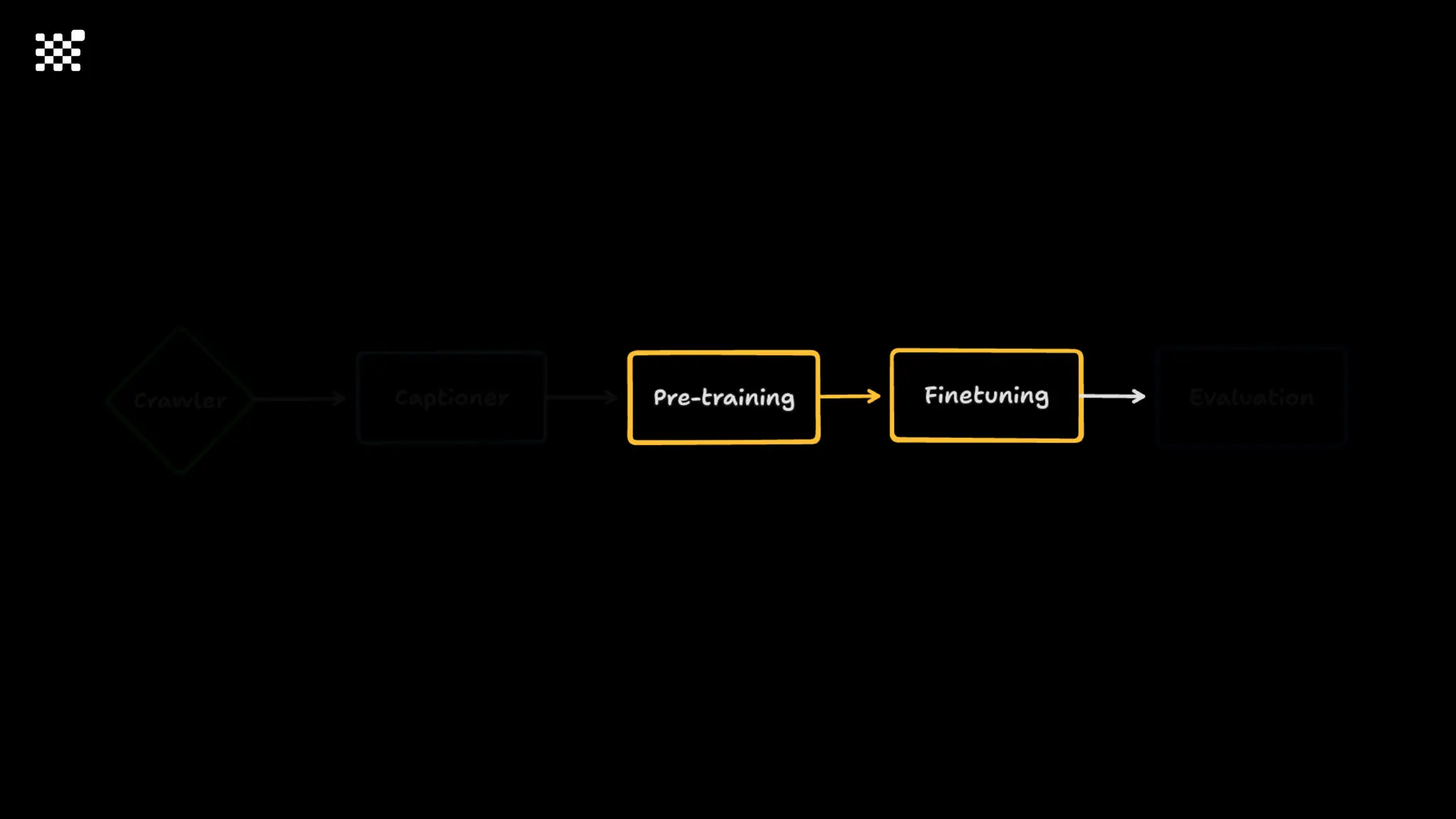
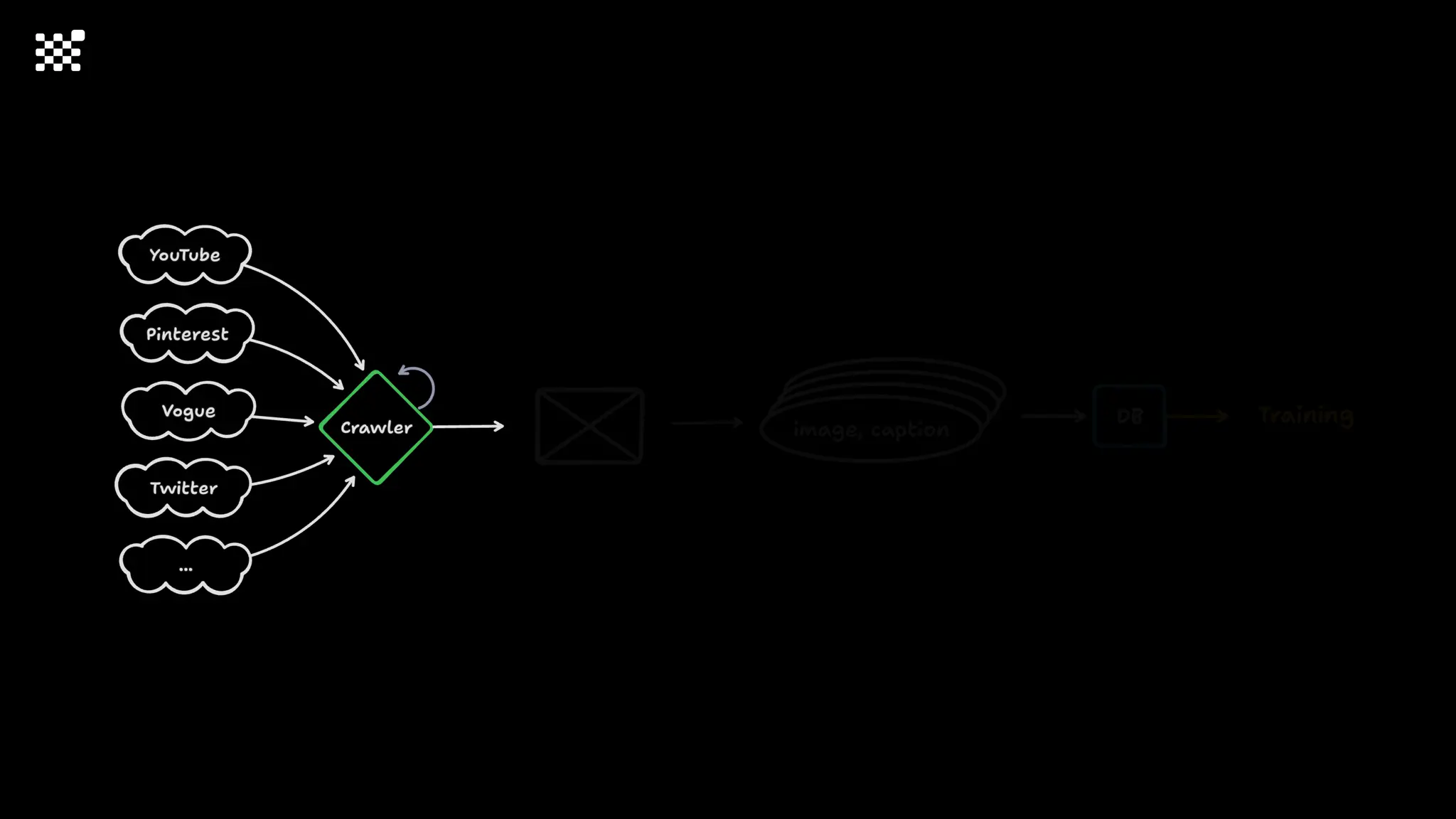
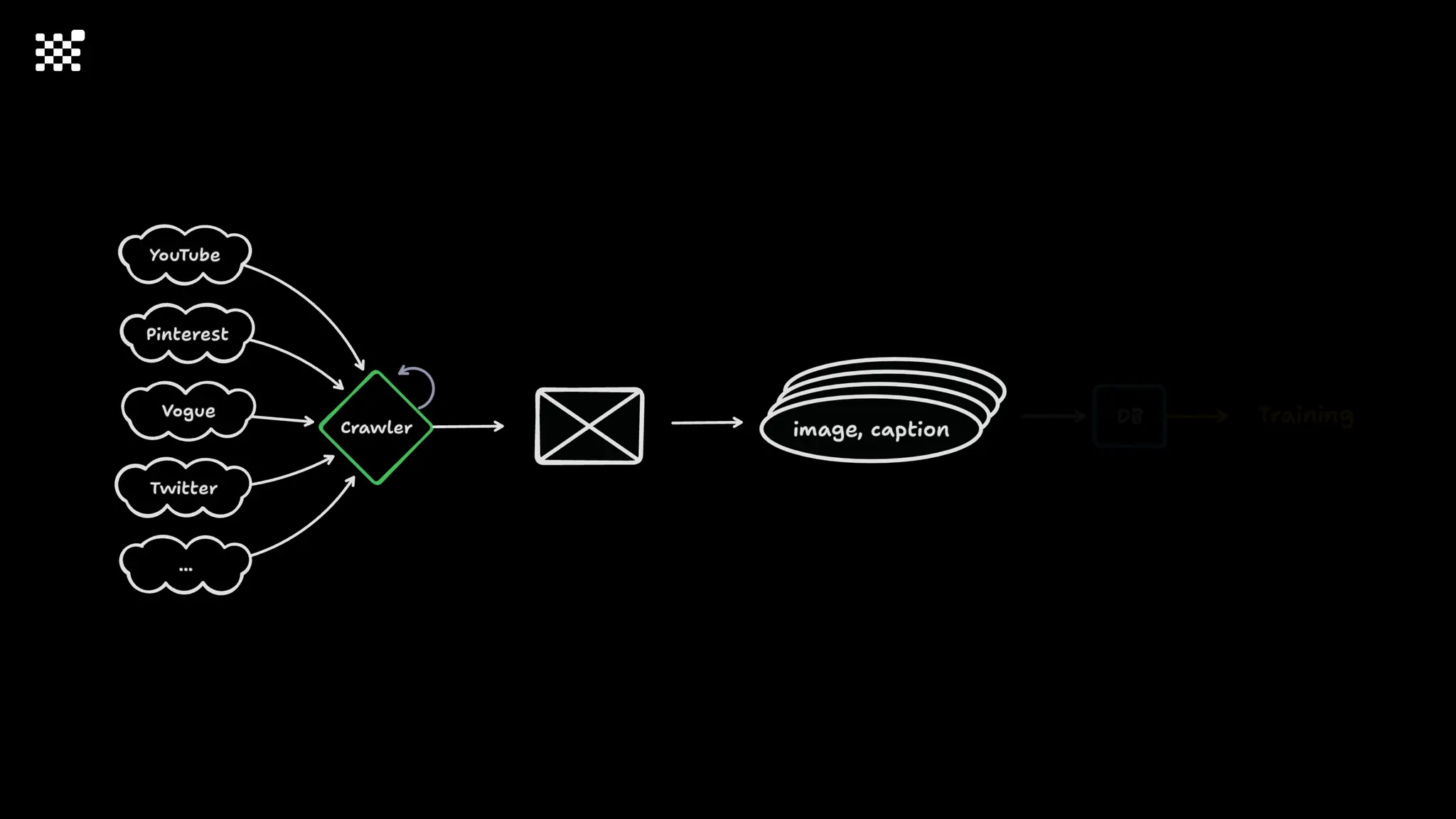
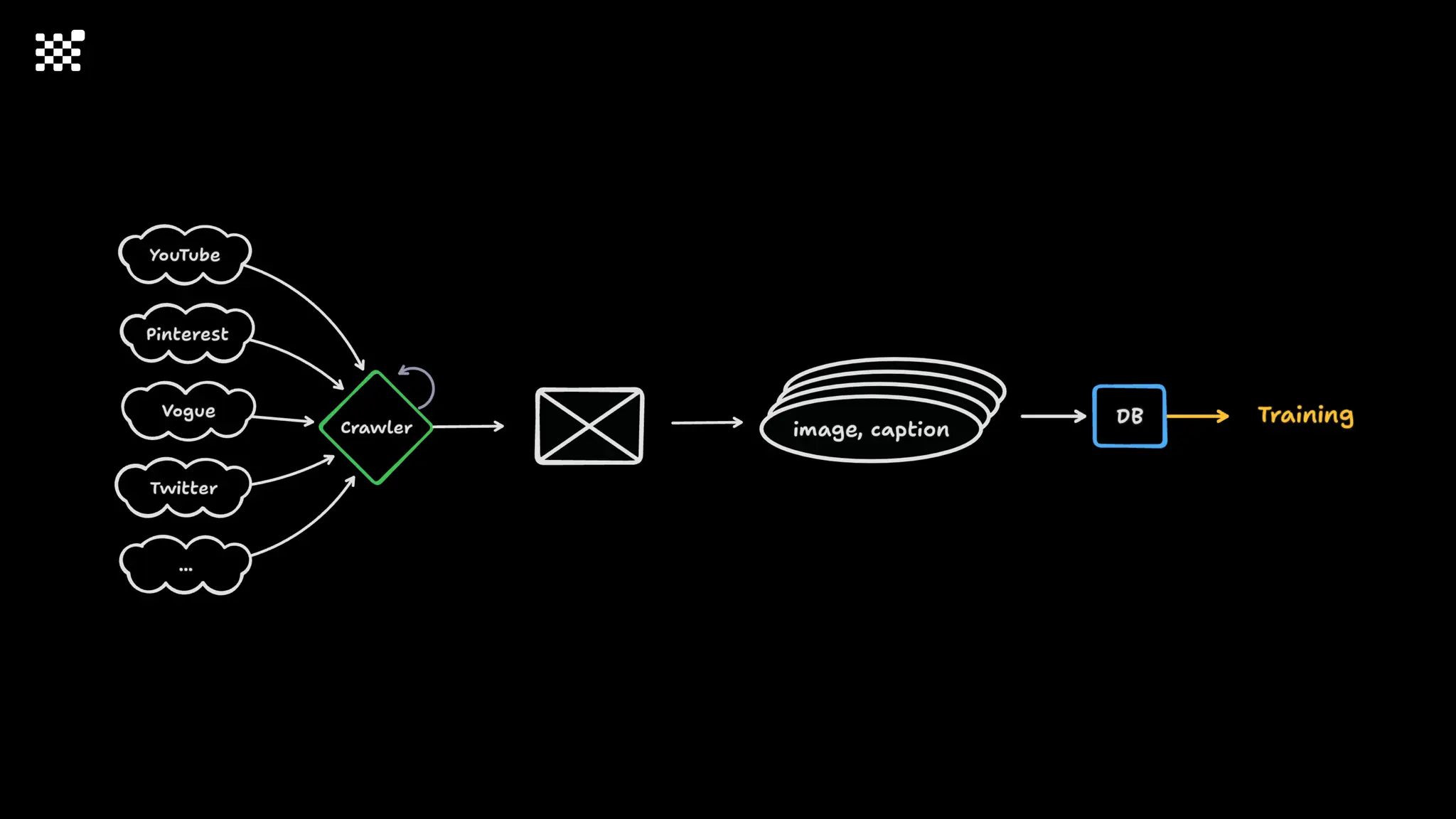
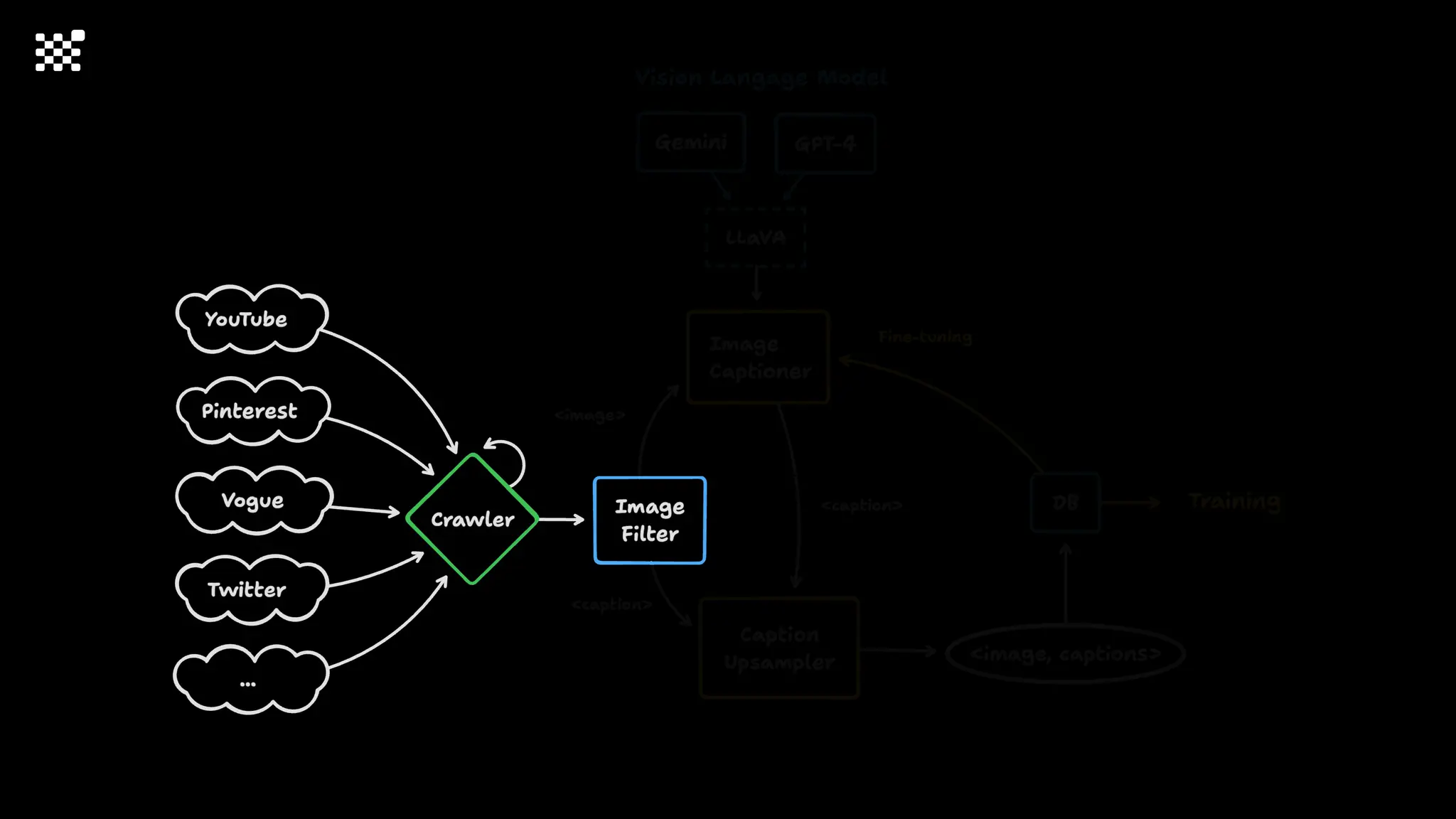
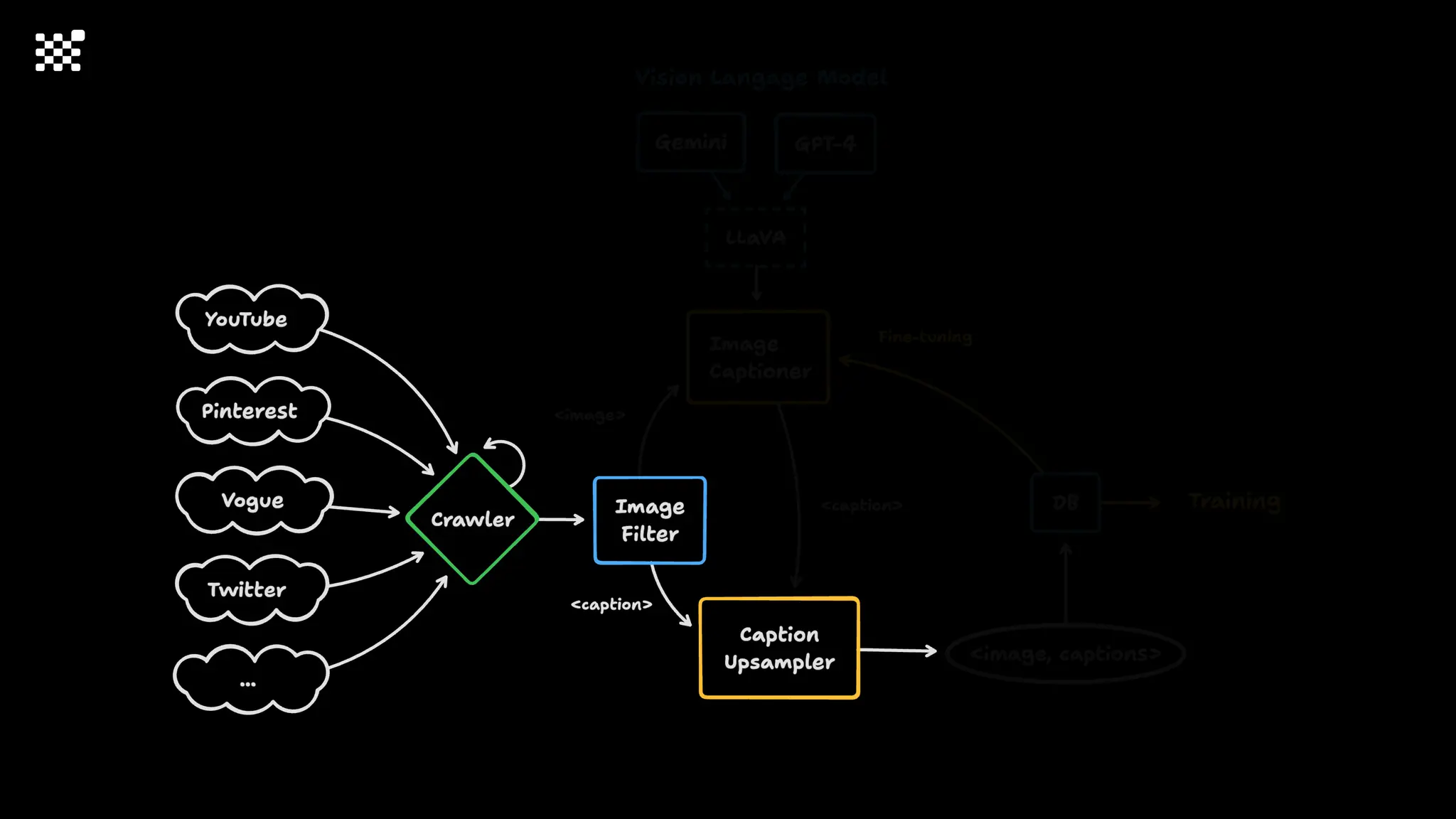
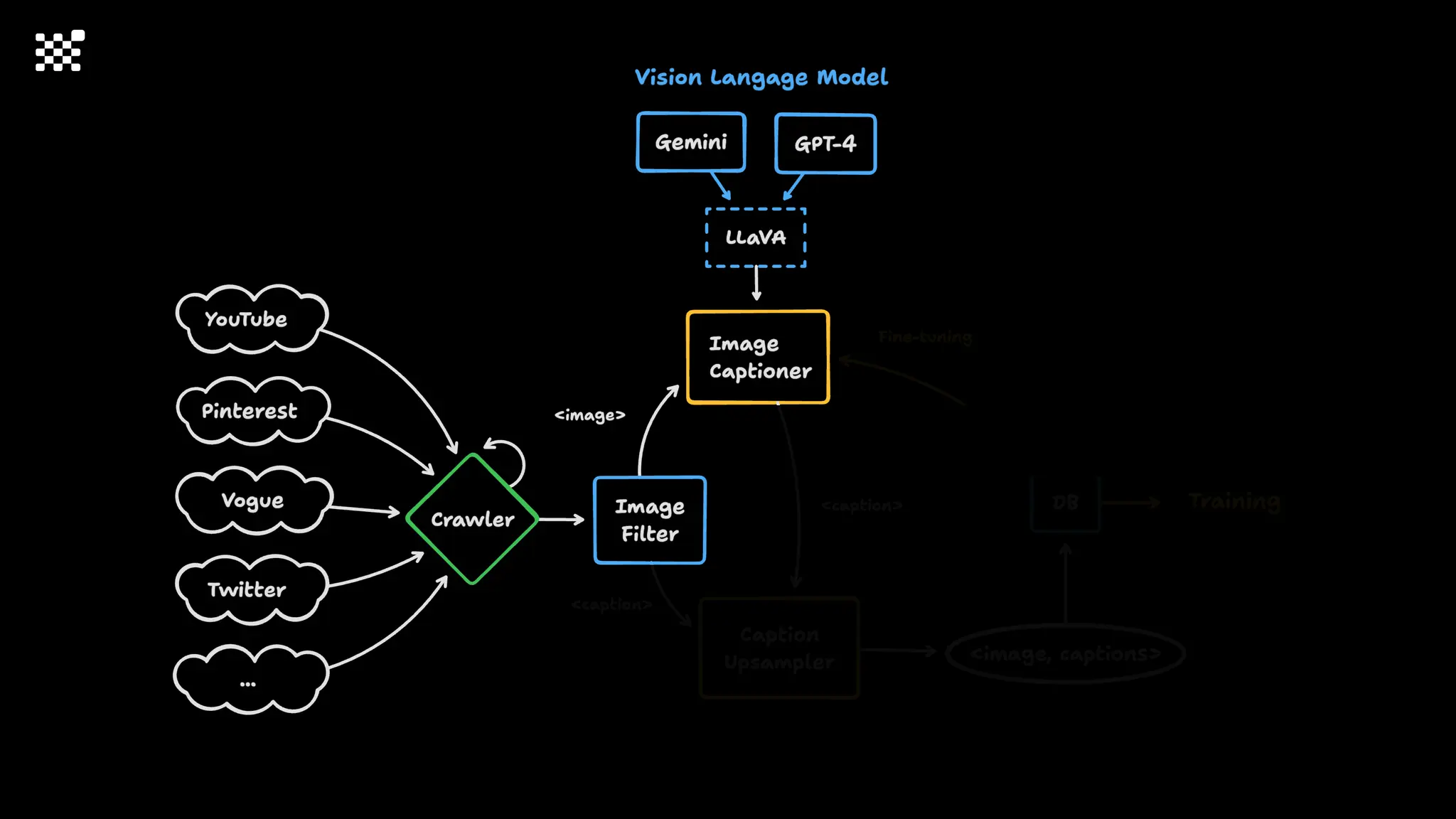
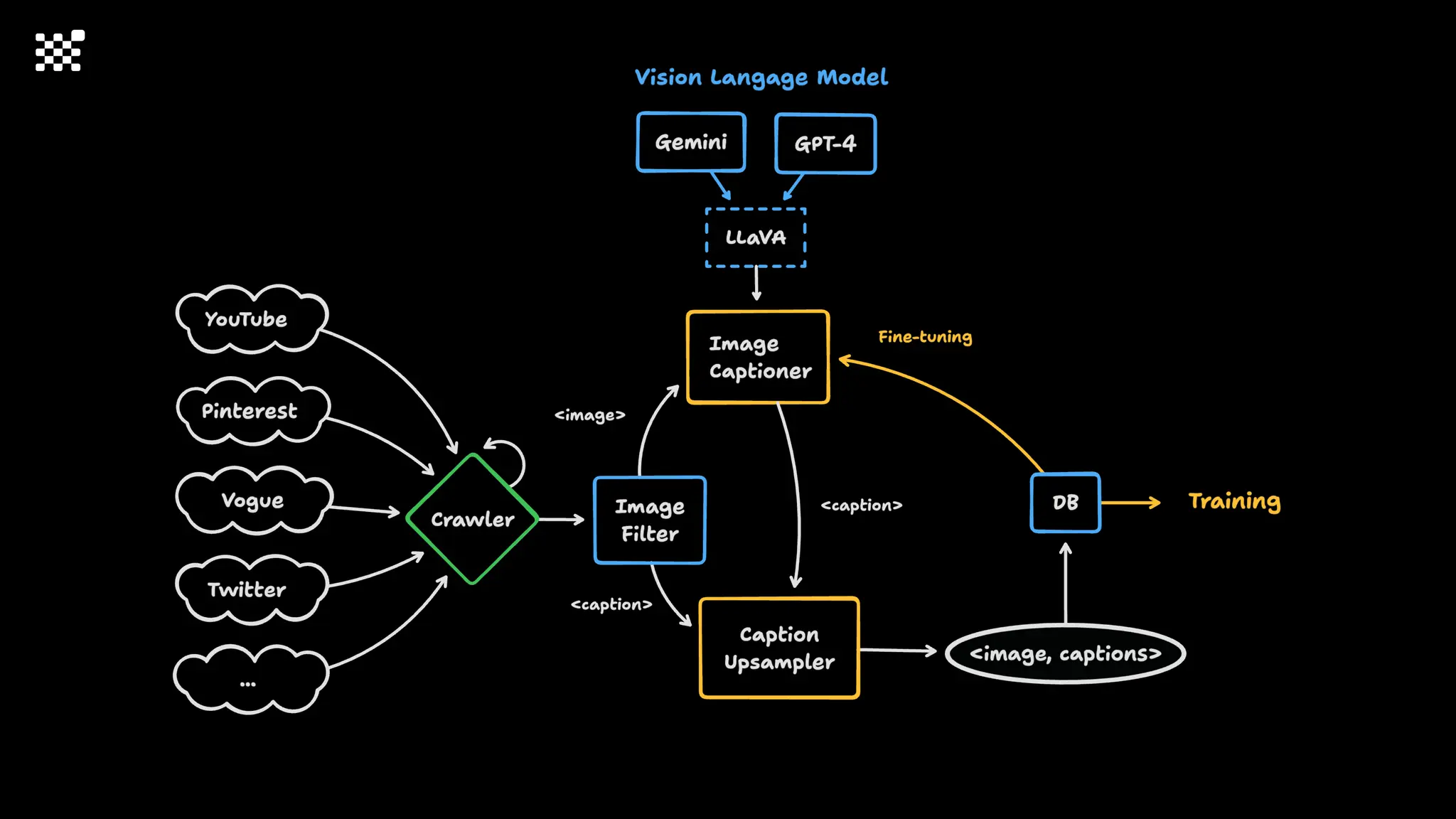
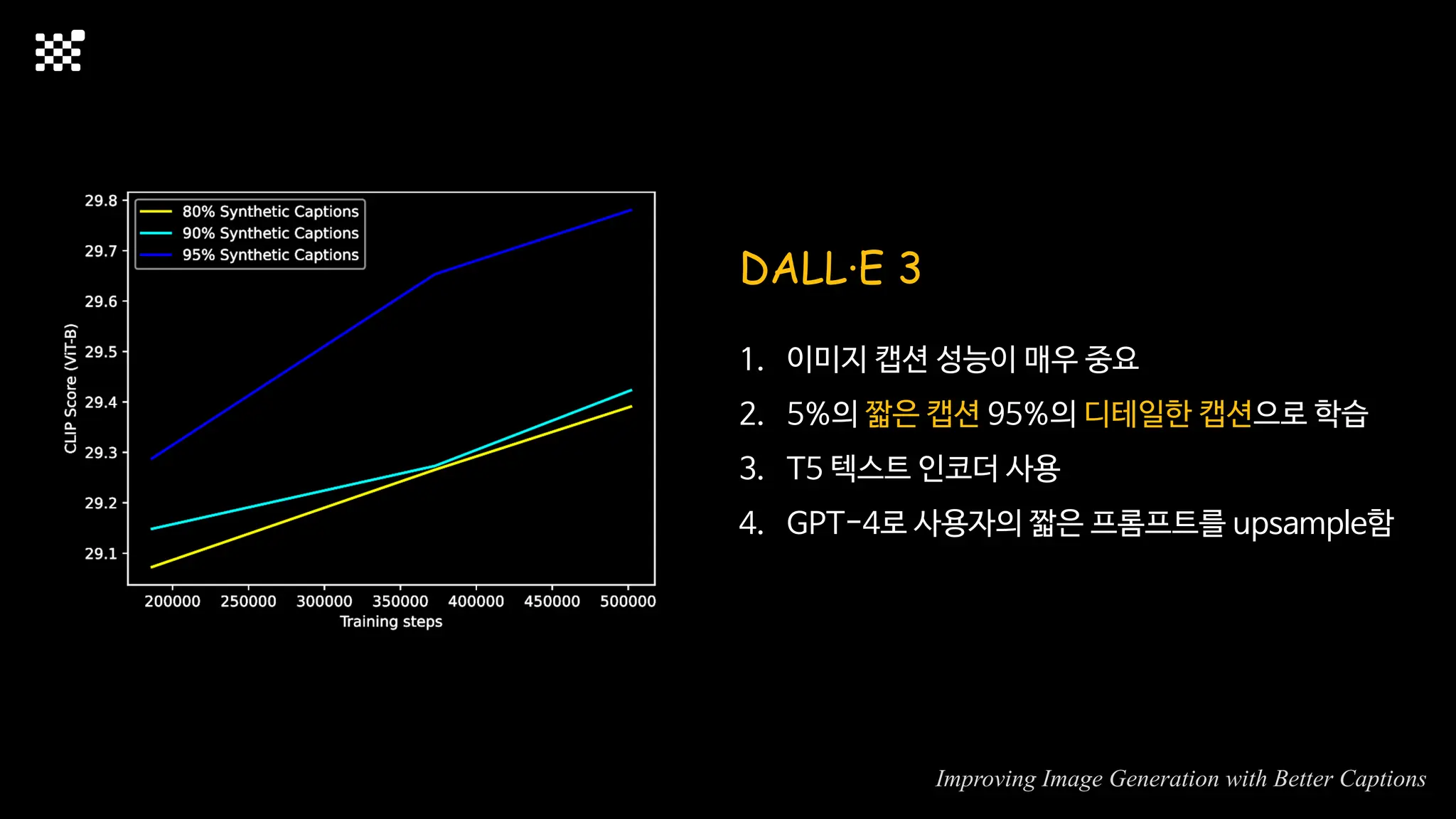
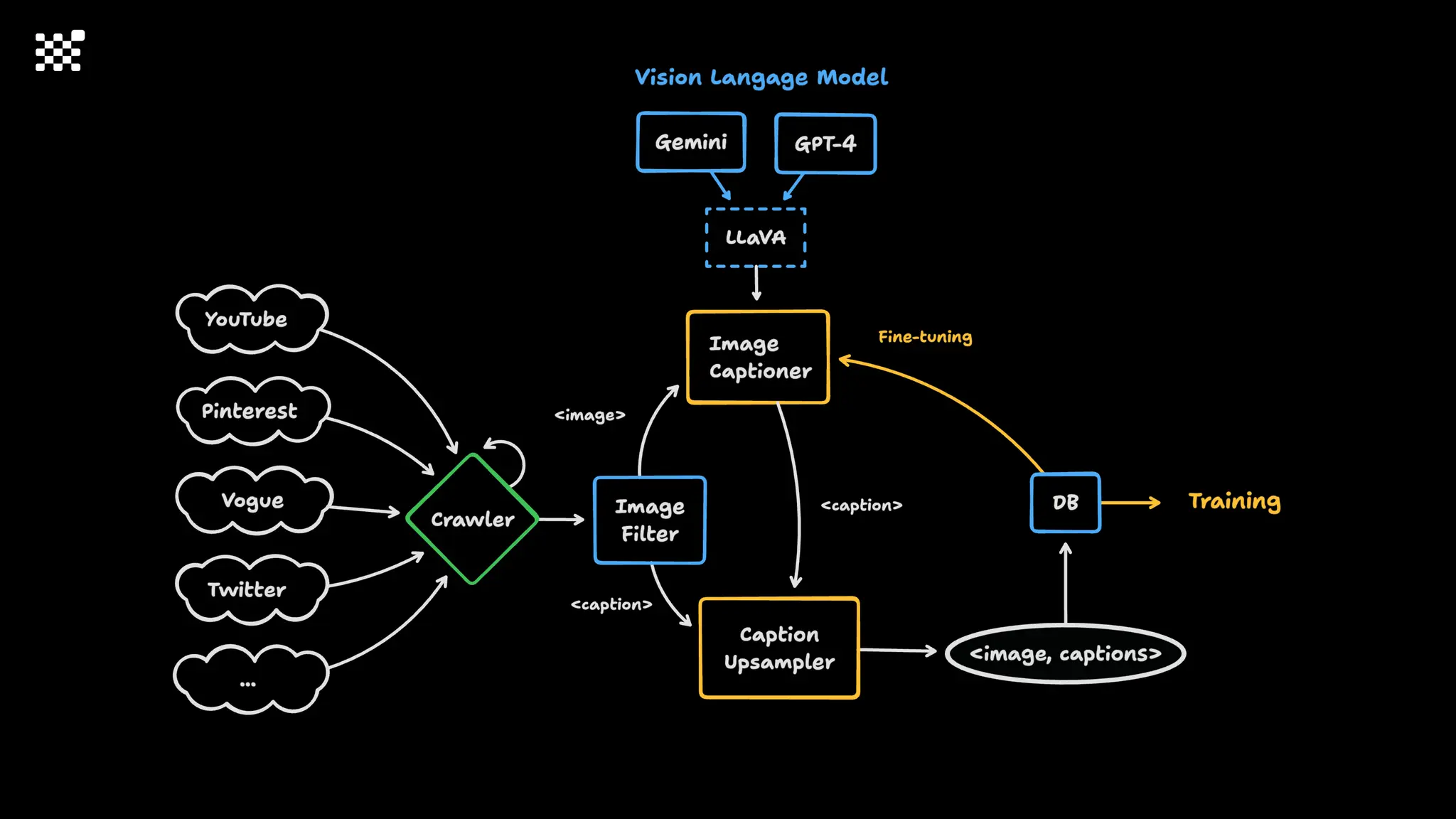
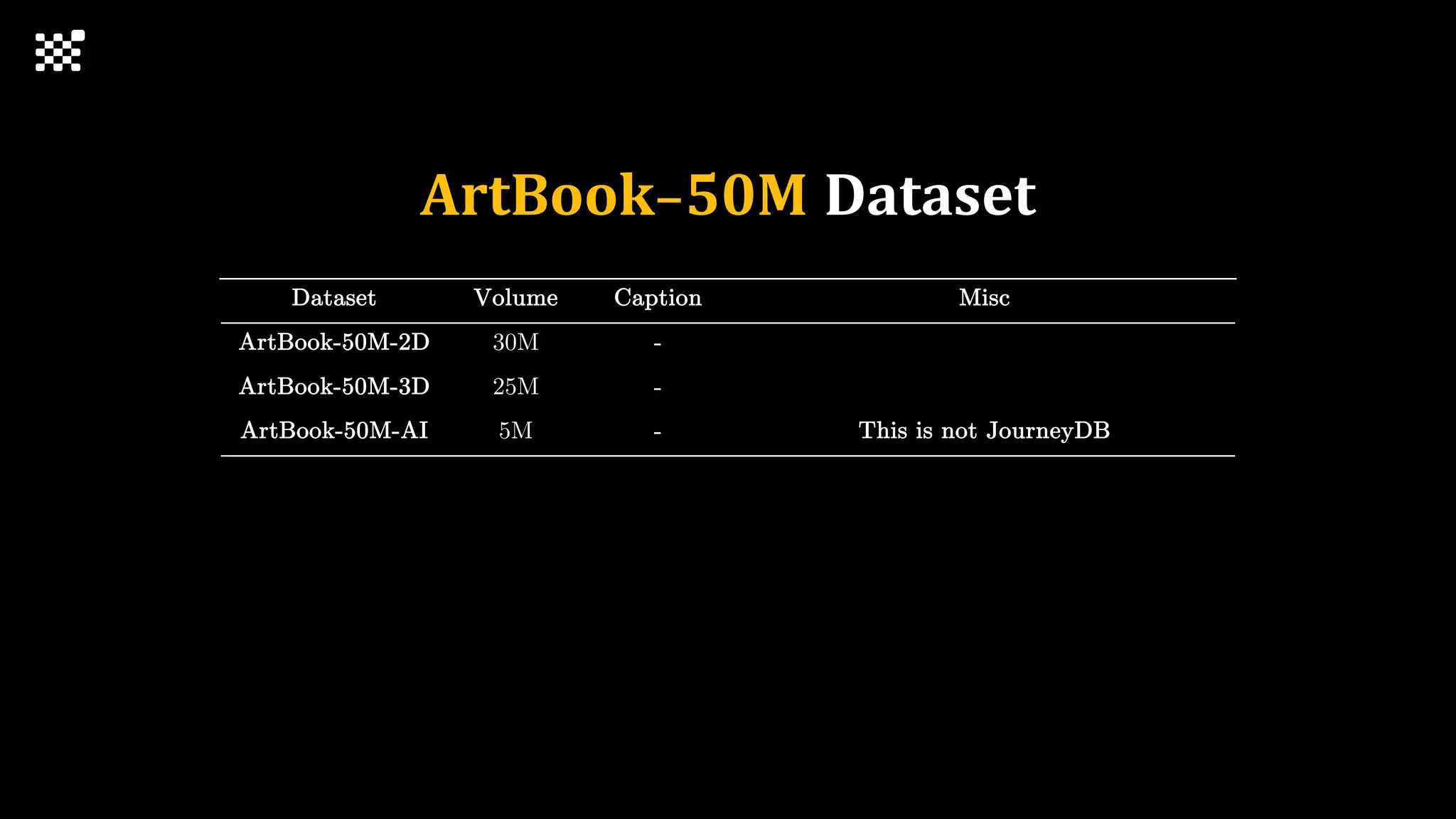
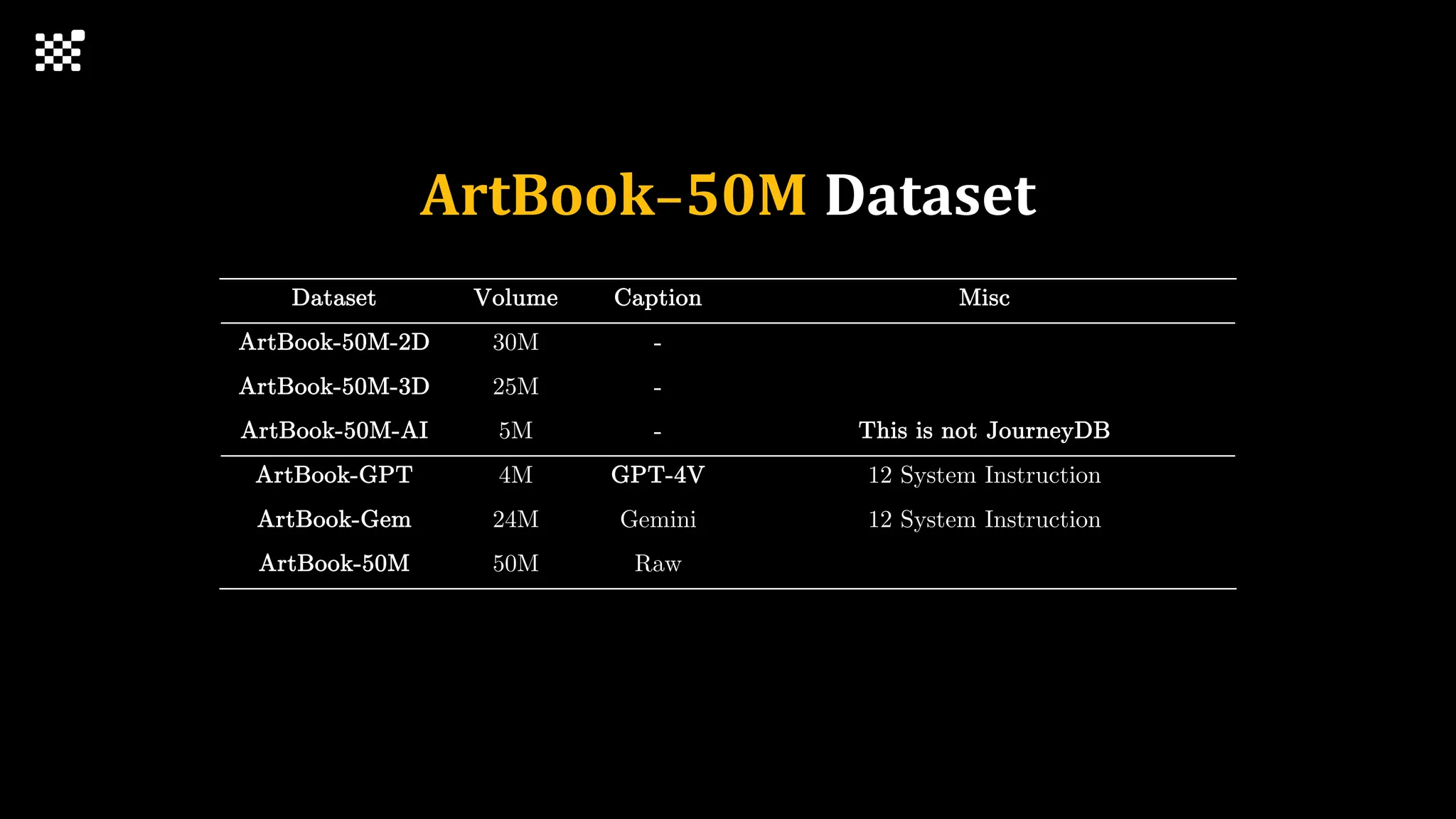
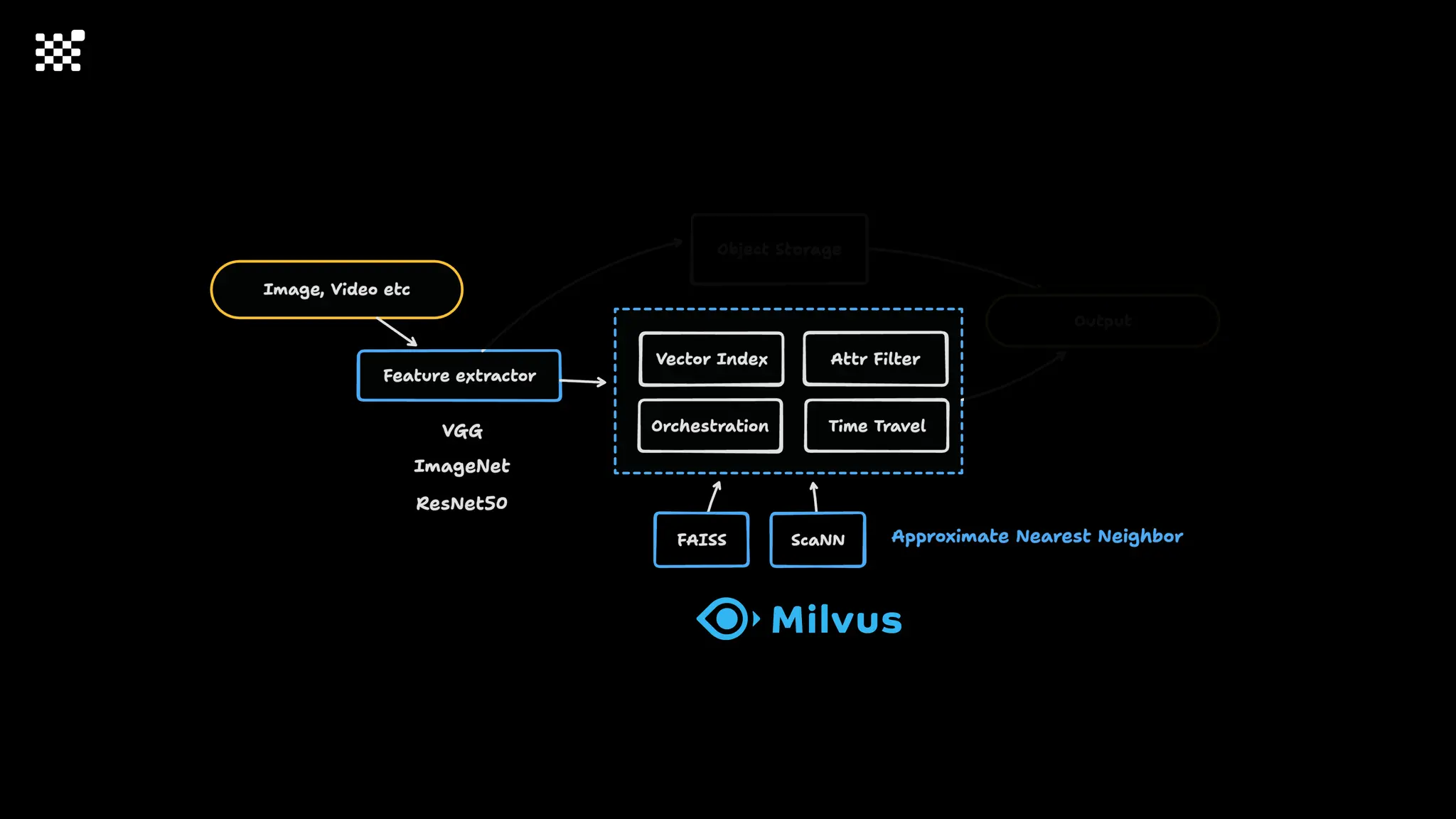
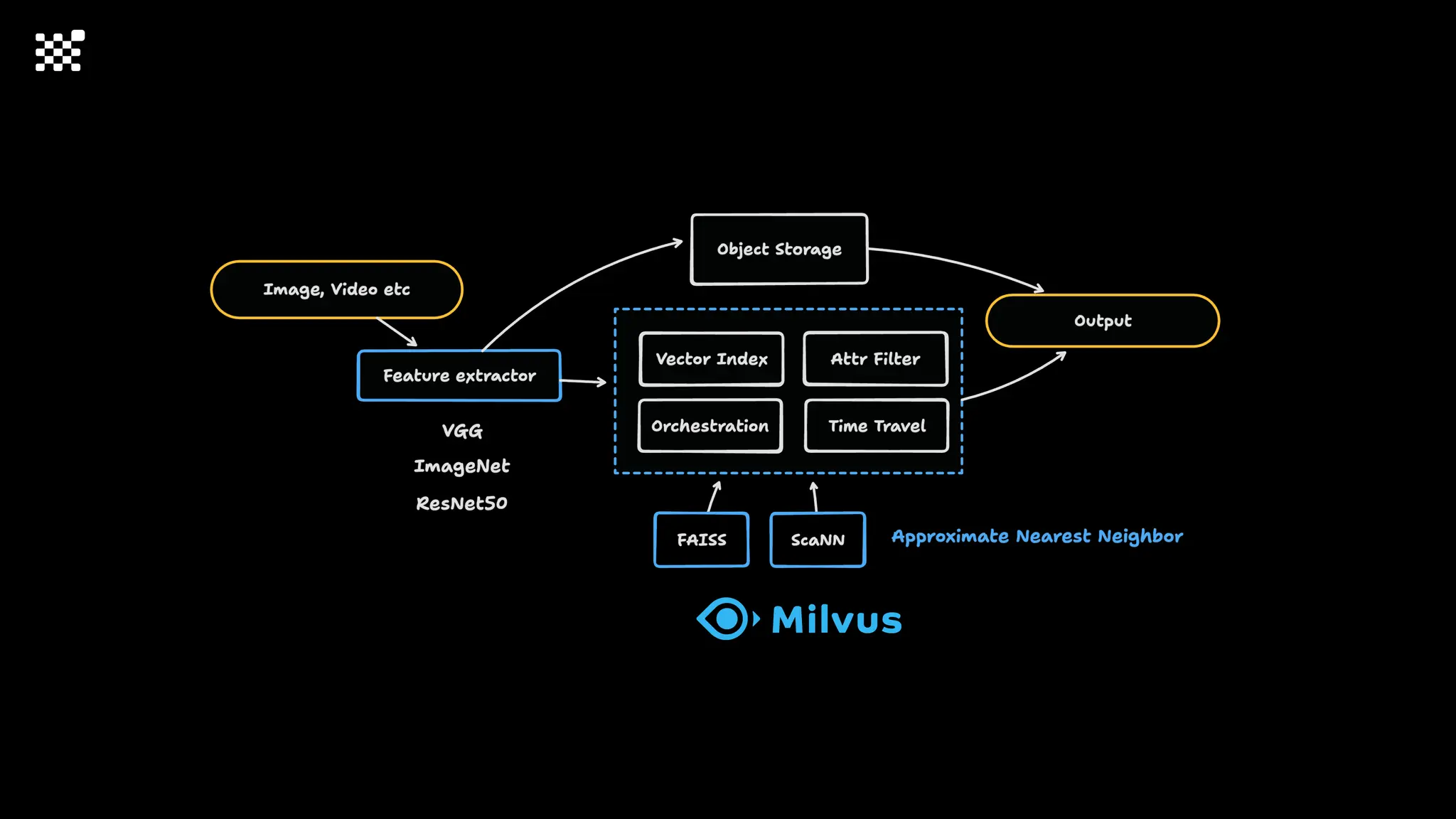
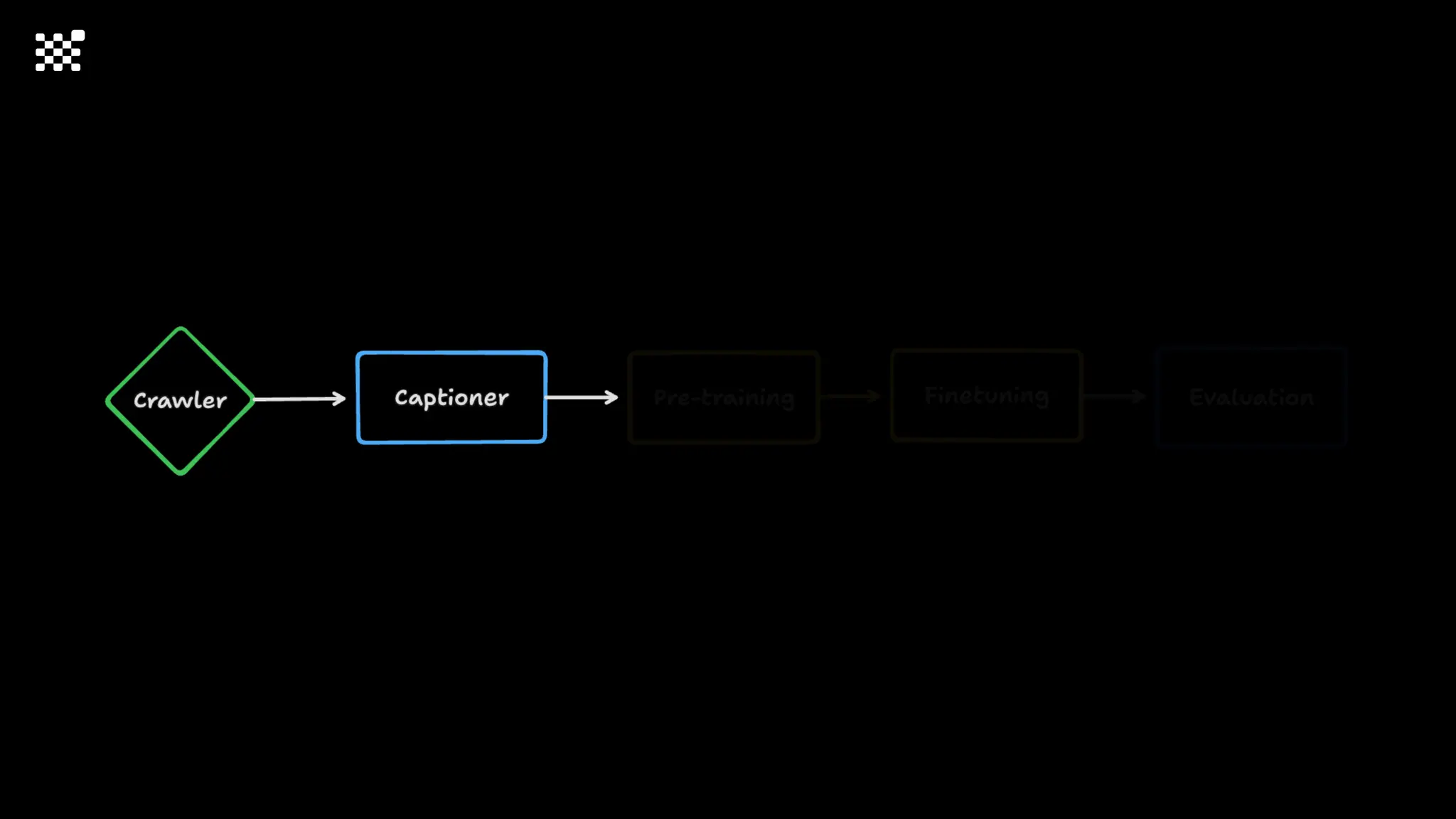
3개월 전부터 Diffusion 모델을 zero부터 학습하는 프로젝트를 시작했습니다. 매 실험마다 천만원 이상의 GPU를 쓰는 경험을 몇 년만에 했기 때문에, 큰 스케일의 학습 과정이 활발하게 공유되고 있는 LLM 논문을 많이 참고하며 실험을 해 왔습니다. LLM에 많은 관심이 쏠린 지금, Large-scale diffusion model 학습은 - 시각적이기 때문에 global scale이 용이하고 - 시장에 충분한 기회가 있으나 관심이 적고 - 큰 모델 학습에 관련된 경험이 거의 없기 때문에 그 과정에서 수많은 엔지니어링 문제를 푸는 것이 도전적이고 즐거운 것 같습니다! 저희와 함께 Domain-specific 지식으로 전문가가 쓸 수 있는 fine-grained 이미지 생성 모델을 만들고 싶으신 분은 언제든 편하게 연락주세요! SHIFT UP AI Labs: https://bit.ly/shiftup-ai * 이미지 생성 모델에 대한 Discussion이나 저희 팀에 관심이 있는 분이 계신 곳이라면 언제든 가서 Talk을 할 의향이 있으니 편하게 연락주세요!





![[코세나, kosena] 생성AI 프로젝트와 사례](https://cdn.slidesharecdn.com/ss_thumbnails/ai-240212104807-42c291b6-thumbnail.jpg?width=640&height=640&fit=bounds)





![신입 개발자 생활백서 [개정판]](https://cdn.slidesharecdn.com/ss_thumbnails/random-170208062532-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]네이버 검색 사용자를 만족시켜라! 의도파악과 의미검색](https://cdn.slidesharecdn.com/ss_thumbnails/216-171017052320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)

![[180718] ML 분야 유학 및 취업 준비 설명회 @SNU](https://cdn.slidesharecdn.com/ss_thumbnails/mlpresentation180718ttf-180720005850-thumbnail.jpg?width=640&height=640&fit=bounds)

![[IGC 2017] 펄어비스 민경인 - Mmorpg를 위한 voxel 기반 네비게이션 라이브러리 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/mmorpgvoxel-170905061528-thumbnail.jpg?width=640&height=640&fit=bounds)





![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)















![[RLKorea] Unity ML-agents 발표](https://cdn.slidesharecdn.com/ss_thumbnails/rlkoreaml-agents-190302111135-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NDC2016] 신경망은컨텐츠자동생성의꿈을꾸는가](https://cdn.slidesharecdn.com/ss_thumbnails/random-160427135746-thumbnail.jpg?width=640&height=640&fit=bounds)

![[AWS Innovate 온라인 컨퍼런스] 수백만 사용자 대상 기계 학습 서비스를 위한 확장 비법 - 윤석찬, AWS 테크 에반젤리스트](https://cdn.slidesharecdn.com/ss_thumbnails/awsinnovateonlineconferenceaimltrack1session1channyyun-200319071657-thumbnail.jpg?width=640&height=640&fit=bounds)

![Random Thoughts on Paper Implementations [KAIST 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/kaist2018-180426031539-thumbnail.jpg?width=640&height=640&fit=bounds)










